mirror of
https://github.com/BerriAI/litellm.git
synced 2025-04-25 02:34:29 +00:00
trying to add docs
This commit is contained in:
parent
d400bccb15
commit
38446a1dd1
834 changed files with 0 additions and 161273 deletions
BIN
.DS_Store
vendored
BIN
.DS_Store
vendored
Binary file not shown.
BIN
docs/.DS_Store
vendored
Normal file
BIN
docs/.DS_Store
vendored
Normal file
Binary file not shown.
|
|
@ -1,64 +0,0 @@
|
|||
|
||||
[comment: Please, a reference example here "docs/integrations/arxiv.md"]::
|
||||
[comment: Use this template to create a new .md file in "docs/integrations/"]::
|
||||
|
||||
# Title_REPLACE_ME
|
||||
|
||||
[comment: Only one Tile/H1 is allowed!]::
|
||||
|
||||
>
|
||||
|
||||
[comment: Description: After reading this description, a reader should decide if this integration is good enough to try/follow reading OR]::
|
||||
[comment: go to read the next integration doc. ]::
|
||||
[comment: Description should include a link to the source for follow reading.]::
|
||||
|
||||
## Installation and Setup
|
||||
|
||||
[comment: Installation and Setup: All necessary additional package installations and set ups for Tokens, etc]::
|
||||
|
||||
```bash
|
||||
pip install package_name_REPLACE_ME
|
||||
```
|
||||
|
||||
[comment: OR this text:]::
|
||||
There isn't any special setup for it.
|
||||
|
||||
|
||||
[comment: The next H2/## sections with names of the integration modules, like "LLM", "Text Embedding Models", etc]::
|
||||
[comment: see "Modules" in the "index.html" page]::
|
||||
[comment: Each H2 section should include a link to an example(s) and a python code with import of the integration class]::
|
||||
[comment: Below are several example sections. Remove all unnecessary sections. Add all necessary sections not provided here.]::
|
||||
|
||||
## LLM
|
||||
|
||||
See a [usage example](/docs/integrations/llms/INCLUDE_REAL_NAME).
|
||||
|
||||
```python
|
||||
from langchain.llms import integration_class_REPLACE_ME
|
||||
```
|
||||
|
||||
|
||||
## Text Embedding Models
|
||||
|
||||
See a [usage example](/docs/integrations/text_embedding/INCLUDE_REAL_NAME)
|
||||
|
||||
```python
|
||||
from langchain.embeddings import integration_class_REPLACE_ME
|
||||
```
|
||||
|
||||
|
||||
## Chat Models
|
||||
|
||||
See a [usage example](/docs/integrations/chat/INCLUDE_REAL_NAME)
|
||||
|
||||
```python
|
||||
from langchain.chat_models import integration_class_REPLACE_ME
|
||||
```
|
||||
|
||||
## Document Loader
|
||||
|
||||
See a [usage example](/docs/integrations/document_loaders/INCLUDE_REAL_NAME).
|
||||
|
||||
```python
|
||||
from langchain.document_loaders import integration_class_REPLACE_ME
|
||||
```
|
||||
|
|
@ -1,125 +0,0 @@
|
|||
# Tutorials
|
||||
|
||||
Below are links to video tutorials and courses on LangChain. For written guides on common use cases for LangChain, check out the [use cases guides](/docs/use_cases).
|
||||
|
||||
⛓ icon marks a new addition [last update 2023-07-05]
|
||||
|
||||
---------------------
|
||||
|
||||
### DeepLearning.AI courses
|
||||
by [Harrison Chase](https://github.com/hwchase17) and [Andrew Ng](https://en.wikipedia.org/wiki/Andrew_Ng)
|
||||
- [LangChain for LLM Application Development](https://learn.deeplearning.ai/langchain)
|
||||
- ⛓ [LangChain Chat with Your Data](https://learn.deeplearning.ai/langchain-chat-with-your-data)
|
||||
|
||||
### Handbook
|
||||
[LangChain AI Handbook](https://www.pinecone.io/learn/langchain/) By **James Briggs** and **Francisco Ingham**
|
||||
|
||||
### Short Tutorials
|
||||
[LangChain Crash Course - Build apps with language models](https://youtu.be/LbT1yp6quS8) by [Patrick Loeber](https://www.youtube.com/@patloeber)
|
||||
|
||||
[LangChain Crash Course: Build an AutoGPT app in 25 minutes](https://youtu.be/MlK6SIjcjE8) by [Nicholas Renotte](https://www.youtube.com/@NicholasRenotte)
|
||||
|
||||
[LangChain Explained in 13 Minutes | QuickStart Tutorial for Beginners](https://youtu.be/aywZrzNaKjs) by [Rabbitmetrics](https://www.youtube.com/@rabbitmetrics)
|
||||
|
||||
|
||||
## Tutorials
|
||||
|
||||
### [LangChain for Gen AI and LLMs](https://www.youtube.com/playlist?list=PLIUOU7oqGTLieV9uTIFMm6_4PXg-hlN6F) by [James Briggs](https://www.youtube.com/@jamesbriggs)
|
||||
- #1 [Getting Started with `GPT-3` vs. Open Source LLMs](https://youtu.be/nE2skSRWTTs)
|
||||
- #2 [Prompt Templates for `GPT 3.5` and other LLMs](https://youtu.be/RflBcK0oDH0)
|
||||
- #3 [LLM Chains using `GPT 3.5` and other LLMs](https://youtu.be/S8j9Tk0lZHU)
|
||||
- [LangChain Data Loaders, Tokenizers, Chunking, and Datasets - Data Prep 101](https://youtu.be/eqOfr4AGLk8)
|
||||
- #4 [Chatbot Memory for `Chat-GPT`, `Davinci` + other LLMs](https://youtu.be/X05uK0TZozM)
|
||||
- #5 [Chat with OpenAI in LangChain](https://youtu.be/CnAgB3A5OlU)
|
||||
- #6 [Fixing LLM Hallucinations with Retrieval Augmentation in LangChain](https://youtu.be/kvdVduIJsc8)
|
||||
- #7 [LangChain Agents Deep Dive with `GPT 3.5`](https://youtu.be/jSP-gSEyVeI)
|
||||
- #8 [Create Custom Tools for Chatbots in LangChain](https://youtu.be/q-HNphrWsDE)
|
||||
- #9 [Build Conversational Agents with Vector DBs](https://youtu.be/H6bCqqw9xyI)
|
||||
- [Using NEW `MPT-7B` in Hugging Face and LangChain](https://youtu.be/DXpk9K7DgMo)
|
||||
- ⛓ [`MPT-30B` Chatbot with LangChain](https://youtu.be/pnem-EhT6VI)
|
||||
|
||||
|
||||
### [LangChain 101](https://www.youtube.com/playlist?list=PLqZXAkvF1bPNQER9mLmDbntNfSpzdDIU5) by [Greg Kamradt (Data Indy)](https://www.youtube.com/@DataIndependent)
|
||||
- [What Is LangChain? - LangChain + `ChatGPT` Overview](https://youtu.be/_v_fgW2SkkQ)
|
||||
- [Quickstart Guide](https://youtu.be/kYRB-vJFy38)
|
||||
- [Beginner Guide To 7 Essential Concepts](https://youtu.be/2xxziIWmaSA)
|
||||
- [Beginner Guide To 9 Use Cases](https://youtu.be/vGP4pQdCocw)
|
||||
- [Agents Overview + Google Searches](https://youtu.be/Jq9Sf68ozk0)
|
||||
- [`OpenAI` + `Wolfram Alpha`](https://youtu.be/UijbzCIJ99g)
|
||||
- [Ask Questions On Your Custom (or Private) Files](https://youtu.be/EnT-ZTrcPrg)
|
||||
- [Connect `Google Drive Files` To `OpenAI`](https://youtu.be/IqqHqDcXLww)
|
||||
- [`YouTube Transcripts` + `OpenAI`](https://youtu.be/pNcQ5XXMgH4)
|
||||
- [Question A 300 Page Book (w/ `OpenAI` + `Pinecone`)](https://youtu.be/h0DHDp1FbmQ)
|
||||
- [Workaround `OpenAI's` Token Limit With Chain Types](https://youtu.be/f9_BWhCI4Zo)
|
||||
- [Build Your Own OpenAI + LangChain Web App in 23 Minutes](https://youtu.be/U_eV8wfMkXU)
|
||||
- [Working With The New `ChatGPT API`](https://youtu.be/e9P7FLi5Zy8)
|
||||
- [OpenAI + LangChain Wrote Me 100 Custom Sales Emails](https://youtu.be/y1pyAQM-3Bo)
|
||||
- [Structured Output From `OpenAI` (Clean Dirty Data)](https://youtu.be/KwAXfey-xQk)
|
||||
- [Connect `OpenAI` To +5,000 Tools (LangChain + `Zapier`)](https://youtu.be/7tNm0yiDigU)
|
||||
- [Use LLMs To Extract Data From Text (Expert Mode)](https://youtu.be/xZzvwR9jdPA)
|
||||
- [Extract Insights From Interview Transcripts Using LLMs](https://youtu.be/shkMOHwJ4SM)
|
||||
- [5 Levels Of LLM Summarizing: Novice to Expert](https://youtu.be/qaPMdcCqtWk)
|
||||
- [Control Tone & Writing Style Of Your LLM Output](https://youtu.be/miBG-a3FuhU)
|
||||
- [Build Your Own `AI Twitter Bot` Using LLMs](https://youtu.be/yLWLDjT01q8)
|
||||
- [ChatGPT made my interview questions for me (`Streamlit` + LangChain)](https://youtu.be/zvoAMx0WKkw)
|
||||
- [Function Calling via ChatGPT API - First Look With LangChain](https://youtu.be/0-zlUy7VUjg)
|
||||
- ⛓ [Extract Topics From Video/Audio With LLMs (Topic Modeling w/ LangChain)](https://youtu.be/pEkxRQFNAs4)
|
||||
|
||||
|
||||
### [LangChain How to and guides](https://www.youtube.com/playlist?list=PL8motc6AQftk1Bs42EW45kwYbyJ4jOdiZ) by [Sam Witteveen](https://www.youtube.com/@samwitteveenai)
|
||||
- [LangChain Basics - LLMs & PromptTemplates with Colab](https://youtu.be/J_0qvRt4LNk)
|
||||
- [LangChain Basics - Tools and Chains](https://youtu.be/hI2BY7yl_Ac)
|
||||
- [`ChatGPT API` Announcement & Code Walkthrough with LangChain](https://youtu.be/phHqvLHCwH4)
|
||||
- [Conversations with Memory (explanation & code walkthrough)](https://youtu.be/X550Zbz_ROE)
|
||||
- [Chat with `Flan20B`](https://youtu.be/VW5LBavIfY4)
|
||||
- [Using `Hugging Face Models` locally (code walkthrough)](https://youtu.be/Kn7SX2Mx_Jk)
|
||||
- [`PAL` : Program-aided Language Models with LangChain code](https://youtu.be/dy7-LvDu-3s)
|
||||
- [Building a Summarization System with LangChain and `GPT-3` - Part 1](https://youtu.be/LNq_2s_H01Y)
|
||||
- [Building a Summarization System with LangChain and `GPT-3` - Part 2](https://youtu.be/d-yeHDLgKHw)
|
||||
- [Microsoft's `Visual ChatGPT` using LangChain](https://youtu.be/7YEiEyfPF5U)
|
||||
- [LangChain Agents - Joining Tools and Chains with Decisions](https://youtu.be/ziu87EXZVUE)
|
||||
- [Comparing LLMs with LangChain](https://youtu.be/rFNG0MIEuW0)
|
||||
- [Using `Constitutional AI` in LangChain](https://youtu.be/uoVqNFDwpX4)
|
||||
- [Talking to `Alpaca` with LangChain - Creating an Alpaca Chatbot](https://youtu.be/v6sF8Ed3nTE)
|
||||
- [Talk to your `CSV` & `Excel` with LangChain](https://youtu.be/xQ3mZhw69bc)
|
||||
- [`BabyAGI`: Discover the Power of Task-Driven Autonomous Agents!](https://youtu.be/QBcDLSE2ERA)
|
||||
- [Improve your `BabyAGI` with LangChain](https://youtu.be/DRgPyOXZ-oE)
|
||||
- [Master `PDF` Chat with LangChain - Your essential guide to queries on documents](https://youtu.be/ZzgUqFtxgXI)
|
||||
- [Using LangChain with `DuckDuckGO` `Wikipedia` & `PythonREPL` Tools](https://youtu.be/KerHlb8nuVc)
|
||||
- [Building Custom Tools and Agents with LangChain (gpt-3.5-turbo)](https://youtu.be/biS8G8x8DdA)
|
||||
- [LangChain Retrieval QA Over Multiple Files with `ChromaDB`](https://youtu.be/3yPBVii7Ct0)
|
||||
- [LangChain Retrieval QA with Instructor Embeddings & `ChromaDB` for PDFs](https://youtu.be/cFCGUjc33aU)
|
||||
- [LangChain + Retrieval Local LLMs for Retrieval QA - No OpenAI!!!](https://youtu.be/9ISVjh8mdlA)
|
||||
- [`Camel` + LangChain for Synthetic Data & Market Research](https://youtu.be/GldMMK6-_-g)
|
||||
- [Information Extraction with LangChain & `Kor`](https://youtu.be/SW1ZdqH0rRQ)
|
||||
- [Converting a LangChain App from OpenAI to OpenSource](https://youtu.be/KUDn7bVyIfc)
|
||||
- [Using LangChain `Output Parsers` to get what you want out of LLMs](https://youtu.be/UVn2NroKQCw)
|
||||
- [Building a LangChain Custom Medical Agent with Memory](https://youtu.be/6UFtRwWnHws)
|
||||
- [Understanding `ReACT` with LangChain](https://youtu.be/Eug2clsLtFs)
|
||||
- [`OpenAI Functions` + LangChain : Building a Multi Tool Agent](https://youtu.be/4KXK6c6TVXQ)
|
||||
- [What can you do with 16K tokens in LangChain?](https://youtu.be/z2aCZBAtWXs)
|
||||
- [Tagging and Extraction - Classification using `OpenAI Functions`](https://youtu.be/a8hMgIcUEnE)
|
||||
- ⛓ [HOW to Make Conversational Form with LangChain](https://youtu.be/IT93On2LB5k)
|
||||
|
||||
|
||||
### [LangChain](https://www.youtube.com/playlist?list=PLVEEucA9MYhOu89CX8H3MBZqayTbcCTMr) by [Prompt Engineering](https://www.youtube.com/@engineerprompt)
|
||||
- [LangChain Crash Course — All You Need to Know to Build Powerful Apps with LLMs](https://youtu.be/5-fc4Tlgmro)
|
||||
- [Working with MULTIPLE `PDF` Files in LangChain: `ChatGPT` for your Data](https://youtu.be/s5LhRdh5fu4)
|
||||
- [`ChatGPT` for YOUR OWN `PDF` files with LangChain](https://youtu.be/TLf90ipMzfE)
|
||||
- [Talk to YOUR DATA without OpenAI APIs: LangChain](https://youtu.be/wrD-fZvT6UI)
|
||||
- [Langchain: PDF Chat App (GUI) | ChatGPT for Your PDF FILES](https://youtu.be/RIWbalZ7sTo)
|
||||
- [LangFlow: Build Chatbots without Writing Code](https://youtu.be/KJ-ux3hre4s)
|
||||
- [LangChain: Giving Memory to LLMs](https://youtu.be/dxO6pzlgJiY)
|
||||
- [BEST OPEN Alternative to `OPENAI's EMBEDDINGs` for Retrieval QA: LangChain](https://youtu.be/ogEalPMUCSY)
|
||||
|
||||
|
||||
### LangChain by [Chat with data](https://www.youtube.com/@chatwithdata)
|
||||
- [LangChain Beginner's Tutorial for `Typescript`/`Javascript`](https://youtu.be/bH722QgRlhQ)
|
||||
- [`GPT-4` Tutorial: How to Chat With Multiple `PDF` Files (~1000 pages of Tesla's 10-K Annual Reports)](https://youtu.be/Ix9WIZpArm0)
|
||||
- [`GPT-4` & LangChain Tutorial: How to Chat With A 56-Page `PDF` Document (w/`Pinecone`)](https://youtu.be/ih9PBGVVOO4)
|
||||
- [LangChain & Supabase Tutorial: How to Build a ChatGPT Chatbot For Your Website](https://youtu.be/R2FMzcsmQY8)
|
||||
- [LangChain Agents: Build Personal Assistants For Your Data (Q&A with Harrison Chase and Mayo Oshin)](https://youtu.be/gVkF8cwfBLI)
|
||||
|
||||
|
||||
---------------------
|
||||
⛓ icon marks a new addition [last update 2023-07-05]
|
||||
|
|
@ -1,115 +0,0 @@
|
|||
# YouTube videos
|
||||
|
||||
⛓ icon marks a new addition [last update 2023-06-20]
|
||||
|
||||
### [Official LangChain YouTube channel](https://www.youtube.com/@LangChain)
|
||||
|
||||
### Introduction to LangChain with Harrison Chase, creator of LangChain
|
||||
- [Building the Future with LLMs, `LangChain`, & `Pinecone`](https://youtu.be/nMniwlGyX-c) by [Pinecone](https://www.youtube.com/@pinecone-io)
|
||||
- [LangChain and Weaviate with Harrison Chase and Bob van Luijt - Weaviate Podcast #36](https://youtu.be/lhby7Ql7hbk) by [Weaviate • Vector Database](https://www.youtube.com/@Weaviate)
|
||||
- [LangChain Demo + Q&A with Harrison Chase](https://youtu.be/zaYTXQFR0_s?t=788) by [Full Stack Deep Learning](https://www.youtube.com/@FullStackDeepLearning)
|
||||
- [LangChain Agents: Build Personal Assistants For Your Data (Q&A with Harrison Chase and Mayo Oshin)](https://youtu.be/gVkF8cwfBLI) by [Chat with data](https://www.youtube.com/@chatwithdata)
|
||||
|
||||
## Videos (sorted by views)
|
||||
|
||||
- [Building AI LLM Apps with LangChain (and more?) - LIVE STREAM](https://www.youtube.com/live/M-2Cj_2fzWI?feature=share) by [Nicholas Renotte](https://www.youtube.com/@NicholasRenotte)
|
||||
- [First look - `ChatGPT` + `WolframAlpha` (`GPT-3.5` and Wolfram|Alpha via LangChain by James Weaver)](https://youtu.be/wYGbY811oMo) by [Dr Alan D. Thompson](https://www.youtube.com/@DrAlanDThompson)
|
||||
- [LangChain explained - The hottest new Python framework](https://youtu.be/RoR4XJw8wIc) by [AssemblyAI](https://www.youtube.com/@AssemblyAI)
|
||||
- [Chatbot with INFINITE MEMORY using `OpenAI` & `Pinecone` - `GPT-3`, `Embeddings`, `ADA`, `Vector DB`, `Semantic`](https://youtu.be/2xNzB7xq8nk) by [David Shapiro ~ AI](https://www.youtube.com/@DavidShapiroAutomator)
|
||||
- [LangChain for LLMs is... basically just an Ansible playbook](https://youtu.be/X51N9C-OhlE) by [David Shapiro ~ AI](https://www.youtube.com/@DavidShapiroAutomator)
|
||||
- [Build your own LLM Apps with LangChain & `GPT-Index`](https://youtu.be/-75p09zFUJY) by [1littlecoder](https://www.youtube.com/@1littlecoder)
|
||||
- [`BabyAGI` - New System of Autonomous AI Agents with LangChain](https://youtu.be/lg3kJvf1kXo) by [1littlecoder](https://www.youtube.com/@1littlecoder)
|
||||
- [Run `BabyAGI` with Langchain Agents (with Python Code)](https://youtu.be/WosPGHPObx8) by [1littlecoder](https://www.youtube.com/@1littlecoder)
|
||||
- [How to Use Langchain With `Zapier` | Write and Send Email with GPT-3 | OpenAI API Tutorial](https://youtu.be/p9v2-xEa9A0) by [StarMorph AI](https://www.youtube.com/@starmorph)
|
||||
- [Use Your Locally Stored Files To Get Response From GPT - `OpenAI` | Langchain | Python](https://youtu.be/NC1Ni9KS-rk) by [Shweta Lodha](https://www.youtube.com/@shweta-lodha)
|
||||
- [`Langchain JS` | How to Use GPT-3, GPT-4 to Reference your own Data | `OpenAI Embeddings` Intro](https://youtu.be/veV2I-NEjaM) by [StarMorph AI](https://www.youtube.com/@starmorph)
|
||||
- [The easiest way to work with large language models | Learn LangChain in 10min](https://youtu.be/kmbS6FDQh7c) by [Sophia Yang](https://www.youtube.com/@SophiaYangDS)
|
||||
- [4 Autonomous AI Agents: “Westworld” simulation `BabyAGI`, `AutoGPT`, `Camel`, `LangChain`](https://youtu.be/yWbnH6inT_U) by [Sophia Yang](https://www.youtube.com/@SophiaYangDS)
|
||||
- [AI CAN SEARCH THE INTERNET? Langchain Agents + OpenAI ChatGPT](https://youtu.be/J-GL0htqda8) by [tylerwhatsgood](https://www.youtube.com/@tylerwhatsgood)
|
||||
- [Query Your Data with GPT-4 | Embeddings, Vector Databases | Langchain JS Knowledgebase](https://youtu.be/jRnUPUTkZmU) by [StarMorph AI](https://www.youtube.com/@starmorph)
|
||||
- [`Weaviate` + LangChain for LLM apps presented by Erika Cardenas](https://youtu.be/7AGj4Td5Lgw) by [`Weaviate` • Vector Database](https://www.youtube.com/@Weaviate)
|
||||
- [Langchain Overview — How to Use Langchain & `ChatGPT`](https://youtu.be/oYVYIq0lOtI) by [Python In Office](https://www.youtube.com/@pythoninoffice6568)
|
||||
- [Langchain Overview - How to Use Langchain & `ChatGPT`](https://youtu.be/oYVYIq0lOtI) by [Python In Office](https://www.youtube.com/@pythoninoffice6568)
|
||||
- [LangChain Tutorials](https://www.youtube.com/watch?v=FuqdVNB_8c0&list=PL9V0lbeJ69brU-ojMpU1Y7Ic58Tap0Cw6) by [Edrick](https://www.youtube.com/@edrickdch):
|
||||
- [LangChain, Chroma DB, OpenAI Beginner Guide | ChatGPT with your PDF](https://youtu.be/FuqdVNB_8c0)
|
||||
- [LangChain 101: The Complete Beginner's Guide](https://youtu.be/P3MAbZ2eMUI)
|
||||
- [Custom langchain Agent & Tools with memory. Turn any `Python function` into langchain tool with Gpt 3](https://youtu.be/NIG8lXk0ULg) by [echohive](https://www.youtube.com/@echohive)
|
||||
- [LangChain: Run Language Models Locally - `Hugging Face Models`](https://youtu.be/Xxxuw4_iCzw) by [Prompt Engineering](https://www.youtube.com/@engineerprompt)
|
||||
- [`ChatGPT` with any `YouTube` video using langchain and `chromadb`](https://youtu.be/TQZfB2bzVwU) by [echohive](https://www.youtube.com/@echohive)
|
||||
- [How to Talk to a `PDF` using LangChain and `ChatGPT`](https://youtu.be/v2i1YDtrIwk) by [Automata Learning Lab](https://www.youtube.com/@automatalearninglab)
|
||||
- [Langchain Document Loaders Part 1: Unstructured Files](https://youtu.be/O5C0wfsen98) by [Merk](https://www.youtube.com/@merksworld)
|
||||
- [LangChain - Prompt Templates (what all the best prompt engineers use)](https://youtu.be/1aRu8b0XNOQ) by [Nick Daigler](https://www.youtube.com/@nick_daigs)
|
||||
- [LangChain. Crear aplicaciones Python impulsadas por GPT](https://youtu.be/DkW_rDndts8) by [Jesús Conde](https://www.youtube.com/@0utKast)
|
||||
- [Easiest Way to Use GPT In Your Products | LangChain Basics Tutorial](https://youtu.be/fLy0VenZyGc) by [Rachel Woods](https://www.youtube.com/@therachelwoods)
|
||||
- [`BabyAGI` + `GPT-4` Langchain Agent with Internet Access](https://youtu.be/wx1z_hs5P6E) by [tylerwhatsgood](https://www.youtube.com/@tylerwhatsgood)
|
||||
- [Learning LLM Agents. How does it actually work? LangChain, AutoGPT & OpenAI](https://youtu.be/mb_YAABSplk) by [Arnoldas Kemeklis](https://www.youtube.com/@processusAI)
|
||||
- [Get Started with LangChain in `Node.js`](https://youtu.be/Wxx1KUWJFv4) by [Developers Digest](https://www.youtube.com/@DevelopersDigest)
|
||||
- [LangChain + `OpenAI` tutorial: Building a Q&A system w/ own text data](https://youtu.be/DYOU_Z0hAwo) by [Samuel Chan](https://www.youtube.com/@SamuelChan)
|
||||
- [Langchain + `Zapier` Agent](https://youtu.be/yribLAb-pxA) by [Merk](https://www.youtube.com/@merksworld)
|
||||
- [Connecting the Internet with `ChatGPT` (LLMs) using Langchain And Answers Your Questions](https://youtu.be/9Y0TBC63yZg) by [Kamalraj M M](https://www.youtube.com/@insightbuilder)
|
||||
- [Build More Powerful LLM Applications for Business’s with LangChain (Beginners Guide)](https://youtu.be/sp3-WLKEcBg) by[ No Code Blackbox](https://www.youtube.com/@nocodeblackbox)
|
||||
- [LangFlow LLM Agent Demo for 🦜🔗LangChain](https://youtu.be/zJxDHaWt-6o) by [Cobus Greyling](https://www.youtube.com/@CobusGreylingZA)
|
||||
- [Chatbot Factory: Streamline Python Chatbot Creation with LLMs and Langchain](https://youtu.be/eYer3uzrcuM) by [Finxter](https://www.youtube.com/@CobusGreylingZA)
|
||||
- [LangChain Tutorial - ChatGPT mit eigenen Daten](https://youtu.be/0XDLyY90E2c) by [Coding Crashkurse](https://www.youtube.com/@codingcrashkurse6429)
|
||||
- [Chat with a `CSV` | LangChain Agents Tutorial (Beginners)](https://youtu.be/tjeti5vXWOU) by [GoDataProf](https://www.youtube.com/@godataprof)
|
||||
- [Introdução ao Langchain - #Cortes - Live DataHackers](https://youtu.be/fw8y5VRei5Y) by [Prof. João Gabriel Lima](https://www.youtube.com/@profjoaogabriellima)
|
||||
- [LangChain: Level up `ChatGPT` !? | LangChain Tutorial Part 1](https://youtu.be/vxUGx8aZpDE) by [Code Affinity](https://www.youtube.com/@codeaffinitydev)
|
||||
- [KI schreibt krasses Youtube Skript 😲😳 | LangChain Tutorial Deutsch](https://youtu.be/QpTiXyK1jus) by [SimpleKI](https://www.youtube.com/@simpleki)
|
||||
- [Chat with Audio: Langchain, `Chroma DB`, OpenAI, and `Assembly AI`](https://youtu.be/Kjy7cx1r75g) by [AI Anytime](https://www.youtube.com/@AIAnytime)
|
||||
- [QA over documents with Auto vector index selection with Langchain router chains](https://youtu.be/9G05qybShv8) by [echohive](https://www.youtube.com/@echohive)
|
||||
- [Build your own custom LLM application with `Bubble.io` & Langchain (No Code & Beginner friendly)](https://youtu.be/O7NhQGu1m6c) by [No Code Blackbox](https://www.youtube.com/@nocodeblackbox)
|
||||
- [Simple App to Question Your Docs: Leveraging `Streamlit`, `Hugging Face Spaces`, LangChain, and `Claude`!](https://youtu.be/X4YbNECRr7o) by [Chris Alexiuk](https://www.youtube.com/@chrisalexiuk)
|
||||
- [LANGCHAIN AI- `ConstitutionalChainAI` + Databutton AI ASSISTANT Web App](https://youtu.be/5zIU6_rdJCU) by [Avra](https://www.youtube.com/@Avra_b)
|
||||
- [LANGCHAIN AI AUTONOMOUS AGENT WEB APP - 👶 `BABY AGI` 🤖 with EMAIL AUTOMATION using `DATABUTTON`](https://youtu.be/cvAwOGfeHgw) by [Avra](https://www.youtube.com/@Avra_b)
|
||||
- [The Future of Data Analysis: Using A.I. Models in Data Analysis (LangChain)](https://youtu.be/v_LIcVyg5dk) by [Absent Data](https://www.youtube.com/@absentdata)
|
||||
- [Memory in LangChain | Deep dive (python)](https://youtu.be/70lqvTFh_Yg) by [Eden Marco](https://www.youtube.com/@EdenMarco)
|
||||
- [9 LangChain UseCases | Beginner's Guide | 2023](https://youtu.be/zS8_qosHNMw) by [Data Science Basics](https://www.youtube.com/@datasciencebasics)
|
||||
- [Use Large Language Models in Jupyter Notebook | LangChain | Agents & Indexes](https://youtu.be/JSe11L1a_QQ) by [Abhinaw Tiwari](https://www.youtube.com/@AbhinawTiwariAT)
|
||||
- [How to Talk to Your Langchain Agent | `11 Labs` + `Whisper`](https://youtu.be/N4k459Zw2PU) by [VRSEN](https://www.youtube.com/@vrsen)
|
||||
- [LangChain Deep Dive: 5 FUN AI App Ideas To Build Quickly and Easily](https://youtu.be/mPYEPzLkeks) by [James NoCode](https://www.youtube.com/@jamesnocode)
|
||||
- [BEST OPEN Alternative to OPENAI's EMBEDDINGs for Retrieval QA: LangChain](https://youtu.be/ogEalPMUCSY) by [Prompt Engineering](https://www.youtube.com/@engineerprompt)
|
||||
- [LangChain 101: Models](https://youtu.be/T6c_XsyaNSQ) by [Mckay Wrigley](https://www.youtube.com/@realmckaywrigley)
|
||||
- [LangChain with JavaScript Tutorial #1 | Setup & Using LLMs](https://youtu.be/W3AoeMrg27o) by [Leon van Zyl](https://www.youtube.com/@leonvanzyl)
|
||||
- [LangChain Overview & Tutorial for Beginners: Build Powerful AI Apps Quickly & Easily (ZERO CODE)](https://youtu.be/iI84yym473Q) by [James NoCode](https://www.youtube.com/@jamesnocode)
|
||||
- [LangChain In Action: Real-World Use Case With Step-by-Step Tutorial](https://youtu.be/UO699Szp82M) by [Rabbitmetrics](https://www.youtube.com/@rabbitmetrics)
|
||||
- [Summarizing and Querying Multiple Papers with LangChain](https://youtu.be/p_MQRWH5Y6k) by [Automata Learning Lab](https://www.youtube.com/@automatalearninglab)
|
||||
- [Using Langchain (and `Replit`) through `Tana`, ask `Google`/`Wikipedia`/`Wolfram Alpha` to fill out a table](https://youtu.be/Webau9lEzoI) by [Stian Håklev](https://www.youtube.com/@StianHaklev)
|
||||
- [Langchain PDF App (GUI) | Create a ChatGPT For Your `PDF` in Python](https://youtu.be/wUAUdEw5oxM) by [Alejandro AO - Software & Ai](https://www.youtube.com/@alejandro_ao)
|
||||
- [Auto-GPT with LangChain 🔥 | Create Your Own Personal AI Assistant](https://youtu.be/imDfPmMKEjM) by [Data Science Basics](https://www.youtube.com/@datasciencebasics)
|
||||
- [Create Your OWN Slack AI Assistant with Python & LangChain](https://youtu.be/3jFXRNn2Bu8) by [Dave Ebbelaar](https://www.youtube.com/@daveebbelaar)
|
||||
- [How to Create LOCAL Chatbots with GPT4All and LangChain [Full Guide]](https://youtu.be/4p1Fojur8Zw) by [Liam Ottley](https://www.youtube.com/@LiamOttley)
|
||||
- [Build a `Multilingual PDF` Search App with LangChain, `Cohere` and `Bubble`](https://youtu.be/hOrtuumOrv8) by [Menlo Park Lab](https://www.youtube.com/@menloparklab)
|
||||
- [Building a LangChain Agent (code-free!) Using `Bubble` and `Flowise`](https://youtu.be/jDJIIVWTZDE) by [Menlo Park Lab](https://www.youtube.com/@menloparklab)
|
||||
- [Build a LangChain-based Semantic PDF Search App with No-Code Tools Bubble and Flowise](https://youtu.be/s33v5cIeqA4) by [Menlo Park Lab](https://www.youtube.com/@menloparklab)
|
||||
- [LangChain Memory Tutorial | Building a ChatGPT Clone in Python](https://youtu.be/Cwq91cj2Pnc) by [Alejandro AO - Software & Ai](https://www.youtube.com/@alejandro_ao)
|
||||
- [ChatGPT For Your DATA | Chat with Multiple Documents Using LangChain](https://youtu.be/TeDgIDqQmzs) by [Data Science Basics](https://www.youtube.com/@datasciencebasics)
|
||||
- [`Llama Index`: Chat with Documentation using URL Loader](https://youtu.be/XJRoDEctAwA) by [Merk](https://www.youtube.com/@merksworld)
|
||||
- [Using OpenAI, LangChain, and `Gradio` to Build Custom GenAI Applications](https://youtu.be/1MsmqMg3yUc) by [David Hundley](https://www.youtube.com/@dkhundley)
|
||||
- [LangChain, Chroma DB, OpenAI Beginner Guide | ChatGPT with your PDF](https://youtu.be/FuqdVNB_8c0)
|
||||
- ⛓ [Build AI chatbot with custom knowledge base using OpenAI API and GPT Index](https://youtu.be/vDZAZuaXf48) by [Irina Nik](https://www.youtube.com/@irina_nik)
|
||||
- ⛓ [Build Your Own Auto-GPT Apps with LangChain (Python Tutorial)](https://youtu.be/NYSWn1ipbgg) by [Dave Ebbelaar](https://www.youtube.com/@daveebbelaar)
|
||||
- ⛓ [Chat with Multiple `PDFs` | LangChain App Tutorial in Python (Free LLMs and Embeddings)](https://youtu.be/dXxQ0LR-3Hg) by [Alejandro AO - Software & Ai](https://www.youtube.com/@alejandro_ao)
|
||||
- ⛓ [Chat with a `CSV` | `LangChain Agents` Tutorial (Beginners)](https://youtu.be/tjeti5vXWOU) by [Alejandro AO - Software & Ai](https://www.youtube.com/@alejandro_ao)
|
||||
- ⛓ [Create Your Own ChatGPT with `PDF` Data in 5 Minutes (LangChain Tutorial)](https://youtu.be/au2WVVGUvc8) by [Liam Ottley](https://www.youtube.com/@LiamOttley)
|
||||
- ⛓ [Using ChatGPT with YOUR OWN Data. This is magical. (LangChain OpenAI API)](https://youtu.be/9AXP7tCI9PI) by [TechLead](https://www.youtube.com/@TechLead)
|
||||
- ⛓ [Build a Custom Chatbot with OpenAI: `GPT-Index` & LangChain | Step-by-Step Tutorial](https://youtu.be/FIDv6nc4CgU) by [Fabrikod](https://www.youtube.com/@fabrikod)
|
||||
- ⛓ [`Flowise` is an open source no-code UI visual tool to build 🦜🔗LangChain applications](https://youtu.be/CovAPtQPU0k) by [Cobus Greyling](https://www.youtube.com/@CobusGreylingZA)
|
||||
- ⛓ [LangChain & GPT 4 For Data Analysis: The `Pandas` Dataframe Agent](https://youtu.be/rFQ5Kmkd4jc) by [Rabbitmetrics](https://www.youtube.com/@rabbitmetrics)
|
||||
- ⛓ [`GirlfriendGPT` - AI girlfriend with LangChain](https://youtu.be/LiN3D1QZGQw) by [Toolfinder AI](https://www.youtube.com/@toolfinderai)
|
||||
- ⛓ [`PrivateGPT`: Chat to your FILES OFFLINE and FREE [Installation and Tutorial]](https://youtu.be/G7iLllmx4qc) by [Prompt Engineering](https://www.youtube.com/@engineerprompt)
|
||||
- ⛓ [How to build with Langchain 10x easier | ⛓️ LangFlow & `Flowise`](https://youtu.be/Ya1oGL7ZTvU) by [AI Jason](https://www.youtube.com/@AIJasonZ)
|
||||
- ⛓ [Getting Started With LangChain In 20 Minutes- Build Celebrity Search Application](https://youtu.be/_FpT1cwcSLg) by [Krish Naik](https://www.youtube.com/@krishnaik06)
|
||||
|
||||
|
||||
|
||||
### [Prompt Engineering and LangChain](https://www.youtube.com/watch?v=muXbPpG_ys4&list=PLEJK-H61Xlwzm5FYLDdKt_6yibO33zoMW) by [Venelin Valkov](https://www.youtube.com/@venelin_valkov)
|
||||
- [Getting Started with LangChain: Load Custom Data, Run OpenAI Models, Embeddings and `ChatGPT`](https://www.youtube.com/watch?v=muXbPpG_ys4)
|
||||
- [Loaders, Indexes & Vectorstores in LangChain: Question Answering on `PDF` files with `ChatGPT`](https://www.youtube.com/watch?v=FQnvfR8Dmr0)
|
||||
- [LangChain Models: `ChatGPT`, `Flan Alpaca`, `OpenAI Embeddings`, Prompt Templates & Streaming](https://www.youtube.com/watch?v=zy6LiK5F5-s)
|
||||
- [LangChain Chains: Use `ChatGPT` to Build Conversational Agents, Summaries and Q&A on Text With LLMs](https://www.youtube.com/watch?v=h1tJZQPcimM)
|
||||
- [Analyze Custom CSV Data with `GPT-4` using Langchain](https://www.youtube.com/watch?v=Ew3sGdX8at4)
|
||||
- [Build ChatGPT Chatbots with LangChain Memory: Understanding and Implementing Memory in Conversations](https://youtu.be/CyuUlf54wTs)
|
||||
|
||||
|
||||
---------------------
|
||||
⛓ icon marks a new addition [last update 2023-06-20]
|
||||
|
|
@ -1,265 +0,0 @@
|
|||
# Dependents
|
||||
|
||||
Dependents stats for `hwchase17/langchain`
|
||||
|
||||
[](https://github.com/hwchase17/langchain/network/dependents)
|
||||
[&message=244&color=informational&logo=slickpic)](https://github.com/hwchase17/langchain/network/dependents)
|
||||
[&message=9697&color=informational&logo=slickpic)](https://github.com/hwchase17/langchain/network/dependents)
|
||||
[&message=19827&color=informational&logo=slickpic)](https://github.com/hwchase17/langchain/network/dependents)
|
||||
|
||||
|
||||
[update: 2023-07-07; only dependent repositories with Stars > 100]
|
||||
|
||||
|
||||
| Repository | Stars |
|
||||
| :-------- | -----: |
|
||||
|[openai/openai-cookbook](https://github.com/openai/openai-cookbook) | 41047 |
|
||||
|[LAION-AI/Open-Assistant](https://github.com/LAION-AI/Open-Assistant) | 33983 |
|
||||
|[microsoft/TaskMatrix](https://github.com/microsoft/TaskMatrix) | 33375 |
|
||||
|[imartinez/privateGPT](https://github.com/imartinez/privateGPT) | 31114 |
|
||||
|[hpcaitech/ColossalAI](https://github.com/hpcaitech/ColossalAI) | 30369 |
|
||||
|[reworkd/AgentGPT](https://github.com/reworkd/AgentGPT) | 24116 |
|
||||
|[OpenBB-finance/OpenBBTerminal](https://github.com/OpenBB-finance/OpenBBTerminal) | 22565 |
|
||||
|[openai/chatgpt-retrieval-plugin](https://github.com/openai/chatgpt-retrieval-plugin) | 18375 |
|
||||
|[jerryjliu/llama_index](https://github.com/jerryjliu/llama_index) | 17723 |
|
||||
|[mindsdb/mindsdb](https://github.com/mindsdb/mindsdb) | 16958 |
|
||||
|[mlflow/mlflow](https://github.com/mlflow/mlflow) | 14632 |
|
||||
|[GaiZhenbiao/ChuanhuChatGPT](https://github.com/GaiZhenbiao/ChuanhuChatGPT) | 11273 |
|
||||
|[openai/evals](https://github.com/openai/evals) | 10745 |
|
||||
|[databrickslabs/dolly](https://github.com/databrickslabs/dolly) | 10298 |
|
||||
|[imClumsyPanda/langchain-ChatGLM](https://github.com/imClumsyPanda/langchain-ChatGLM) | 9838 |
|
||||
|[logspace-ai/langflow](https://github.com/logspace-ai/langflow) | 9247 |
|
||||
|[AIGC-Audio/AudioGPT](https://github.com/AIGC-Audio/AudioGPT) | 8768 |
|
||||
|[PromtEngineer/localGPT](https://github.com/PromtEngineer/localGPT) | 8651 |
|
||||
|[StanGirard/quivr](https://github.com/StanGirard/quivr) | 8119 |
|
||||
|[go-skynet/LocalAI](https://github.com/go-skynet/LocalAI) | 7418 |
|
||||
|[gventuri/pandas-ai](https://github.com/gventuri/pandas-ai) | 7301 |
|
||||
|[PipedreamHQ/pipedream](https://github.com/PipedreamHQ/pipedream) | 6636 |
|
||||
|[arc53/DocsGPT](https://github.com/arc53/DocsGPT) | 5849 |
|
||||
|[e2b-dev/e2b](https://github.com/e2b-dev/e2b) | 5129 |
|
||||
|[langgenius/dify](https://github.com/langgenius/dify) | 4804 |
|
||||
|[serge-chat/serge](https://github.com/serge-chat/serge) | 4448 |
|
||||
|[csunny/DB-GPT](https://github.com/csunny/DB-GPT) | 4350 |
|
||||
|[wenda-LLM/wenda](https://github.com/wenda-LLM/wenda) | 4268 |
|
||||
|[zauberzeug/nicegui](https://github.com/zauberzeug/nicegui) | 4244 |
|
||||
|[intitni/CopilotForXcode](https://github.com/intitni/CopilotForXcode) | 4232 |
|
||||
|[GreyDGL/PentestGPT](https://github.com/GreyDGL/PentestGPT) | 4154 |
|
||||
|[madawei2699/myGPTReader](https://github.com/madawei2699/myGPTReader) | 4080 |
|
||||
|[zilliztech/GPTCache](https://github.com/zilliztech/GPTCache) | 3949 |
|
||||
|[gkamradt/langchain-tutorials](https://github.com/gkamradt/langchain-tutorials) | 3920 |
|
||||
|[bentoml/OpenLLM](https://github.com/bentoml/OpenLLM) | 3481 |
|
||||
|[MineDojo/Voyager](https://github.com/MineDojo/Voyager) | 3453 |
|
||||
|[mmabrouk/chatgpt-wrapper](https://github.com/mmabrouk/chatgpt-wrapper) | 3355 |
|
||||
|[postgresml/postgresml](https://github.com/postgresml/postgresml) | 3328 |
|
||||
|[marqo-ai/marqo](https://github.com/marqo-ai/marqo) | 3100 |
|
||||
|[kyegomez/tree-of-thoughts](https://github.com/kyegomez/tree-of-thoughts) | 3049 |
|
||||
|[PrefectHQ/marvin](https://github.com/PrefectHQ/marvin) | 2844 |
|
||||
|[project-baize/baize-chatbot](https://github.com/project-baize/baize-chatbot) | 2833 |
|
||||
|[h2oai/h2ogpt](https://github.com/h2oai/h2ogpt) | 2809 |
|
||||
|[hwchase17/chat-langchain](https://github.com/hwchase17/chat-langchain) | 2809 |
|
||||
|[whitead/paper-qa](https://github.com/whitead/paper-qa) | 2664 |
|
||||
|[Azure-Samples/azure-search-openai-demo](https://github.com/Azure-Samples/azure-search-openai-demo) | 2650 |
|
||||
|[OpenGVLab/InternGPT](https://github.com/OpenGVLab/InternGPT) | 2525 |
|
||||
|[GerevAI/gerev](https://github.com/GerevAI/gerev) | 2372 |
|
||||
|[ParisNeo/lollms-webui](https://github.com/ParisNeo/lollms-webui) | 2287 |
|
||||
|[OpenBMB/BMTools](https://github.com/OpenBMB/BMTools) | 2265 |
|
||||
|[SamurAIGPT/privateGPT](https://github.com/SamurAIGPT/privateGPT) | 2084 |
|
||||
|[Chainlit/chainlit](https://github.com/Chainlit/chainlit) | 1912 |
|
||||
|[Farama-Foundation/PettingZoo](https://github.com/Farama-Foundation/PettingZoo) | 1869 |
|
||||
|[OpenGVLab/Ask-Anything](https://github.com/OpenGVLab/Ask-Anything) | 1864 |
|
||||
|[IntelligenzaArtificiale/Free-Auto-GPT](https://github.com/IntelligenzaArtificiale/Free-Auto-GPT) | 1849 |
|
||||
|[Unstructured-IO/unstructured](https://github.com/Unstructured-IO/unstructured) | 1766 |
|
||||
|[yanqiangmiffy/Chinese-LangChain](https://github.com/yanqiangmiffy/Chinese-LangChain) | 1745 |
|
||||
|[NVIDIA/NeMo-Guardrails](https://github.com/NVIDIA/NeMo-Guardrails) | 1732 |
|
||||
|[hwchase17/notion-qa](https://github.com/hwchase17/notion-qa) | 1716 |
|
||||
|[paulpierre/RasaGPT](https://github.com/paulpierre/RasaGPT) | 1619 |
|
||||
|[pinterest/querybook](https://github.com/pinterest/querybook) | 1468 |
|
||||
|[vocodedev/vocode-python](https://github.com/vocodedev/vocode-python) | 1446 |
|
||||
|[thomas-yanxin/LangChain-ChatGLM-Webui](https://github.com/thomas-yanxin/LangChain-ChatGLM-Webui) | 1430 |
|
||||
|[Mintplex-Labs/anything-llm](https://github.com/Mintplex-Labs/anything-llm) | 1419 |
|
||||
|[Kav-K/GPTDiscord](https://github.com/Kav-K/GPTDiscord) | 1416 |
|
||||
|[lunasec-io/lunasec](https://github.com/lunasec-io/lunasec) | 1327 |
|
||||
|[psychic-api/psychic](https://github.com/psychic-api/psychic) | 1307 |
|
||||
|[jina-ai/thinkgpt](https://github.com/jina-ai/thinkgpt) | 1242 |
|
||||
|[agiresearch/OpenAGI](https://github.com/agiresearch/OpenAGI) | 1239 |
|
||||
|[ttengwang/Caption-Anything](https://github.com/ttengwang/Caption-Anything) | 1203 |
|
||||
|[jina-ai/dev-gpt](https://github.com/jina-ai/dev-gpt) | 1179 |
|
||||
|[keephq/keep](https://github.com/keephq/keep) | 1169 |
|
||||
|[greshake/llm-security](https://github.com/greshake/llm-security) | 1156 |
|
||||
|[richardyc/Chrome-GPT](https://github.com/richardyc/Chrome-GPT) | 1090 |
|
||||
|[jina-ai/langchain-serve](https://github.com/jina-ai/langchain-serve) | 1088 |
|
||||
|[mmz-001/knowledge_gpt](https://github.com/mmz-001/knowledge_gpt) | 1074 |
|
||||
|[juncongmoo/chatllama](https://github.com/juncongmoo/chatllama) | 1057 |
|
||||
|[noahshinn024/reflexion](https://github.com/noahshinn024/reflexion) | 1045 |
|
||||
|[visual-openllm/visual-openllm](https://github.com/visual-openllm/visual-openllm) | 1036 |
|
||||
|[101dotxyz/GPTeam](https://github.com/101dotxyz/GPTeam) | 999 |
|
||||
|[poe-platform/api-bot-tutorial](https://github.com/poe-platform/api-bot-tutorial) | 989 |
|
||||
|[irgolic/AutoPR](https://github.com/irgolic/AutoPR) | 974 |
|
||||
|[homanp/superagent](https://github.com/homanp/superagent) | 970 |
|
||||
|[microsoft/X-Decoder](https://github.com/microsoft/X-Decoder) | 941 |
|
||||
|[peterw/Chat-with-Github-Repo](https://github.com/peterw/Chat-with-Github-Repo) | 896 |
|
||||
|[SamurAIGPT/Camel-AutoGPT](https://github.com/SamurAIGPT/Camel-AutoGPT) | 856 |
|
||||
|[cirediatpl/FigmaChain](https://github.com/cirediatpl/FigmaChain) | 840 |
|
||||
|[chatarena/chatarena](https://github.com/chatarena/chatarena) | 829 |
|
||||
|[rlancemartin/auto-evaluator](https://github.com/rlancemartin/auto-evaluator) | 816 |
|
||||
|[seanpixel/Teenage-AGI](https://github.com/seanpixel/Teenage-AGI) | 816 |
|
||||
|[hashintel/hash](https://github.com/hashintel/hash) | 806 |
|
||||
|[corca-ai/EVAL](https://github.com/corca-ai/EVAL) | 790 |
|
||||
|[eyurtsev/kor](https://github.com/eyurtsev/kor) | 752 |
|
||||
|[cheshire-cat-ai/core](https://github.com/cheshire-cat-ai/core) | 713 |
|
||||
|[e-johnstonn/BriefGPT](https://github.com/e-johnstonn/BriefGPT) | 686 |
|
||||
|[run-llama/llama-lab](https://github.com/run-llama/llama-lab) | 685 |
|
||||
|[refuel-ai/autolabel](https://github.com/refuel-ai/autolabel) | 673 |
|
||||
|[griptape-ai/griptape](https://github.com/griptape-ai/griptape) | 617 |
|
||||
|[billxbf/ReWOO](https://github.com/billxbf/ReWOO) | 616 |
|
||||
|[Anil-matcha/ChatPDF](https://github.com/Anil-matcha/ChatPDF) | 609 |
|
||||
|[NimbleBoxAI/ChainFury](https://github.com/NimbleBoxAI/ChainFury) | 592 |
|
||||
|[getmetal/motorhead](https://github.com/getmetal/motorhead) | 581 |
|
||||
|[ajndkr/lanarky](https://github.com/ajndkr/lanarky) | 574 |
|
||||
|[namuan/dr-doc-search](https://github.com/namuan/dr-doc-search) | 572 |
|
||||
|[kreneskyp/ix](https://github.com/kreneskyp/ix) | 564 |
|
||||
|[akshata29/chatpdf](https://github.com/akshata29/chatpdf) | 540 |
|
||||
|[hwchase17/chat-your-data](https://github.com/hwchase17/chat-your-data) | 540 |
|
||||
|[whyiyhw/chatgpt-wechat](https://github.com/whyiyhw/chatgpt-wechat) | 537 |
|
||||
|[khoj-ai/khoj](https://github.com/khoj-ai/khoj) | 531 |
|
||||
|[SamurAIGPT/ChatGPT-Developer-Plugins](https://github.com/SamurAIGPT/ChatGPT-Developer-Plugins) | 528 |
|
||||
|[microsoft/PodcastCopilot](https://github.com/microsoft/PodcastCopilot) | 526 |
|
||||
|[ruoccofabrizio/azure-open-ai-embeddings-qna](https://github.com/ruoccofabrizio/azure-open-ai-embeddings-qna) | 515 |
|
||||
|[alexanderatallah/window.ai](https://github.com/alexanderatallah/window.ai) | 494 |
|
||||
|[StevenGrove/GPT4Tools](https://github.com/StevenGrove/GPT4Tools) | 483 |
|
||||
|[jina-ai/agentchain](https://github.com/jina-ai/agentchain) | 472 |
|
||||
|[mckaywrigley/repo-chat](https://github.com/mckaywrigley/repo-chat) | 465 |
|
||||
|[yeagerai/yeagerai-agent](https://github.com/yeagerai/yeagerai-agent) | 464 |
|
||||
|[langchain-ai/langchain-aiplugin](https://github.com/langchain-ai/langchain-aiplugin) | 464 |
|
||||
|[mpaepper/content-chatbot](https://github.com/mpaepper/content-chatbot) | 455 |
|
||||
|[michaelthwan/searchGPT](https://github.com/michaelthwan/searchGPT) | 455 |
|
||||
|[freddyaboulton/gradio-tools](https://github.com/freddyaboulton/gradio-tools) | 450 |
|
||||
|[amosjyng/langchain-visualizer](https://github.com/amosjyng/langchain-visualizer) | 446 |
|
||||
|[msoedov/langcorn](https://github.com/msoedov/langcorn) | 445 |
|
||||
|[plastic-labs/tutor-gpt](https://github.com/plastic-labs/tutor-gpt) | 426 |
|
||||
|[poe-platform/poe-protocol](https://github.com/poe-platform/poe-protocol) | 426 |
|
||||
|[jonra1993/fastapi-alembic-sqlmodel-async](https://github.com/jonra1993/fastapi-alembic-sqlmodel-async) | 418 |
|
||||
|[langchain-ai/auto-evaluator](https://github.com/langchain-ai/auto-evaluator) | 416 |
|
||||
|[steamship-core/steamship-langchain](https://github.com/steamship-core/steamship-langchain) | 401 |
|
||||
|[xuwenhao/geektime-ai-course](https://github.com/xuwenhao/geektime-ai-course) | 400 |
|
||||
|[continuum-llms/chatgpt-memory](https://github.com/continuum-llms/chatgpt-memory) | 386 |
|
||||
|[mtenenholtz/chat-twitter](https://github.com/mtenenholtz/chat-twitter) | 382 |
|
||||
|[explosion/spacy-llm](https://github.com/explosion/spacy-llm) | 368 |
|
||||
|[showlab/VLog](https://github.com/showlab/VLog) | 363 |
|
||||
|[yvann-hub/Robby-chatbot](https://github.com/yvann-hub/Robby-chatbot) | 363 |
|
||||
|[daodao97/chatdoc](https://github.com/daodao97/chatdoc) | 361 |
|
||||
|[opentensor/bittensor](https://github.com/opentensor/bittensor) | 360 |
|
||||
|[alejandro-ao/langchain-ask-pdf](https://github.com/alejandro-ao/langchain-ask-pdf) | 355 |
|
||||
|[logan-markewich/llama_index_starter_pack](https://github.com/logan-markewich/llama_index_starter_pack) | 351 |
|
||||
|[jupyterlab/jupyter-ai](https://github.com/jupyterlab/jupyter-ai) | 348 |
|
||||
|[alejandro-ao/ask-multiple-pdfs](https://github.com/alejandro-ao/ask-multiple-pdfs) | 321 |
|
||||
|[andylokandy/gpt-4-search](https://github.com/andylokandy/gpt-4-search) | 314 |
|
||||
|[mosaicml/examples](https://github.com/mosaicml/examples) | 313 |
|
||||
|[personoids/personoids-lite](https://github.com/personoids/personoids-lite) | 306 |
|
||||
|[itamargol/openai](https://github.com/itamargol/openai) | 304 |
|
||||
|[Anil-matcha/Website-to-Chatbot](https://github.com/Anil-matcha/Website-to-Chatbot) | 299 |
|
||||
|[momegas/megabots](https://github.com/momegas/megabots) | 299 |
|
||||
|[BlackHC/llm-strategy](https://github.com/BlackHC/llm-strategy) | 289 |
|
||||
|[daveebbelaar/langchain-experiments](https://github.com/daveebbelaar/langchain-experiments) | 283 |
|
||||
|[wandb/weave](https://github.com/wandb/weave) | 279 |
|
||||
|[Cheems-Seminar/grounded-segment-any-parts](https://github.com/Cheems-Seminar/grounded-segment-any-parts) | 273 |
|
||||
|[jerlendds/osintbuddy](https://github.com/jerlendds/osintbuddy) | 271 |
|
||||
|[OpenBMB/AgentVerse](https://github.com/OpenBMB/AgentVerse) | 270 |
|
||||
|[MagnivOrg/prompt-layer-library](https://github.com/MagnivOrg/prompt-layer-library) | 269 |
|
||||
|[sullivan-sean/chat-langchainjs](https://github.com/sullivan-sean/chat-langchainjs) | 259 |
|
||||
|[Azure-Samples/openai](https://github.com/Azure-Samples/openai) | 252 |
|
||||
|[bborn/howdoi.ai](https://github.com/bborn/howdoi.ai) | 248 |
|
||||
|[hnawaz007/pythondataanalysis](https://github.com/hnawaz007/pythondataanalysis) | 247 |
|
||||
|[conceptofmind/toolformer](https://github.com/conceptofmind/toolformer) | 243 |
|
||||
|[truera/trulens](https://github.com/truera/trulens) | 239 |
|
||||
|[ur-whitelab/exmol](https://github.com/ur-whitelab/exmol) | 238 |
|
||||
|[intel/intel-extension-for-transformers](https://github.com/intel/intel-extension-for-transformers) | 237 |
|
||||
|[monarch-initiative/ontogpt](https://github.com/monarch-initiative/ontogpt) | 236 |
|
||||
|[wandb/edu](https://github.com/wandb/edu) | 231 |
|
||||
|[recalign/RecAlign](https://github.com/recalign/RecAlign) | 229 |
|
||||
|[alvarosevilla95/autolang](https://github.com/alvarosevilla95/autolang) | 223 |
|
||||
|[kaleido-lab/dolphin](https://github.com/kaleido-lab/dolphin) | 221 |
|
||||
|[JohnSnowLabs/nlptest](https://github.com/JohnSnowLabs/nlptest) | 220 |
|
||||
|[paolorechia/learn-langchain](https://github.com/paolorechia/learn-langchain) | 219 |
|
||||
|[Safiullah-Rahu/CSV-AI](https://github.com/Safiullah-Rahu/CSV-AI) | 215 |
|
||||
|[Haste171/langchain-chatbot](https://github.com/Haste171/langchain-chatbot) | 215 |
|
||||
|[steamship-packages/langchain-agent-production-starter](https://github.com/steamship-packages/langchain-agent-production-starter) | 214 |
|
||||
|[airobotlab/KoChatGPT](https://github.com/airobotlab/KoChatGPT) | 213 |
|
||||
|[filip-michalsky/SalesGPT](https://github.com/filip-michalsky/SalesGPT) | 211 |
|
||||
|[marella/chatdocs](https://github.com/marella/chatdocs) | 207 |
|
||||
|[su77ungr/CASALIOY](https://github.com/su77ungr/CASALIOY) | 200 |
|
||||
|[shaman-ai/agent-actors](https://github.com/shaman-ai/agent-actors) | 195 |
|
||||
|[plchld/InsightFlow](https://github.com/plchld/InsightFlow) | 189 |
|
||||
|[jbrukh/gpt-jargon](https://github.com/jbrukh/gpt-jargon) | 186 |
|
||||
|[hwchase17/langchain-streamlit-template](https://github.com/hwchase17/langchain-streamlit-template) | 185 |
|
||||
|[huchenxucs/ChatDB](https://github.com/huchenxucs/ChatDB) | 179 |
|
||||
|[benthecoder/ClassGPT](https://github.com/benthecoder/ClassGPT) | 178 |
|
||||
|[hwchase17/chroma-langchain](https://github.com/hwchase17/chroma-langchain) | 178 |
|
||||
|[radi-cho/datasetGPT](https://github.com/radi-cho/datasetGPT) | 177 |
|
||||
|[jiran214/GPT-vup](https://github.com/jiran214/GPT-vup) | 176 |
|
||||
|[rsaryev/talk-codebase](https://github.com/rsaryev/talk-codebase) | 174 |
|
||||
|[edreisMD/plugnplai](https://github.com/edreisMD/plugnplai) | 174 |
|
||||
|[gia-guar/JARVIS-ChatGPT](https://github.com/gia-guar/JARVIS-ChatGPT) | 172 |
|
||||
|[hardbyte/qabot](https://github.com/hardbyte/qabot) | 171 |
|
||||
|[shamspias/customizable-gpt-chatbot](https://github.com/shamspias/customizable-gpt-chatbot) | 165 |
|
||||
|[gustavz/DataChad](https://github.com/gustavz/DataChad) | 164 |
|
||||
|[yasyf/compress-gpt](https://github.com/yasyf/compress-gpt) | 163 |
|
||||
|[SamPink/dev-gpt](https://github.com/SamPink/dev-gpt) | 161 |
|
||||
|[yuanjie-ai/ChatLLM](https://github.com/yuanjie-ai/ChatLLM) | 161 |
|
||||
|[pablomarin/GPT-Azure-Search-Engine](https://github.com/pablomarin/GPT-Azure-Search-Engine) | 160 |
|
||||
|[jondurbin/airoboros](https://github.com/jondurbin/airoboros) | 157 |
|
||||
|[fengyuli-dev/multimedia-gpt](https://github.com/fengyuli-dev/multimedia-gpt) | 157 |
|
||||
|[PradipNichite/Youtube-Tutorials](https://github.com/PradipNichite/Youtube-Tutorials) | 156 |
|
||||
|[nicknochnack/LangchainDocuments](https://github.com/nicknochnack/LangchainDocuments) | 155 |
|
||||
|[ethanyanjiali/minChatGPT](https://github.com/ethanyanjiali/minChatGPT) | 155 |
|
||||
|[ccurme/yolopandas](https://github.com/ccurme/yolopandas) | 154 |
|
||||
|[chakkaradeep/pyCodeAGI](https://github.com/chakkaradeep/pyCodeAGI) | 153 |
|
||||
|[preset-io/promptimize](https://github.com/preset-io/promptimize) | 150 |
|
||||
|[onlyphantom/llm-python](https://github.com/onlyphantom/llm-python) | 148 |
|
||||
|[Azure-Samples/azure-search-power-skills](https://github.com/Azure-Samples/azure-search-power-skills) | 146 |
|
||||
|[realminchoi/babyagi-ui](https://github.com/realminchoi/babyagi-ui) | 144 |
|
||||
|[microsoft/azure-openai-in-a-day-workshop](https://github.com/microsoft/azure-openai-in-a-day-workshop) | 144 |
|
||||
|[jmpaz/promptlib](https://github.com/jmpaz/promptlib) | 143 |
|
||||
|[shauryr/S2QA](https://github.com/shauryr/S2QA) | 142 |
|
||||
|[handrew/browserpilot](https://github.com/handrew/browserpilot) | 141 |
|
||||
|[Jaseci-Labs/jaseci](https://github.com/Jaseci-Labs/jaseci) | 140 |
|
||||
|[Klingefjord/chatgpt-telegram](https://github.com/Klingefjord/chatgpt-telegram) | 140 |
|
||||
|[WongSaang/chatgpt-ui-server](https://github.com/WongSaang/chatgpt-ui-server) | 139 |
|
||||
|[ibiscp/LLM-IMDB](https://github.com/ibiscp/LLM-IMDB) | 139 |
|
||||
|[menloparklab/langchain-cohere-qdrant-doc-retrieval](https://github.com/menloparklab/langchain-cohere-qdrant-doc-retrieval) | 138 |
|
||||
|[hirokidaichi/wanna](https://github.com/hirokidaichi/wanna) | 137 |
|
||||
|[steamship-core/vercel-examples](https://github.com/steamship-core/vercel-examples) | 137 |
|
||||
|[deeppavlov/dream](https://github.com/deeppavlov/dream) | 136 |
|
||||
|[miaoshouai/miaoshouai-assistant](https://github.com/miaoshouai/miaoshouai-assistant) | 135 |
|
||||
|[sugarforever/LangChain-Tutorials](https://github.com/sugarforever/LangChain-Tutorials) | 135 |
|
||||
|[yasyf/summ](https://github.com/yasyf/summ) | 135 |
|
||||
|[peterw/StoryStorm](https://github.com/peterw/StoryStorm) | 134 |
|
||||
|[vaibkumr/prompt-optimizer](https://github.com/vaibkumr/prompt-optimizer) | 132 |
|
||||
|[ju-bezdek/langchain-decorators](https://github.com/ju-bezdek/langchain-decorators) | 130 |
|
||||
|[homanp/vercel-langchain](https://github.com/homanp/vercel-langchain) | 128 |
|
||||
|[Teahouse-Studios/akari-bot](https://github.com/Teahouse-Studios/akari-bot) | 127 |
|
||||
|[petehunt/langchain-github-bot](https://github.com/petehunt/langchain-github-bot) | 125 |
|
||||
|[eunomia-bpf/GPTtrace](https://github.com/eunomia-bpf/GPTtrace) | 122 |
|
||||
|[fixie-ai/fixie-examples](https://github.com/fixie-ai/fixie-examples) | 122 |
|
||||
|[Aggregate-Intellect/practical-llms](https://github.com/Aggregate-Intellect/practical-llms) | 120 |
|
||||
|[davila7/file-gpt](https://github.com/davila7/file-gpt) | 120 |
|
||||
|[Azure-Samples/azure-search-openai-demo-csharp](https://github.com/Azure-Samples/azure-search-openai-demo-csharp) | 119 |
|
||||
|[prof-frink-lab/slangchain](https://github.com/prof-frink-lab/slangchain) | 117 |
|
||||
|[aurelio-labs/arxiv-bot](https://github.com/aurelio-labs/arxiv-bot) | 117 |
|
||||
|[zenml-io/zenml-projects](https://github.com/zenml-io/zenml-projects) | 116 |
|
||||
|[flurb18/AgentOoba](https://github.com/flurb18/AgentOoba) | 114 |
|
||||
|[kaarthik108/snowChat](https://github.com/kaarthik108/snowChat) | 112 |
|
||||
|[RedisVentures/redis-openai-qna](https://github.com/RedisVentures/redis-openai-qna) | 111 |
|
||||
|[solana-labs/chatgpt-plugin](https://github.com/solana-labs/chatgpt-plugin) | 111 |
|
||||
|[kulltc/chatgpt-sql](https://github.com/kulltc/chatgpt-sql) | 109 |
|
||||
|[summarizepaper/summarizepaper](https://github.com/summarizepaper/summarizepaper) | 109 |
|
||||
|[Azure-Samples/miyagi](https://github.com/Azure-Samples/miyagi) | 106 |
|
||||
|[ssheng/BentoChain](https://github.com/ssheng/BentoChain) | 106 |
|
||||
|[voxel51/voxelgpt](https://github.com/voxel51/voxelgpt) | 105 |
|
||||
|[mallahyari/drqa](https://github.com/mallahyari/drqa) | 103 |
|
||||
|
||||
|
||||
|
||||
_Generated by [github-dependents-info](https://github.com/nvuillam/github-dependents-info)_
|
||||
|
||||
[github-dependents-info --repo hwchase17/langchain --markdownfile dependents.md --minstars 100 --sort stars]
|
||||
|
|
@ -1,661 +0,0 @@
|
|||
# Debugging
|
||||
|
||||
If you're building with LLMs, at some point something will break, and you'll need to debug. A model call will fail, or the model output will be misformatted, or there will be some nested model calls and it won't be clear where along the way an incorrect output was created.
|
||||
|
||||
Here's a few different tools and functionalities to aid in debugging.
|
||||
|
||||
|
||||
|
||||
## Tracing
|
||||
|
||||
Platforms with tracing capabilities like [LangSmith](/docs/guides/langsmith/) and [WandB](/docs/ecosystem/integrations/agent_with_wandb_tracing) are the most comprehensive solutions for debugging. These platforms make it easy to not only log and visualize LLM apps, but also to actively debug, test and refine them.
|
||||
|
||||
For anyone building production-grade LLM applications, we highly recommend using a platform like this.
|
||||
|
||||

|
||||
|
||||
## `langchain.debug` and `langchain.verbose`
|
||||
|
||||
If you're prototyping in Jupyter Notebooks or running Python scripts, it can be helpful to print out the intermediate steps of a Chain run.
|
||||
|
||||
There's a number of ways to enable printing at varying degrees of verbosity.
|
||||
|
||||
Let's suppose we have a simple agent and want to visualize the actions it takes and tool outputs it receives. Without any debugging, here's what we see:
|
||||
|
||||
|
||||
```python
|
||||
from langchain.agents import AgentType, initialize_agent, load_tools
|
||||
from langchain.chat_models import ChatOpenAI
|
||||
|
||||
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
|
||||
tools = load_tools(["ddg-search", "llm-math"], llm=llm)
|
||||
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION)
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
agent.run("Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?")
|
||||
```
|
||||
|
||||
<CodeOutputBlock lang="python">
|
||||
|
||||
```
|
||||
'The director of the 2023 film Oppenheimer is Christopher Nolan and he is approximately 19345 days old in 2023.'
|
||||
```
|
||||
|
||||
</CodeOutputBlock>
|
||||
|
||||
### `langchain.debug = True`
|
||||
|
||||
Setting the global `debug` flag will cause all LangChain components with callback support (chains, models, agents, tools, retrievers) to print the inputs they receive and outputs they generate. This is the most verbose setting and will fully log raw inputs and outputs.
|
||||
|
||||
|
||||
```python
|
||||
import langchain
|
||||
|
||||
langchain.debug = True
|
||||
|
||||
agent.run("Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?")
|
||||
```
|
||||
|
||||
<details> <summary>Console output</summary>
|
||||
|
||||
<CodeOutputBlock lang="python">
|
||||
|
||||
```
|
||||
[chain/start] [1:RunTypeEnum.chain:AgentExecutor] Entering Chain run with input:
|
||||
{
|
||||
"input": "Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?"
|
||||
}
|
||||
[chain/start] [1:RunTypeEnum.chain:AgentExecutor > 2:RunTypeEnum.chain:LLMChain] Entering Chain run with input:
|
||||
{
|
||||
"input": "Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?",
|
||||
"agent_scratchpad": "",
|
||||
"stop": [
|
||||
"\nObservation:",
|
||||
"\n\tObservation:"
|
||||
]
|
||||
}
|
||||
[llm/start] [1:RunTypeEnum.chain:AgentExecutor > 2:RunTypeEnum.chain:LLMChain > 3:RunTypeEnum.llm:ChatOpenAI] Entering LLM run with input:
|
||||
{
|
||||
"prompts": [
|
||||
"Human: Answer the following questions as best you can. You have access to the following tools:\n\nduckduckgo_search: A wrapper around DuckDuckGo Search. Useful for when you need to answer questions about current events. Input should be a search query.\nCalculator: Useful for when you need to answer questions about math.\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [duckduckgo_search, Calculator]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin!\n\nQuestion: Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?\nThought:"
|
||||
]
|
||||
}
|
||||
[llm/end] [1:RunTypeEnum.chain:AgentExecutor > 2:RunTypeEnum.chain:LLMChain > 3:RunTypeEnum.llm:ChatOpenAI] [5.53s] Exiting LLM run with output:
|
||||
{
|
||||
"generations": [
|
||||
[
|
||||
{
|
||||
"text": "I need to find out who directed the 2023 film Oppenheimer and their age. Then, I need to calculate their age in days. I will use DuckDuckGo to find out the director and their age.\nAction: duckduckgo_search\nAction Input: \"Director of the 2023 film Oppenheimer and their age\"",
|
||||
"generation_info": {
|
||||
"finish_reason": "stop"
|
||||
},
|
||||
"message": {
|
||||
"lc": 1,
|
||||
"type": "constructor",
|
||||
"id": [
|
||||
"langchain",
|
||||
"schema",
|
||||
"messages",
|
||||
"AIMessage"
|
||||
],
|
||||
"kwargs": {
|
||||
"content": "I need to find out who directed the 2023 film Oppenheimer and their age. Then, I need to calculate their age in days. I will use DuckDuckGo to find out the director and their age.\nAction: duckduckgo_search\nAction Input: \"Director of the 2023 film Oppenheimer and their age\"",
|
||||
"additional_kwargs": {}
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
],
|
||||
"llm_output": {
|
||||
"token_usage": {
|
||||
"prompt_tokens": 206,
|
||||
"completion_tokens": 71,
|
||||
"total_tokens": 277
|
||||
},
|
||||
"model_name": "gpt-4"
|
||||
},
|
||||
"run": null
|
||||
}
|
||||
[chain/end] [1:RunTypeEnum.chain:AgentExecutor > 2:RunTypeEnum.chain:LLMChain] [5.53s] Exiting Chain run with output:
|
||||
{
|
||||
"text": "I need to find out who directed the 2023 film Oppenheimer and their age. Then, I need to calculate their age in days. I will use DuckDuckGo to find out the director and their age.\nAction: duckduckgo_search\nAction Input: \"Director of the 2023 film Oppenheimer and their age\""
|
||||
}
|
||||
[tool/start] [1:RunTypeEnum.chain:AgentExecutor > 4:RunTypeEnum.tool:duckduckgo_search] Entering Tool run with input:
|
||||
"Director of the 2023 film Oppenheimer and their age"
|
||||
[tool/end] [1:RunTypeEnum.chain:AgentExecutor > 4:RunTypeEnum.tool:duckduckgo_search] [1.51s] Exiting Tool run with output:
|
||||
"Capturing the mad scramble to build the first atomic bomb required rapid-fire filming, strict set rules and the construction of an entire 1940s western town. By Jada Yuan. July 19, 2023 at 5:00 a ... In Christopher Nolan's new film, "Oppenheimer," Cillian Murphy stars as J. Robert Oppenheimer, the American physicist who oversaw the Manhattan Project in Los Alamos, N.M. Universal Pictures... Oppenheimer: Directed by Christopher Nolan. With Cillian Murphy, Emily Blunt, Robert Downey Jr., Alden Ehrenreich. The story of American scientist J. Robert Oppenheimer and his role in the development of the atomic bomb. Christopher Nolan goes deep on 'Oppenheimer,' his most 'extreme' film to date. By Kenneth Turan. July 11, 2023 5 AM PT. For Subscribers. Christopher Nolan is photographed in Los Angeles ... Oppenheimer is a 2023 epic biographical thriller film written and directed by Christopher Nolan.It is based on the 2005 biography American Prometheus by Kai Bird and Martin J. Sherwin about J. Robert Oppenheimer, a theoretical physicist who was pivotal in developing the first nuclear weapons as part of the Manhattan Project and thereby ushering in the Atomic Age."
|
||||
[chain/start] [1:RunTypeEnum.chain:AgentExecutor > 5:RunTypeEnum.chain:LLMChain] Entering Chain run with input:
|
||||
{
|
||||
"input": "Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?",
|
||||
"agent_scratchpad": "I need to find out who directed the 2023 film Oppenheimer and their age. Then, I need to calculate their age in days. I will use DuckDuckGo to find out the director and their age.\nAction: duckduckgo_search\nAction Input: \"Director of the 2023 film Oppenheimer and their age\"\nObservation: Capturing the mad scramble to build the first atomic bomb required rapid-fire filming, strict set rules and the construction of an entire 1940s western town. By Jada Yuan. July 19, 2023 at 5:00 a ... In Christopher Nolan's new film, \"Oppenheimer,\" Cillian Murphy stars as J. Robert Oppenheimer, the American physicist who oversaw the Manhattan Project in Los Alamos, N.M. Universal Pictures... Oppenheimer: Directed by Christopher Nolan. With Cillian Murphy, Emily Blunt, Robert Downey Jr., Alden Ehrenreich. The story of American scientist J. Robert Oppenheimer and his role in the development of the atomic bomb. Christopher Nolan goes deep on 'Oppenheimer,' his most 'extreme' film to date. By Kenneth Turan. July 11, 2023 5 AM PT. For Subscribers. Christopher Nolan is photographed in Los Angeles ... Oppenheimer is a 2023 epic biographical thriller film written and directed by Christopher Nolan.It is based on the 2005 biography American Prometheus by Kai Bird and Martin J. Sherwin about J. Robert Oppenheimer, a theoretical physicist who was pivotal in developing the first nuclear weapons as part of the Manhattan Project and thereby ushering in the Atomic Age.\nThought:",
|
||||
"stop": [
|
||||
"\nObservation:",
|
||||
"\n\tObservation:"
|
||||
]
|
||||
}
|
||||
[llm/start] [1:RunTypeEnum.chain:AgentExecutor > 5:RunTypeEnum.chain:LLMChain > 6:RunTypeEnum.llm:ChatOpenAI] Entering LLM run with input:
|
||||
{
|
||||
"prompts": [
|
||||
"Human: Answer the following questions as best you can. You have access to the following tools:\n\nduckduckgo_search: A wrapper around DuckDuckGo Search. Useful for when you need to answer questions about current events. Input should be a search query.\nCalculator: Useful for when you need to answer questions about math.\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [duckduckgo_search, Calculator]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin!\n\nQuestion: Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?\nThought:I need to find out who directed the 2023 film Oppenheimer and their age. Then, I need to calculate their age in days. I will use DuckDuckGo to find out the director and their age.\nAction: duckduckgo_search\nAction Input: \"Director of the 2023 film Oppenheimer and their age\"\nObservation: Capturing the mad scramble to build the first atomic bomb required rapid-fire filming, strict set rules and the construction of an entire 1940s western town. By Jada Yuan. July 19, 2023 at 5:00 a ... In Christopher Nolan's new film, \"Oppenheimer,\" Cillian Murphy stars as J. Robert Oppenheimer, the American physicist who oversaw the Manhattan Project in Los Alamos, N.M. Universal Pictures... Oppenheimer: Directed by Christopher Nolan. With Cillian Murphy, Emily Blunt, Robert Downey Jr., Alden Ehrenreich. The story of American scientist J. Robert Oppenheimer and his role in the development of the atomic bomb. Christopher Nolan goes deep on 'Oppenheimer,' his most 'extreme' film to date. By Kenneth Turan. July 11, 2023 5 AM PT. For Subscribers. Christopher Nolan is photographed in Los Angeles ... Oppenheimer is a 2023 epic biographical thriller film written and directed by Christopher Nolan.It is based on the 2005 biography American Prometheus by Kai Bird and Martin J. Sherwin about J. Robert Oppenheimer, a theoretical physicist who was pivotal in developing the first nuclear weapons as part of the Manhattan Project and thereby ushering in the Atomic Age.\nThought:"
|
||||
]
|
||||
}
|
||||
[llm/end] [1:RunTypeEnum.chain:AgentExecutor > 5:RunTypeEnum.chain:LLMChain > 6:RunTypeEnum.llm:ChatOpenAI] [4.46s] Exiting LLM run with output:
|
||||
{
|
||||
"generations": [
|
||||
[
|
||||
{
|
||||
"text": "The director of the 2023 film Oppenheimer is Christopher Nolan. Now I need to find out his age.\nAction: duckduckgo_search\nAction Input: \"Christopher Nolan age\"",
|
||||
"generation_info": {
|
||||
"finish_reason": "stop"
|
||||
},
|
||||
"message": {
|
||||
"lc": 1,
|
||||
"type": "constructor",
|
||||
"id": [
|
||||
"langchain",
|
||||
"schema",
|
||||
"messages",
|
||||
"AIMessage"
|
||||
],
|
||||
"kwargs": {
|
||||
"content": "The director of the 2023 film Oppenheimer is Christopher Nolan. Now I need to find out his age.\nAction: duckduckgo_search\nAction Input: \"Christopher Nolan age\"",
|
||||
"additional_kwargs": {}
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
],
|
||||
"llm_output": {
|
||||
"token_usage": {
|
||||
"prompt_tokens": 550,
|
||||
"completion_tokens": 39,
|
||||
"total_tokens": 589
|
||||
},
|
||||
"model_name": "gpt-4"
|
||||
},
|
||||
"run": null
|
||||
}
|
||||
[chain/end] [1:RunTypeEnum.chain:AgentExecutor > 5:RunTypeEnum.chain:LLMChain] [4.46s] Exiting Chain run with output:
|
||||
{
|
||||
"text": "The director of the 2023 film Oppenheimer is Christopher Nolan. Now I need to find out his age.\nAction: duckduckgo_search\nAction Input: \"Christopher Nolan age\""
|
||||
}
|
||||
[tool/start] [1:RunTypeEnum.chain:AgentExecutor > 7:RunTypeEnum.tool:duckduckgo_search] Entering Tool run with input:
|
||||
"Christopher Nolan age"
|
||||
[tool/end] [1:RunTypeEnum.chain:AgentExecutor > 7:RunTypeEnum.tool:duckduckgo_search] [1.33s] Exiting Tool run with output:
|
||||
"Christopher Edward Nolan CBE (born 30 July 1970) is a British and American filmmaker. Known for his Hollywood blockbusters with complex storytelling, Nolan is considered a leading filmmaker of the 21st century. His films have grossed $5 billion worldwide. The recipient of many accolades, he has been nominated for five Academy Awards, five BAFTA Awards and six Golden Globe Awards. July 30, 1970 (age 52) London England Notable Works: "Dunkirk" "Tenet" "The Prestige" See all related content → Recent News Jul. 13, 2023, 11:11 AM ET (AP) Cillian Murphy, playing Oppenheimer, finally gets to lead a Christopher Nolan film July 11, 2023 5 AM PT For Subscribers Christopher Nolan is photographed in Los Angeles. (Joe Pugliese / For The Times) This is not the story I was supposed to write. Oppenheimer director Christopher Nolan, Cillian Murphy, Emily Blunt and Matt Damon on the stakes of making a three-hour, CGI-free summer film. Christopher Nolan, the director behind such films as "Dunkirk," "Inception," "Interstellar," and the "Dark Knight" trilogy, has spent the last three years living in Oppenheimer's world, writing ..."
|
||||
[chain/start] [1:RunTypeEnum.chain:AgentExecutor > 8:RunTypeEnum.chain:LLMChain] Entering Chain run with input:
|
||||
{
|
||||
"input": "Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?",
|
||||
"agent_scratchpad": "I need to find out who directed the 2023 film Oppenheimer and their age. Then, I need to calculate their age in days. I will use DuckDuckGo to find out the director and their age.\nAction: duckduckgo_search\nAction Input: \"Director of the 2023 film Oppenheimer and their age\"\nObservation: Capturing the mad scramble to build the first atomic bomb required rapid-fire filming, strict set rules and the construction of an entire 1940s western town. By Jada Yuan. July 19, 2023 at 5:00 a ... In Christopher Nolan's new film, \"Oppenheimer,\" Cillian Murphy stars as J. Robert Oppenheimer, the American physicist who oversaw the Manhattan Project in Los Alamos, N.M. Universal Pictures... Oppenheimer: Directed by Christopher Nolan. With Cillian Murphy, Emily Blunt, Robert Downey Jr., Alden Ehrenreich. The story of American scientist J. Robert Oppenheimer and his role in the development of the atomic bomb. Christopher Nolan goes deep on 'Oppenheimer,' his most 'extreme' film to date. By Kenneth Turan. July 11, 2023 5 AM PT. For Subscribers. Christopher Nolan is photographed in Los Angeles ... Oppenheimer is a 2023 epic biographical thriller film written and directed by Christopher Nolan.It is based on the 2005 biography American Prometheus by Kai Bird and Martin J. Sherwin about J. Robert Oppenheimer, a theoretical physicist who was pivotal in developing the first nuclear weapons as part of the Manhattan Project and thereby ushering in the Atomic Age.\nThought:The director of the 2023 film Oppenheimer is Christopher Nolan. Now I need to find out his age.\nAction: duckduckgo_search\nAction Input: \"Christopher Nolan age\"\nObservation: Christopher Edward Nolan CBE (born 30 July 1970) is a British and American filmmaker. Known for his Hollywood blockbusters with complex storytelling, Nolan is considered a leading filmmaker of the 21st century. His films have grossed $5 billion worldwide. The recipient of many accolades, he has been nominated for five Academy Awards, five BAFTA Awards and six Golden Globe Awards. July 30, 1970 (age 52) London England Notable Works: \"Dunkirk\" \"Tenet\" \"The Prestige\" See all related content → Recent News Jul. 13, 2023, 11:11 AM ET (AP) Cillian Murphy, playing Oppenheimer, finally gets to lead a Christopher Nolan film July 11, 2023 5 AM PT For Subscribers Christopher Nolan is photographed in Los Angeles. (Joe Pugliese / For The Times) This is not the story I was supposed to write. Oppenheimer director Christopher Nolan, Cillian Murphy, Emily Blunt and Matt Damon on the stakes of making a three-hour, CGI-free summer film. Christopher Nolan, the director behind such films as \"Dunkirk,\" \"Inception,\" \"Interstellar,\" and the \"Dark Knight\" trilogy, has spent the last three years living in Oppenheimer's world, writing ...\nThought:",
|
||||
"stop": [
|
||||
"\nObservation:",
|
||||
"\n\tObservation:"
|
||||
]
|
||||
}
|
||||
[llm/start] [1:RunTypeEnum.chain:AgentExecutor > 8:RunTypeEnum.chain:LLMChain > 9:RunTypeEnum.llm:ChatOpenAI] Entering LLM run with input:
|
||||
{
|
||||
"prompts": [
|
||||
"Human: Answer the following questions as best you can. You have access to the following tools:\n\nduckduckgo_search: A wrapper around DuckDuckGo Search. Useful for when you need to answer questions about current events. Input should be a search query.\nCalculator: Useful for when you need to answer questions about math.\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [duckduckgo_search, Calculator]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin!\n\nQuestion: Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?\nThought:I need to find out who directed the 2023 film Oppenheimer and their age. Then, I need to calculate their age in days. I will use DuckDuckGo to find out the director and their age.\nAction: duckduckgo_search\nAction Input: \"Director of the 2023 film Oppenheimer and their age\"\nObservation: Capturing the mad scramble to build the first atomic bomb required rapid-fire filming, strict set rules and the construction of an entire 1940s western town. By Jada Yuan. July 19, 2023 at 5:00 a ... In Christopher Nolan's new film, \"Oppenheimer,\" Cillian Murphy stars as J. Robert Oppenheimer, the American physicist who oversaw the Manhattan Project in Los Alamos, N.M. Universal Pictures... Oppenheimer: Directed by Christopher Nolan. With Cillian Murphy, Emily Blunt, Robert Downey Jr., Alden Ehrenreich. The story of American scientist J. Robert Oppenheimer and his role in the development of the atomic bomb. Christopher Nolan goes deep on 'Oppenheimer,' his most 'extreme' film to date. By Kenneth Turan. July 11, 2023 5 AM PT. For Subscribers. Christopher Nolan is photographed in Los Angeles ... Oppenheimer is a 2023 epic biographical thriller film written and directed by Christopher Nolan.It is based on the 2005 biography American Prometheus by Kai Bird and Martin J. Sherwin about J. Robert Oppenheimer, a theoretical physicist who was pivotal in developing the first nuclear weapons as part of the Manhattan Project and thereby ushering in the Atomic Age.\nThought:The director of the 2023 film Oppenheimer is Christopher Nolan. Now I need to find out his age.\nAction: duckduckgo_search\nAction Input: \"Christopher Nolan age\"\nObservation: Christopher Edward Nolan CBE (born 30 July 1970) is a British and American filmmaker. Known for his Hollywood blockbusters with complex storytelling, Nolan is considered a leading filmmaker of the 21st century. His films have grossed $5 billion worldwide. The recipient of many accolades, he has been nominated for five Academy Awards, five BAFTA Awards and six Golden Globe Awards. July 30, 1970 (age 52) London England Notable Works: \"Dunkirk\" \"Tenet\" \"The Prestige\" See all related content → Recent News Jul. 13, 2023, 11:11 AM ET (AP) Cillian Murphy, playing Oppenheimer, finally gets to lead a Christopher Nolan film July 11, 2023 5 AM PT For Subscribers Christopher Nolan is photographed in Los Angeles. (Joe Pugliese / For The Times) This is not the story I was supposed to write. Oppenheimer director Christopher Nolan, Cillian Murphy, Emily Blunt and Matt Damon on the stakes of making a three-hour, CGI-free summer film. Christopher Nolan, the director behind such films as \"Dunkirk,\" \"Inception,\" \"Interstellar,\" and the \"Dark Knight\" trilogy, has spent the last three years living in Oppenheimer's world, writing ...\nThought:"
|
||||
]
|
||||
}
|
||||
[llm/end] [1:RunTypeEnum.chain:AgentExecutor > 8:RunTypeEnum.chain:LLMChain > 9:RunTypeEnum.llm:ChatOpenAI] [2.69s] Exiting LLM run with output:
|
||||
{
|
||||
"generations": [
|
||||
[
|
||||
{
|
||||
"text": "Christopher Nolan was born on July 30, 1970, which makes him 52 years old in 2023. Now I need to calculate his age in days.\nAction: Calculator\nAction Input: 52*365",
|
||||
"generation_info": {
|
||||
"finish_reason": "stop"
|
||||
},
|
||||
"message": {
|
||||
"lc": 1,
|
||||
"type": "constructor",
|
||||
"id": [
|
||||
"langchain",
|
||||
"schema",
|
||||
"messages",
|
||||
"AIMessage"
|
||||
],
|
||||
"kwargs": {
|
||||
"content": "Christopher Nolan was born on July 30, 1970, which makes him 52 years old in 2023. Now I need to calculate his age in days.\nAction: Calculator\nAction Input: 52*365",
|
||||
"additional_kwargs": {}
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
],
|
||||
"llm_output": {
|
||||
"token_usage": {
|
||||
"prompt_tokens": 868,
|
||||
"completion_tokens": 46,
|
||||
"total_tokens": 914
|
||||
},
|
||||
"model_name": "gpt-4"
|
||||
},
|
||||
"run": null
|
||||
}
|
||||
[chain/end] [1:RunTypeEnum.chain:AgentExecutor > 8:RunTypeEnum.chain:LLMChain] [2.69s] Exiting Chain run with output:
|
||||
{
|
||||
"text": "Christopher Nolan was born on July 30, 1970, which makes him 52 years old in 2023. Now I need to calculate his age in days.\nAction: Calculator\nAction Input: 52*365"
|
||||
}
|
||||
[tool/start] [1:RunTypeEnum.chain:AgentExecutor > 10:RunTypeEnum.tool:Calculator] Entering Tool run with input:
|
||||
"52*365"
|
||||
[chain/start] [1:RunTypeEnum.chain:AgentExecutor > 10:RunTypeEnum.tool:Calculator > 11:RunTypeEnum.chain:LLMMathChain] Entering Chain run with input:
|
||||
{
|
||||
"question": "52*365"
|
||||
}
|
||||
[chain/start] [1:RunTypeEnum.chain:AgentExecutor > 10:RunTypeEnum.tool:Calculator > 11:RunTypeEnum.chain:LLMMathChain > 12:RunTypeEnum.chain:LLMChain] Entering Chain run with input:
|
||||
{
|
||||
"question": "52*365",
|
||||
"stop": [
|
||||
"```output"
|
||||
]
|
||||
}
|
||||
[llm/start] [1:RunTypeEnum.chain:AgentExecutor > 10:RunTypeEnum.tool:Calculator > 11:RunTypeEnum.chain:LLMMathChain > 12:RunTypeEnum.chain:LLMChain > 13:RunTypeEnum.llm:ChatOpenAI] Entering LLM run with input:
|
||||
{
|
||||
"prompts": [
|
||||
"Human: Translate a math problem into a expression that can be executed using Python's numexpr library. Use the output of running this code to answer the question.\n\nQuestion: ${Question with math problem.}\n```text\n${single line mathematical expression that solves the problem}\n```\n...numexpr.evaluate(text)...\n```output\n${Output of running the code}\n```\nAnswer: ${Answer}\n\nBegin.\n\nQuestion: What is 37593 * 67?\n```text\n37593 * 67\n```\n...numexpr.evaluate(\"37593 * 67\")...\n```output\n2518731\n```\nAnswer: 2518731\n\nQuestion: 37593^(1/5)\n```text\n37593**(1/5)\n```\n...numexpr.evaluate(\"37593**(1/5)\")...\n```output\n8.222831614237718\n```\nAnswer: 8.222831614237718\n\nQuestion: 52*365"
|
||||
]
|
||||
}
|
||||
[llm/end] [1:RunTypeEnum.chain:AgentExecutor > 10:RunTypeEnum.tool:Calculator > 11:RunTypeEnum.chain:LLMMathChain > 12:RunTypeEnum.chain:LLMChain > 13:RunTypeEnum.llm:ChatOpenAI] [2.89s] Exiting LLM run with output:
|
||||
{
|
||||
"generations": [
|
||||
[
|
||||
{
|
||||
"text": "```text\n52*365\n```\n...numexpr.evaluate(\"52*365\")...\n",
|
||||
"generation_info": {
|
||||
"finish_reason": "stop"
|
||||
},
|
||||
"message": {
|
||||
"lc": 1,
|
||||
"type": "constructor",
|
||||
"id": [
|
||||
"langchain",
|
||||
"schema",
|
||||
"messages",
|
||||
"AIMessage"
|
||||
],
|
||||
"kwargs": {
|
||||
"content": "```text\n52*365\n```\n...numexpr.evaluate(\"52*365\")...\n",
|
||||
"additional_kwargs": {}
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
],
|
||||
"llm_output": {
|
||||
"token_usage": {
|
||||
"prompt_tokens": 203,
|
||||
"completion_tokens": 19,
|
||||
"total_tokens": 222
|
||||
},
|
||||
"model_name": "gpt-4"
|
||||
},
|
||||
"run": null
|
||||
}
|
||||
[chain/end] [1:RunTypeEnum.chain:AgentExecutor > 10:RunTypeEnum.tool:Calculator > 11:RunTypeEnum.chain:LLMMathChain > 12:RunTypeEnum.chain:LLMChain] [2.89s] Exiting Chain run with output:
|
||||
{
|
||||
"text": "```text\n52*365\n```\n...numexpr.evaluate(\"52*365\")...\n"
|
||||
}
|
||||
[chain/end] [1:RunTypeEnum.chain:AgentExecutor > 10:RunTypeEnum.tool:Calculator > 11:RunTypeEnum.chain:LLMMathChain] [2.90s] Exiting Chain run with output:
|
||||
{
|
||||
"answer": "Answer: 18980"
|
||||
}
|
||||
[tool/end] [1:RunTypeEnum.chain:AgentExecutor > 10:RunTypeEnum.tool:Calculator] [2.90s] Exiting Tool run with output:
|
||||
"Answer: 18980"
|
||||
[chain/start] [1:RunTypeEnum.chain:AgentExecutor > 14:RunTypeEnum.chain:LLMChain] Entering Chain run with input:
|
||||
{
|
||||
"input": "Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?",
|
||||
"agent_scratchpad": "I need to find out who directed the 2023 film Oppenheimer and their age. Then, I need to calculate their age in days. I will use DuckDuckGo to find out the director and their age.\nAction: duckduckgo_search\nAction Input: \"Director of the 2023 film Oppenheimer and their age\"\nObservation: Capturing the mad scramble to build the first atomic bomb required rapid-fire filming, strict set rules and the construction of an entire 1940s western town. By Jada Yuan. July 19, 2023 at 5:00 a ... In Christopher Nolan's new film, \"Oppenheimer,\" Cillian Murphy stars as J. Robert Oppenheimer, the American physicist who oversaw the Manhattan Project in Los Alamos, N.M. Universal Pictures... Oppenheimer: Directed by Christopher Nolan. With Cillian Murphy, Emily Blunt, Robert Downey Jr., Alden Ehrenreich. The story of American scientist J. Robert Oppenheimer and his role in the development of the atomic bomb. Christopher Nolan goes deep on 'Oppenheimer,' his most 'extreme' film to date. By Kenneth Turan. July 11, 2023 5 AM PT. For Subscribers. Christopher Nolan is photographed in Los Angeles ... Oppenheimer is a 2023 epic biographical thriller film written and directed by Christopher Nolan.It is based on the 2005 biography American Prometheus by Kai Bird and Martin J. Sherwin about J. Robert Oppenheimer, a theoretical physicist who was pivotal in developing the first nuclear weapons as part of the Manhattan Project and thereby ushering in the Atomic Age.\nThought:The director of the 2023 film Oppenheimer is Christopher Nolan. Now I need to find out his age.\nAction: duckduckgo_search\nAction Input: \"Christopher Nolan age\"\nObservation: Christopher Edward Nolan CBE (born 30 July 1970) is a British and American filmmaker. Known for his Hollywood blockbusters with complex storytelling, Nolan is considered a leading filmmaker of the 21st century. His films have grossed $5 billion worldwide. The recipient of many accolades, he has been nominated for five Academy Awards, five BAFTA Awards and six Golden Globe Awards. July 30, 1970 (age 52) London England Notable Works: \"Dunkirk\" \"Tenet\" \"The Prestige\" See all related content → Recent News Jul. 13, 2023, 11:11 AM ET (AP) Cillian Murphy, playing Oppenheimer, finally gets to lead a Christopher Nolan film July 11, 2023 5 AM PT For Subscribers Christopher Nolan is photographed in Los Angeles. (Joe Pugliese / For The Times) This is not the story I was supposed to write. Oppenheimer director Christopher Nolan, Cillian Murphy, Emily Blunt and Matt Damon on the stakes of making a three-hour, CGI-free summer film. Christopher Nolan, the director behind such films as \"Dunkirk,\" \"Inception,\" \"Interstellar,\" and the \"Dark Knight\" trilogy, has spent the last three years living in Oppenheimer's world, writing ...\nThought:Christopher Nolan was born on July 30, 1970, which makes him 52 years old in 2023. Now I need to calculate his age in days.\nAction: Calculator\nAction Input: 52*365\nObservation: Answer: 18980\nThought:",
|
||||
"stop": [
|
||||
"\nObservation:",
|
||||
"\n\tObservation:"
|
||||
]
|
||||
}
|
||||
[llm/start] [1:RunTypeEnum.chain:AgentExecutor > 14:RunTypeEnum.chain:LLMChain > 15:RunTypeEnum.llm:ChatOpenAI] Entering LLM run with input:
|
||||
{
|
||||
"prompts": [
|
||||
"Human: Answer the following questions as best you can. You have access to the following tools:\n\nduckduckgo_search: A wrapper around DuckDuckGo Search. Useful for when you need to answer questions about current events. Input should be a search query.\nCalculator: Useful for when you need to answer questions about math.\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [duckduckgo_search, Calculator]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin!\n\nQuestion: Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?\nThought:I need to find out who directed the 2023 film Oppenheimer and their age. Then, I need to calculate their age in days. I will use DuckDuckGo to find out the director and their age.\nAction: duckduckgo_search\nAction Input: \"Director of the 2023 film Oppenheimer and their age\"\nObservation: Capturing the mad scramble to build the first atomic bomb required rapid-fire filming, strict set rules and the construction of an entire 1940s western town. By Jada Yuan. July 19, 2023 at 5:00 a ... In Christopher Nolan's new film, \"Oppenheimer,\" Cillian Murphy stars as J. Robert Oppenheimer, the American physicist who oversaw the Manhattan Project in Los Alamos, N.M. Universal Pictures... Oppenheimer: Directed by Christopher Nolan. With Cillian Murphy, Emily Blunt, Robert Downey Jr., Alden Ehrenreich. The story of American scientist J. Robert Oppenheimer and his role in the development of the atomic bomb. Christopher Nolan goes deep on 'Oppenheimer,' his most 'extreme' film to date. By Kenneth Turan. July 11, 2023 5 AM PT. For Subscribers. Christopher Nolan is photographed in Los Angeles ... Oppenheimer is a 2023 epic biographical thriller film written and directed by Christopher Nolan.It is based on the 2005 biography American Prometheus by Kai Bird and Martin J. Sherwin about J. Robert Oppenheimer, a theoretical physicist who was pivotal in developing the first nuclear weapons as part of the Manhattan Project and thereby ushering in the Atomic Age.\nThought:The director of the 2023 film Oppenheimer is Christopher Nolan. Now I need to find out his age.\nAction: duckduckgo_search\nAction Input: \"Christopher Nolan age\"\nObservation: Christopher Edward Nolan CBE (born 30 July 1970) is a British and American filmmaker. Known for his Hollywood blockbusters with complex storytelling, Nolan is considered a leading filmmaker of the 21st century. His films have grossed $5 billion worldwide. The recipient of many accolades, he has been nominated for five Academy Awards, five BAFTA Awards and six Golden Globe Awards. July 30, 1970 (age 52) London England Notable Works: \"Dunkirk\" \"Tenet\" \"The Prestige\" See all related content → Recent News Jul. 13, 2023, 11:11 AM ET (AP) Cillian Murphy, playing Oppenheimer, finally gets to lead a Christopher Nolan film July 11, 2023 5 AM PT For Subscribers Christopher Nolan is photographed in Los Angeles. (Joe Pugliese / For The Times) This is not the story I was supposed to write. Oppenheimer director Christopher Nolan, Cillian Murphy, Emily Blunt and Matt Damon on the stakes of making a three-hour, CGI-free summer film. Christopher Nolan, the director behind such films as \"Dunkirk,\" \"Inception,\" \"Interstellar,\" and the \"Dark Knight\" trilogy, has spent the last three years living in Oppenheimer's world, writing ...\nThought:Christopher Nolan was born on July 30, 1970, which makes him 52 years old in 2023. Now I need to calculate his age in days.\nAction: Calculator\nAction Input: 52*365\nObservation: Answer: 18980\nThought:"
|
||||
]
|
||||
}
|
||||
[llm/end] [1:RunTypeEnum.chain:AgentExecutor > 14:RunTypeEnum.chain:LLMChain > 15:RunTypeEnum.llm:ChatOpenAI] [3.52s] Exiting LLM run with output:
|
||||
{
|
||||
"generations": [
|
||||
[
|
||||
{
|
||||
"text": "I now know the final answer\nFinal Answer: The director of the 2023 film Oppenheimer is Christopher Nolan and he is 52 years old. His age in days is approximately 18980 days.",
|
||||
"generation_info": {
|
||||
"finish_reason": "stop"
|
||||
},
|
||||
"message": {
|
||||
"lc": 1,
|
||||
"type": "constructor",
|
||||
"id": [
|
||||
"langchain",
|
||||
"schema",
|
||||
"messages",
|
||||
"AIMessage"
|
||||
],
|
||||
"kwargs": {
|
||||
"content": "I now know the final answer\nFinal Answer: The director of the 2023 film Oppenheimer is Christopher Nolan and he is 52 years old. His age in days is approximately 18980 days.",
|
||||
"additional_kwargs": {}
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
],
|
||||
"llm_output": {
|
||||
"token_usage": {
|
||||
"prompt_tokens": 926,
|
||||
"completion_tokens": 43,
|
||||
"total_tokens": 969
|
||||
},
|
||||
"model_name": "gpt-4"
|
||||
},
|
||||
"run": null
|
||||
}
|
||||
[chain/end] [1:RunTypeEnum.chain:AgentExecutor > 14:RunTypeEnum.chain:LLMChain] [3.52s] Exiting Chain run with output:
|
||||
{
|
||||
"text": "I now know the final answer\nFinal Answer: The director of the 2023 film Oppenheimer is Christopher Nolan and he is 52 years old. His age in days is approximately 18980 days."
|
||||
}
|
||||
[chain/end] [1:RunTypeEnum.chain:AgentExecutor] [21.96s] Exiting Chain run with output:
|
||||
{
|
||||
"output": "The director of the 2023 film Oppenheimer is Christopher Nolan and he is 52 years old. His age in days is approximately 18980 days."
|
||||
}
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
'The director of the 2023 film Oppenheimer is Christopher Nolan and he is 52 years old. His age in days is approximately 18980 days.'
|
||||
```
|
||||
|
||||
</CodeOutputBlock>
|
||||
|
||||
</details>
|
||||
|
||||
### `langchain.verbose = True`
|
||||
|
||||
Setting the `verbose` flag will print out inputs and outputs in a slightly more readable format and will skip logging certain raw outputs (like the token usage stats for an LLM call) so that you can focus on application logic.
|
||||
|
||||
|
||||
```python
|
||||
import langchain
|
||||
|
||||
langchain.verbose = True
|
||||
|
||||
agent.run("Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?")
|
||||
```
|
||||
|
||||
<details> <summary>Console output</summary>
|
||||
|
||||
<CodeOutputBlock lang="python">
|
||||
|
||||
```
|
||||
|
||||
|
||||
> Entering new AgentExecutor chain...
|
||||
|
||||
|
||||
> Entering new LLMChain chain...
|
||||
Prompt after formatting:
|
||||
Answer the following questions as best you can. You have access to the following tools:
|
||||
|
||||
duckduckgo_search: A wrapper around DuckDuckGo Search. Useful for when you need to answer questions about current events. Input should be a search query.
|
||||
Calculator: Useful for when you need to answer questions about math.
|
||||
|
||||
Use the following format:
|
||||
|
||||
Question: the input question you must answer
|
||||
Thought: you should always think about what to do
|
||||
Action: the action to take, should be one of [duckduckgo_search, Calculator]
|
||||
Action Input: the input to the action
|
||||
Observation: the result of the action
|
||||
... (this Thought/Action/Action Input/Observation can repeat N times)
|
||||
Thought: I now know the final answer
|
||||
Final Answer: the final answer to the original input question
|
||||
|
||||
Begin!
|
||||
|
||||
Question: Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?
|
||||
Thought:
|
||||
|
||||
> Finished chain.
|
||||
First, I need to find out who directed the film Oppenheimer in 2023 and their birth date to calculate their age.
|
||||
Action: duckduckgo_search
|
||||
Action Input: "Director of the 2023 film Oppenheimer"
|
||||
Observation: Oppenheimer: Directed by Christopher Nolan. With Cillian Murphy, Emily Blunt, Robert Downey Jr., Alden Ehrenreich. The story of American scientist J. Robert Oppenheimer and his role in the development of the atomic bomb. In Christopher Nolan's new film, "Oppenheimer," Cillian Murphy stars as J. Robert ... 2023, 12:16 p.m. ET. ... including his role as the director of the Manhattan Engineer District, better ... J Robert Oppenheimer was the director of the secret Los Alamos Laboratory. It was established under US president Franklin D Roosevelt as part of the Manhattan Project to build the first atomic bomb. He oversaw the first atomic bomb detonation in the New Mexico desert in July 1945, code-named "Trinity". In this opening salvo of 2023's Oscar battle, Nolan has enjoined a star-studded cast for a retelling of the brilliant and haunted life of J. Robert Oppenheimer, the American physicist whose... Oppenheimer is a 2023 epic biographical thriller film written and directed by Christopher Nolan.It is based on the 2005 biography American Prometheus by Kai Bird and Martin J. Sherwin about J. Robert Oppenheimer, a theoretical physicist who was pivotal in developing the first nuclear weapons as part of the Manhattan Project and thereby ushering in the Atomic Age.
|
||||
Thought:
|
||||
|
||||
> Entering new LLMChain chain...
|
||||
Prompt after formatting:
|
||||
Answer the following questions as best you can. You have access to the following tools:
|
||||
|
||||
duckduckgo_search: A wrapper around DuckDuckGo Search. Useful for when you need to answer questions about current events. Input should be a search query.
|
||||
Calculator: Useful for when you need to answer questions about math.
|
||||
|
||||
Use the following format:
|
||||
|
||||
Question: the input question you must answer
|
||||
Thought: you should always think about what to do
|
||||
Action: the action to take, should be one of [duckduckgo_search, Calculator]
|
||||
Action Input: the input to the action
|
||||
Observation: the result of the action
|
||||
... (this Thought/Action/Action Input/Observation can repeat N times)
|
||||
Thought: I now know the final answer
|
||||
Final Answer: the final answer to the original input question
|
||||
|
||||
Begin!
|
||||
|
||||
Question: Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?
|
||||
Thought:First, I need to find out who directed the film Oppenheimer in 2023 and their birth date to calculate their age.
|
||||
Action: duckduckgo_search
|
||||
Action Input: "Director of the 2023 film Oppenheimer"
|
||||
Observation: Oppenheimer: Directed by Christopher Nolan. With Cillian Murphy, Emily Blunt, Robert Downey Jr., Alden Ehrenreich. The story of American scientist J. Robert Oppenheimer and his role in the development of the atomic bomb. In Christopher Nolan's new film, "Oppenheimer," Cillian Murphy stars as J. Robert ... 2023, 12:16 p.m. ET. ... including his role as the director of the Manhattan Engineer District, better ... J Robert Oppenheimer was the director of the secret Los Alamos Laboratory. It was established under US president Franklin D Roosevelt as part of the Manhattan Project to build the first atomic bomb. He oversaw the first atomic bomb detonation in the New Mexico desert in July 1945, code-named "Trinity". In this opening salvo of 2023's Oscar battle, Nolan has enjoined a star-studded cast for a retelling of the brilliant and haunted life of J. Robert Oppenheimer, the American physicist whose... Oppenheimer is a 2023 epic biographical thriller film written and directed by Christopher Nolan.It is based on the 2005 biography American Prometheus by Kai Bird and Martin J. Sherwin about J. Robert Oppenheimer, a theoretical physicist who was pivotal in developing the first nuclear weapons as part of the Manhattan Project and thereby ushering in the Atomic Age.
|
||||
Thought:
|
||||
|
||||
> Finished chain.
|
||||
The director of the 2023 film Oppenheimer is Christopher Nolan. Now I need to find out his birth date to calculate his age.
|
||||
Action: duckduckgo_search
|
||||
Action Input: "Christopher Nolan birth date"
|
||||
Observation: July 30, 1970 (age 52) London England Notable Works: "Dunkirk" "Tenet" "The Prestige" See all related content → Recent News Jul. 13, 2023, 11:11 AM ET (AP) Cillian Murphy, playing Oppenheimer, finally gets to lead a Christopher Nolan film Christopher Edward Nolan CBE (born 30 July 1970) is a British and American filmmaker. Known for his Hollywood blockbusters with complex storytelling, Nolan is considered a leading filmmaker of the 21st century. His films have grossed $5 billion worldwide. The recipient of many accolades, he has been nominated for five Academy Awards, five BAFTA Awards and six Golden Globe Awards. Christopher Nolan is currently 52 according to his birthdate July 30, 1970 Sun Sign Leo Born Place Westminster, London, England, United Kingdom Residence Los Angeles, California, United States Nationality Education Chris attended Haileybury and Imperial Service College, in Hertford Heath, Hertfordshire. Christopher Nolan's next movie will study the man who developed the atomic bomb, J. Robert Oppenheimer. Here's the release date, plot, trailers & more. July 2023 sees the release of Christopher Nolan's new film, Oppenheimer, his first movie since 2020's Tenet and his split from Warner Bros. Billed as an epic thriller about "the man who ...
|
||||
Thought:
|
||||
|
||||
> Entering new LLMChain chain...
|
||||
Prompt after formatting:
|
||||
Answer the following questions as best you can. You have access to the following tools:
|
||||
|
||||
duckduckgo_search: A wrapper around DuckDuckGo Search. Useful for when you need to answer questions about current events. Input should be a search query.
|
||||
Calculator: Useful for when you need to answer questions about math.
|
||||
|
||||
Use the following format:
|
||||
|
||||
Question: the input question you must answer
|
||||
Thought: you should always think about what to do
|
||||
Action: the action to take, should be one of [duckduckgo_search, Calculator]
|
||||
Action Input: the input to the action
|
||||
Observation: the result of the action
|
||||
... (this Thought/Action/Action Input/Observation can repeat N times)
|
||||
Thought: I now know the final answer
|
||||
Final Answer: the final answer to the original input question
|
||||
|
||||
Begin!
|
||||
|
||||
Question: Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?
|
||||
Thought:First, I need to find out who directed the film Oppenheimer in 2023 and their birth date to calculate their age.
|
||||
Action: duckduckgo_search
|
||||
Action Input: "Director of the 2023 film Oppenheimer"
|
||||
Observation: Oppenheimer: Directed by Christopher Nolan. With Cillian Murphy, Emily Blunt, Robert Downey Jr., Alden Ehrenreich. The story of American scientist J. Robert Oppenheimer and his role in the development of the atomic bomb. In Christopher Nolan's new film, "Oppenheimer," Cillian Murphy stars as J. Robert ... 2023, 12:16 p.m. ET. ... including his role as the director of the Manhattan Engineer District, better ... J Robert Oppenheimer was the director of the secret Los Alamos Laboratory. It was established under US president Franklin D Roosevelt as part of the Manhattan Project to build the first atomic bomb. He oversaw the first atomic bomb detonation in the New Mexico desert in July 1945, code-named "Trinity". In this opening salvo of 2023's Oscar battle, Nolan has enjoined a star-studded cast for a retelling of the brilliant and haunted life of J. Robert Oppenheimer, the American physicist whose... Oppenheimer is a 2023 epic biographical thriller film written and directed by Christopher Nolan.It is based on the 2005 biography American Prometheus by Kai Bird and Martin J. Sherwin about J. Robert Oppenheimer, a theoretical physicist who was pivotal in developing the first nuclear weapons as part of the Manhattan Project and thereby ushering in the Atomic Age.
|
||||
Thought:The director of the 2023 film Oppenheimer is Christopher Nolan. Now I need to find out his birth date to calculate his age.
|
||||
Action: duckduckgo_search
|
||||
Action Input: "Christopher Nolan birth date"
|
||||
Observation: July 30, 1970 (age 52) London England Notable Works: "Dunkirk" "Tenet" "The Prestige" See all related content → Recent News Jul. 13, 2023, 11:11 AM ET (AP) Cillian Murphy, playing Oppenheimer, finally gets to lead a Christopher Nolan film Christopher Edward Nolan CBE (born 30 July 1970) is a British and American filmmaker. Known for his Hollywood blockbusters with complex storytelling, Nolan is considered a leading filmmaker of the 21st century. His films have grossed $5 billion worldwide. The recipient of many accolades, he has been nominated for five Academy Awards, five BAFTA Awards and six Golden Globe Awards. Christopher Nolan is currently 52 according to his birthdate July 30, 1970 Sun Sign Leo Born Place Westminster, London, England, United Kingdom Residence Los Angeles, California, United States Nationality Education Chris attended Haileybury and Imperial Service College, in Hertford Heath, Hertfordshire. Christopher Nolan's next movie will study the man who developed the atomic bomb, J. Robert Oppenheimer. Here's the release date, plot, trailers & more. July 2023 sees the release of Christopher Nolan's new film, Oppenheimer, his first movie since 2020's Tenet and his split from Warner Bros. Billed as an epic thriller about "the man who ...
|
||||
Thought:
|
||||
|
||||
> Finished chain.
|
||||
Christopher Nolan was born on July 30, 1970. Now I need to calculate his age in 2023 and then convert it into days.
|
||||
Action: Calculator
|
||||
Action Input: (2023 - 1970) * 365
|
||||
|
||||
> Entering new LLMMathChain chain...
|
||||
(2023 - 1970) * 365
|
||||
|
||||
> Entering new LLMChain chain...
|
||||
Prompt after formatting:
|
||||
Translate a math problem into a expression that can be executed using Python's numexpr library. Use the output of running this code to answer the question.
|
||||
|
||||
Question: ${Question with math problem.}
|
||||
```text
|
||||
${single line mathematical expression that solves the problem}
|
||||
```
|
||||
...numexpr.evaluate(text)...
|
||||
```output
|
||||
${Output of running the code}
|
||||
```
|
||||
Answer: ${Answer}
|
||||
|
||||
Begin.
|
||||
|
||||
Question: What is 37593 * 67?
|
||||
```text
|
||||
37593 * 67
|
||||
```
|
||||
...numexpr.evaluate("37593 * 67")...
|
||||
```output
|
||||
2518731
|
||||
```
|
||||
Answer: 2518731
|
||||
|
||||
Question: 37593^(1/5)
|
||||
```text
|
||||
37593**(1/5)
|
||||
```
|
||||
...numexpr.evaluate("37593**(1/5)")...
|
||||
```output
|
||||
8.222831614237718
|
||||
```
|
||||
Answer: 8.222831614237718
|
||||
|
||||
Question: (2023 - 1970) * 365
|
||||
|
||||
|
||||
> Finished chain.
|
||||
```text
|
||||
(2023 - 1970) * 365
|
||||
```
|
||||
...numexpr.evaluate("(2023 - 1970) * 365")...
|
||||
|
||||
Answer: 19345
|
||||
> Finished chain.
|
||||
|
||||
Observation: Answer: 19345
|
||||
Thought:
|
||||
|
||||
> Entering new LLMChain chain...
|
||||
Prompt after formatting:
|
||||
Answer the following questions as best you can. You have access to the following tools:
|
||||
|
||||
duckduckgo_search: A wrapper around DuckDuckGo Search. Useful for when you need to answer questions about current events. Input should be a search query.
|
||||
Calculator: Useful for when you need to answer questions about math.
|
||||
|
||||
Use the following format:
|
||||
|
||||
Question: the input question you must answer
|
||||
Thought: you should always think about what to do
|
||||
Action: the action to take, should be one of [duckduckgo_search, Calculator]
|
||||
Action Input: the input to the action
|
||||
Observation: the result of the action
|
||||
... (this Thought/Action/Action Input/Observation can repeat N times)
|
||||
Thought: I now know the final answer
|
||||
Final Answer: the final answer to the original input question
|
||||
|
||||
Begin!
|
||||
|
||||
Question: Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?
|
||||
Thought:First, I need to find out who directed the film Oppenheimer in 2023 and their birth date to calculate their age.
|
||||
Action: duckduckgo_search
|
||||
Action Input: "Director of the 2023 film Oppenheimer"
|
||||
Observation: Oppenheimer: Directed by Christopher Nolan. With Cillian Murphy, Emily Blunt, Robert Downey Jr., Alden Ehrenreich. The story of American scientist J. Robert Oppenheimer and his role in the development of the atomic bomb. In Christopher Nolan's new film, "Oppenheimer," Cillian Murphy stars as J. Robert ... 2023, 12:16 p.m. ET. ... including his role as the director of the Manhattan Engineer District, better ... J Robert Oppenheimer was the director of the secret Los Alamos Laboratory. It was established under US president Franklin D Roosevelt as part of the Manhattan Project to build the first atomic bomb. He oversaw the first atomic bomb detonation in the New Mexico desert in July 1945, code-named "Trinity". In this opening salvo of 2023's Oscar battle, Nolan has enjoined a star-studded cast for a retelling of the brilliant and haunted life of J. Robert Oppenheimer, the American physicist whose... Oppenheimer is a 2023 epic biographical thriller film written and directed by Christopher Nolan.It is based on the 2005 biography American Prometheus by Kai Bird and Martin J. Sherwin about J. Robert Oppenheimer, a theoretical physicist who was pivotal in developing the first nuclear weapons as part of the Manhattan Project and thereby ushering in the Atomic Age.
|
||||
Thought:The director of the 2023 film Oppenheimer is Christopher Nolan. Now I need to find out his birth date to calculate his age.
|
||||
Action: duckduckgo_search
|
||||
Action Input: "Christopher Nolan birth date"
|
||||
Observation: July 30, 1970 (age 52) London England Notable Works: "Dunkirk" "Tenet" "The Prestige" See all related content → Recent News Jul. 13, 2023, 11:11 AM ET (AP) Cillian Murphy, playing Oppenheimer, finally gets to lead a Christopher Nolan film Christopher Edward Nolan CBE (born 30 July 1970) is a British and American filmmaker. Known for his Hollywood blockbusters with complex storytelling, Nolan is considered a leading filmmaker of the 21st century. His films have grossed $5 billion worldwide. The recipient of many accolades, he has been nominated for five Academy Awards, five BAFTA Awards and six Golden Globe Awards. Christopher Nolan is currently 52 according to his birthdate July 30, 1970 Sun Sign Leo Born Place Westminster, London, England, United Kingdom Residence Los Angeles, California, United States Nationality Education Chris attended Haileybury and Imperial Service College, in Hertford Heath, Hertfordshire. Christopher Nolan's next movie will study the man who developed the atomic bomb, J. Robert Oppenheimer. Here's the release date, plot, trailers & more. July 2023 sees the release of Christopher Nolan's new film, Oppenheimer, his first movie since 2020's Tenet and his split from Warner Bros. Billed as an epic thriller about "the man who ...
|
||||
Thought:Christopher Nolan was born on July 30, 1970. Now I need to calculate his age in 2023 and then convert it into days.
|
||||
Action: Calculator
|
||||
Action Input: (2023 - 1970) * 365
|
||||
Observation: Answer: 19345
|
||||
Thought:
|
||||
|
||||
> Finished chain.
|
||||
I now know the final answer
|
||||
Final Answer: The director of the 2023 film Oppenheimer is Christopher Nolan and he is 53 years old in 2023. His age in days is 19345 days.
|
||||
|
||||
> Finished chain.
|
||||
|
||||
|
||||
'The director of the 2023 film Oppenheimer is Christopher Nolan and he is 53 years old in 2023. His age in days is 19345 days.'
|
||||
```
|
||||
|
||||
</CodeOutputBlock>
|
||||
|
||||
</details>
|
||||
|
||||
### `Chain(..., verbose=True)`
|
||||
|
||||
You can also scope verbosity down to a single object, in which case only the inputs and outputs to that object are printed (along with any additional callbacks calls made specifically by that object).
|
||||
|
||||
|
||||
```python
|
||||
# Passing verbose=True to initialize_agent will pass that along to the AgentExecutor (which is a Chain).
|
||||
agent = initialize_agent(
|
||||
tools,
|
||||
llm,
|
||||
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
|
||||
verbose=True,
|
||||
)
|
||||
|
||||
agent.run("Who directed the 2023 film Oppenheimer and what is their age? What is their age in days (assume 365 days per year)?")
|
||||
```
|
||||
|
||||
<details> <summary>Console output</summary>
|
||||
|
||||
<CodeOutputBlock lang="python">
|
||||
|
||||
```
|
||||
> Entering new AgentExecutor chain...
|
||||
First, I need to find out who directed the film Oppenheimer in 2023 and their birth date. Then, I can calculate their age in years and days.
|
||||
Action: duckduckgo_search
|
||||
Action Input: "Director of 2023 film Oppenheimer"
|
||||
Observation: Oppenheimer: Directed by Christopher Nolan. With Cillian Murphy, Emily Blunt, Robert Downey Jr., Alden Ehrenreich. The story of American scientist J. Robert Oppenheimer and his role in the development of the atomic bomb. In Christopher Nolan's new film, "Oppenheimer," Cillian Murphy stars as J. Robert Oppenheimer, the American physicist who oversaw the Manhattan Project in Los Alamos, N.M. Universal Pictures... J Robert Oppenheimer was the director of the secret Los Alamos Laboratory. It was established under US president Franklin D Roosevelt as part of the Manhattan Project to build the first atomic bomb. He oversaw the first atomic bomb detonation in the New Mexico desert in July 1945, code-named "Trinity". A Review of Christopher Nolan's new film 'Oppenheimer' , the story of the man who fathered the Atomic Bomb. Cillian Murphy leads an all star cast ... Release Date: July 21, 2023. Director ... For his new film, "Oppenheimer," starring Cillian Murphy and Emily Blunt, director Christopher Nolan set out to build an entire 1940s western town.
|
||||
Thought:The director of the 2023 film Oppenheimer is Christopher Nolan. Now I need to find out his birth date to calculate his age.
|
||||
Action: duckduckgo_search
|
||||
Action Input: "Christopher Nolan birth date"
|
||||
Observation: July 30, 1970 (age 52) London England Notable Works: "Dunkirk" "Tenet" "The Prestige" See all related content → Recent News Jul. 13, 2023, 11:11 AM ET (AP) Cillian Murphy, playing Oppenheimer, finally gets to lead a Christopher Nolan film Christopher Edward Nolan CBE (born 30 July 1970) is a British and American filmmaker. Known for his Hollywood blockbusters with complex storytelling, Nolan is considered a leading filmmaker of the 21st century. His films have grossed $5 billion worldwide. The recipient of many accolades, he has been nominated for five Academy Awards, five BAFTA Awards and six Golden Globe Awards. Christopher Nolan is currently 52 according to his birthdate July 30, 1970 Sun Sign Leo Born Place Westminster, London, England, United Kingdom Residence Los Angeles, California, United States Nationality Education Chris attended Haileybury and Imperial Service College, in Hertford Heath, Hertfordshire. Christopher Nolan's next movie will study the man who developed the atomic bomb, J. Robert Oppenheimer. Here's the release date, plot, trailers & more. Date of Birth: 30 July 1970 . ... Christopher Nolan is a British-American film director, producer, and screenwriter. His films have grossed more than US$5 billion worldwide, and have garnered 11 Academy Awards from 36 nominations. ...
|
||||
Thought:Christopher Nolan was born on July 30, 1970. Now I can calculate his age in years and then in days.
|
||||
Action: Calculator
|
||||
Action Input: {"operation": "subtract", "operands": [2023, 1970]}
|
||||
Observation: Answer: 53
|
||||
Thought:Christopher Nolan is 53 years old in 2023. Now I need to calculate his age in days.
|
||||
Action: Calculator
|
||||
Action Input: {"operation": "multiply", "operands": [53, 365]}
|
||||
Observation: Answer: 19345
|
||||
Thought:I now know the final answer
|
||||
Final Answer: The director of the 2023 film Oppenheimer is Christopher Nolan. He is 53 years old in 2023, which is approximately 19345 days.
|
||||
|
||||
> Finished chain.
|
||||
|
||||
|
||||
'The director of the 2023 film Oppenheimer is Christopher Nolan. He is 53 years old in 2023, which is approximately 19345 days.'
|
||||
```
|
||||
|
||||
</CodeOutputBlock>
|
||||
|
||||
</details>
|
||||
|
||||
## Other callbacks
|
||||
|
||||
`Callbacks` are what we use to execute any functionality within a component outside the primary component logic. All of the above solutions use `Callbacks` under the hood to log intermediate steps of components. There's a number of `Callbacks` relevant for debugging that come with LangChain out of the box, like the [FileCallbackHandler](/docs/modules/callbacks/how_to/filecallbackhandler). You can also implement your own callbacks to execute custom functionality.
|
||||
|
||||
See here for more info on [Callbacks](/docs/modules/callbacks/), how to use them, and customize them.
|
||||
|
|
@ -1,115 +0,0 @@
|
|||
# Deployment
|
||||
|
||||
In today's fast-paced technological landscape, the use of Large Language Models (LLMs) is rapidly expanding. As a result, it's crucial for developers to understand how to effectively deploy these models in production environments. LLM interfaces typically fall into two categories:
|
||||
|
||||
- **Case 1: Utilizing External LLM Providers (OpenAI, Anthropic, etc.)**
|
||||
In this scenario, most of the computational burden is handled by the LLM providers, while LangChain simplifies the implementation of business logic around these services. This approach includes features such as prompt templating, chat message generation, caching, vector embedding database creation, preprocessing, etc.
|
||||
|
||||
- **Case 2: Self-hosted Open-Source Models**
|
||||
Alternatively, developers can opt to use smaller, yet comparably capable, self-hosted open-source LLM models. This approach can significantly decrease costs, latency, and privacy concerns associated with transferring data to external LLM providers.
|
||||
|
||||
Regardless of the framework that forms the backbone of your product, deploying LLM applications comes with its own set of challenges. It's vital to understand the trade-offs and key considerations when evaluating serving frameworks.
|
||||
|
||||
## Outline
|
||||
|
||||
This guide aims to provide a comprehensive overview of the requirements for deploying LLMs in a production setting, focusing on:
|
||||
|
||||
- **Designing a Robust LLM Application Service**
|
||||
- **Maintaining Cost-Efficiency**
|
||||
- **Ensuring Rapid Iteration**
|
||||
|
||||
Understanding these components is crucial when assessing serving systems. LangChain integrates with several open-source projects designed to tackle these issues, providing a robust framework for productionizing your LLM applications. Some notable frameworks include:
|
||||
|
||||
- [Ray Serve](/docs/ecosystem/integrations/ray_serve.html)
|
||||
- [BentoML](https://github.com/bentoml/BentoML)
|
||||
- [OpenLLM](/docs/ecosystem/integrations/openllm.html)
|
||||
- [Modal](/docs/ecosystem/integrations/modal.html)
|
||||
- [Jina](/docs/ecosystem/integrations/jina.html#deployment)
|
||||
|
||||
These links will provide further information on each ecosystem, assisting you in finding the best fit for your LLM deployment needs.
|
||||
|
||||
## Designing a Robust LLM Application Service
|
||||
|
||||
When deploying an LLM service in production, it's imperative to provide a seamless user experience free from outages. Achieving 24/7 service availability involves creating and maintaining several sub-systems surrounding your application.
|
||||
|
||||
### Monitoring
|
||||
|
||||
Monitoring forms an integral part of any system running in a production environment. In the context of LLMs, it is essential to monitor both performance and quality metrics.
|
||||
|
||||
**Performance Metrics:** These metrics provide insights into the efficiency and capacity of your model. Here are some key examples:
|
||||
|
||||
- Query per second (QPS): This measures the number of queries your model processes in a second, offering insights into its utilization.
|
||||
- Latency: This metric quantifies the delay from when your client sends a request to when they receive a response.
|
||||
- Tokens Per Second (TPS): This represents the number of tokens your model can generate in a second.
|
||||
|
||||
**Quality Metrics:** These metrics are typically customized according to the business use-case. For instance, how does the output of your system compare to a baseline, such as a previous version? Although these metrics can be calculated offline, you need to log the necessary data to use them later.
|
||||
|
||||
### Fault tolerance
|
||||
|
||||
Your application may encounter errors such as exceptions in your model inference or business logic code, causing failures and disrupting traffic. Other potential issues could arise from the machine running your application, such as unexpected hardware breakdowns or loss of spot-instances during high-demand periods. One way to mitigate these risks is by increasing redundancy through replica scaling and implementing recovery mechanisms for failed replicas. However, model replicas aren't the only potential points of failure. It's essential to build resilience against various failures that could occur at any point in your stack.
|
||||
|
||||
|
||||
### Zero down time upgrade
|
||||
|
||||
System upgrades are often necessary but can result in service disruptions if not handled correctly. One way to prevent downtime during upgrades is by implementing a smooth transition process from the old version to the new one. Ideally, the new version of your LLM service is deployed, and traffic gradually shifts from the old to the new version, maintaining a constant QPS throughout the process.
|
||||
|
||||
|
||||
### Load balancing
|
||||
|
||||
Load balancing, in simple terms, is a technique to distribute work evenly across multiple computers, servers, or other resources to optimize the utilization of the system, maximize throughput, minimize response time, and avoid overload of any single resource. Think of it as a traffic officer directing cars (requests) to different roads (servers) so that no single road becomes too congested.
|
||||
|
||||
There are several strategies for load balancing. For example, one common method is the *Round Robin* strategy, where each request is sent to the next server in line, cycling back to the first when all servers have received a request. This works well when all servers are equally capable. However, if some servers are more powerful than others, you might use a *Weighted Round Robin* or *Least Connections* strategy, where more requests are sent to the more powerful servers, or to those currently handling the fewest active requests. Let's imagine you're running a LLM chain. If your application becomes popular, you could have hundreds or even thousands of users asking questions at the same time. If one server gets too busy (high load), the load balancer would direct new requests to another server that is less busy. This way, all your users get a timely response and the system remains stable.
|
||||
|
||||
|
||||
|
||||
## Maintaining Cost-Efficiency and Scalability
|
||||
|
||||
Deploying LLM services can be costly, especially when you're handling a large volume of user interactions. Charges by LLM providers are usually based on tokens used, making a chat system inference on these models potentially expensive. However, several strategies can help manage these costs without compromising the quality of the service.
|
||||
|
||||
|
||||
### Self-hosting models
|
||||
|
||||
Several smaller and open-source LLMs are emerging to tackle the issue of reliance on LLM providers. Self-hosting allows you to maintain similar quality to LLM provider models while managing costs. The challenge lies in building a reliable, high-performing LLM serving system on your own machines.
|
||||
|
||||
### Resource Management and Auto-Scaling
|
||||
|
||||
Computational logic within your application requires precise resource allocation. For instance, if part of your traffic is served by an OpenAI endpoint and another part by a self-hosted model, it's crucial to allocate suitable resources for each. Auto-scaling—adjusting resource allocation based on traffic—can significantly impact the cost of running your application. This strategy requires a balance between cost and responsiveness, ensuring neither resource over-provisioning nor compromised application responsiveness.
|
||||
|
||||
### Utilizing Spot Instances
|
||||
|
||||
On platforms like AWS, spot instances offer substantial cost savings, typically priced at about a third of on-demand instances. The trade-off is a higher crash rate, necessitating a robust fault-tolerance mechanism for effective use.
|
||||
|
||||
### Independent Scaling
|
||||
|
||||
When self-hosting your models, you should consider independent scaling. For example, if you have two translation models, one fine-tuned for French and another for Spanish, incoming requests might necessitate different scaling requirements for each.
|
||||
|
||||
### Batching requests
|
||||
|
||||
In the context of Large Language Models, batching requests can enhance efficiency by better utilizing your GPU resources. GPUs are inherently parallel processors, designed to handle multiple tasks simultaneously. If you send individual requests to the model, the GPU might not be fully utilized as it's only working on a single task at a time. On the other hand, by batching requests together, you're allowing the GPU to work on multiple tasks at once, maximizing its utilization and improving inference speed. This not only leads to cost savings but can also improve the overall latency of your LLM service.
|
||||
|
||||
|
||||
In summary, managing costs while scaling your LLM services requires a strategic approach. Utilizing self-hosting models, managing resources effectively, employing auto-scaling, using spot instances, independently scaling models, and batching requests are key strategies to consider. Open-source libraries such as Ray Serve and BentoML are designed to deal with these complexities.
|
||||
|
||||
|
||||
|
||||
## Ensuring Rapid Iteration
|
||||
|
||||
The LLM landscape is evolving at an unprecedented pace, with new libraries and model architectures being introduced constantly. Consequently, it's crucial to avoid tying yourself to a solution specific to one particular framework. This is especially relevant in serving, where changes to your infrastructure can be time-consuming, expensive, and risky. Strive for infrastructure that is not locked into any specific machine learning library or framework, but instead offers a general-purpose, scalable serving layer. Here are some aspects where flexibility plays a key role:
|
||||
|
||||
### Model composition
|
||||
|
||||
Deploying systems like LangChain demands the ability to piece together different models and connect them via logic. Take the example of building a natural language input SQL query engine. Querying an LLM and obtaining the SQL command is only part of the system. You need to extract metadata from the connected database, construct a prompt for the LLM, run the SQL query on an engine, collect and feed back the response to the LLM as the query runs, and present the results to the user. This demonstrates the need to seamlessly integrate various complex components built in Python into a dynamic chain of logical blocks that can be served together.
|
||||
|
||||
## Cloud providers
|
||||
|
||||
Many hosted solutions are restricted to a single cloud provider, which can limit your options in today's multi-cloud world. Depending on where your other infrastructure components are built, you might prefer to stick with your chosen cloud provider.
|
||||
|
||||
|
||||
## Infrastructure as Code (IaC)
|
||||
|
||||
Rapid iteration also involves the ability to recreate your infrastructure quickly and reliably. This is where Infrastructure as Code (IaC) tools like Terraform, CloudFormation, or Kubernetes YAML files come into play. They allow you to define your infrastructure in code files, which can be version controlled and quickly deployed, enabling faster and more reliable iterations.
|
||||
|
||||
|
||||
## CI/CD
|
||||
|
||||
In a fast-paced environment, implementing CI/CD pipelines can significantly speed up the iteration process. They help automate the testing and deployment of your LLM applications, reducing the risk of errors and enabling faster feedback and iteration.
|
||||
|
|
@ -1,81 +0,0 @@
|
|||
# Template repos
|
||||
|
||||
So, you've created a really cool chain - now what? How do you deploy it and make it easily shareable with the world?
|
||||
|
||||
This section covers several options for that. Note that these options are meant for quick deployment of prototypes and demos, not for production systems. If you need help with the deployment of a production system, please contact us directly.
|
||||
|
||||
What follows is a list of template GitHub repositories designed to be easily forked and modified to use your chain. This list is far from exhaustive, and we are EXTREMELY open to contributions here.
|
||||
|
||||
## [Streamlit](https://github.com/hwchase17/langchain-streamlit-template)
|
||||
|
||||
This repo serves as a template for how to deploy a LangChain with Streamlit.
|
||||
It implements a chatbot interface.
|
||||
It also contains instructions for how to deploy this app on the Streamlit platform.
|
||||
|
||||
## [Gradio (on Hugging Face)](https://github.com/hwchase17/langchain-gradio-template)
|
||||
|
||||
This repo serves as a template for how deploy a LangChain with Gradio.
|
||||
It implements a chatbot interface, with a "Bring-Your-Own-Token" approach (nice for not wracking up big bills).
|
||||
It also contains instructions for how to deploy this app on the Hugging Face platform.
|
||||
This is heavily influenced by James Weaver's [excellent examples](https://huggingface.co/JavaFXpert).
|
||||
|
||||
## [Chainlit](https://github.com/Chainlit/cookbook)
|
||||
|
||||
This repo is a cookbook explaining how to visualize and deploy LangChain agents with Chainlit.
|
||||
You create ChatGPT-like UIs with Chainlit. Some of the key features include intermediary steps visualisation, element management & display (images, text, carousel, etc.) as well as cloud deployment.
|
||||
Chainlit [doc](https://docs.chainlit.io/langchain) on the integration with LangChain
|
||||
|
||||
## [Beam](https://github.com/slai-labs/get-beam/tree/main/examples/langchain-question-answering)
|
||||
|
||||
This repo serves as a template for how deploy a LangChain with [Beam](https://beam.cloud).
|
||||
|
||||
It implements a Question Answering app and contains instructions for deploying the app as a serverless REST API.
|
||||
|
||||
## [Vercel](https://github.com/homanp/vercel-langchain)
|
||||
|
||||
A minimal example on how to run LangChain on Vercel using Flask.
|
||||
|
||||
## [FastAPI + Vercel](https://github.com/msoedov/langcorn)
|
||||
|
||||
A minimal example on how to run LangChain on Vercel using FastAPI and LangCorn/Uvicorn.
|
||||
|
||||
## [Kinsta](https://github.com/kinsta/hello-world-langchain)
|
||||
|
||||
A minimal example on how to deploy LangChain to [Kinsta](https://kinsta.com) using Flask.
|
||||
|
||||
## [Fly.io](https://github.com/fly-apps/hello-fly-langchain)
|
||||
|
||||
A minimal example of how to deploy LangChain to [Fly.io](https://fly.io/) using Flask.
|
||||
|
||||
## [Digitalocean App Platform](https://github.com/homanp/digitalocean-langchain)
|
||||
|
||||
A minimal example on how to deploy LangChain to DigitalOcean App Platform.
|
||||
|
||||
## [CI/CD Google Cloud Build + Dockerfile + Serverless Google Cloud Run](https://github.com/g-emarco/github-assistant)
|
||||
|
||||
Boilerplate LangChain project on how to deploy to Google Cloud Run using Docker with Cloud Build CI/CD pipeline
|
||||
|
||||
## [Google Cloud Run](https://github.com/homanp/gcp-langchain)
|
||||
|
||||
A minimal example on how to deploy LangChain to Google Cloud Run.
|
||||
|
||||
## [SteamShip](https://github.com/steamship-core/steamship-langchain/)
|
||||
|
||||
This repository contains LangChain adapters for Steamship, enabling LangChain developers to rapidly deploy their apps on Steamship. This includes: production-ready endpoints, horizontal scaling across dependencies, persistent storage of app state, multi-tenancy support, etc.
|
||||
|
||||
## [Langchain-serve](https://github.com/jina-ai/langchain-serve)
|
||||
|
||||
This repository allows users to deploy any LangChain app as REST/WebSocket APIs or, as Slack Bots with ease. Benefit from the scalability and serverless architecture of Jina AI Cloud, or deploy on-premise with Kubernetes.
|
||||
|
||||
## [BentoML](https://github.com/ssheng/BentoChain)
|
||||
|
||||
This repository provides an example of how to deploy a LangChain application with [BentoML](https://github.com/bentoml/BentoML). BentoML is a framework that enables the containerization of machine learning applications as standard OCI images. BentoML also allows for the automatic generation of OpenAPI and gRPC endpoints. With BentoML, you can integrate models from all popular ML frameworks and deploy them as microservices running on the most optimal hardware and scaling independently.
|
||||
|
||||
## [OpenLLM](https://github.com/bentoml/OpenLLM)
|
||||
|
||||
OpenLLM is a platform for operating large language models (LLMs) in production. With OpenLLM, you can run inference with any open-source LLM, deploy to the cloud or on-premises, and build powerful AI apps. It supports a wide range of open-source LLMs, offers flexible APIs, and first-class support for LangChain and BentoML.
|
||||
See OpenLLM's [integration doc](https://github.com/bentoml/OpenLLM#%EF%B8%8F-integrations) for usage with LangChain.
|
||||
|
||||
## [Databutton](https://databutton.com/home?new-data-app=true)
|
||||
|
||||
These templates serve as examples of how to build, deploy, and share LangChain applications using Databutton. You can create user interfaces with Streamlit, automate tasks by scheduling Python code, and store files and data in the built-in store. Examples include a Chatbot interface with conversational memory, a Personal search engine, and a starter template for LangChain apps. Deploying and sharing is just one click away.
|
||||
|
|
@ -1,280 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "657d2c8c-54b4-42a3-9f02-bdefa0ed6728",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Custom Pairwise Evaluator\n",
|
||||
"\n",
|
||||
"You can make your own pairwise string evaluators by inheriting from `PairwiseStringEvaluator` class and overwriting the `_evaluate_string_pairs` method (and the `_aevaluate_string_pairs` method if you want to use the evaluator asynchronously).\n",
|
||||
"\n",
|
||||
"In this example, you will make a simple custom evaluator that just returns whether the first prediction has more whitespace tokenized 'words' than the second.\n",
|
||||
"\n",
|
||||
"You can check out the reference docs for the [PairwiseStringEvaluator interface](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.schema.PairwiseStringEvaluator.html#langchain.evaluation.schema.PairwiseStringEvaluator) for more info.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "93f3a653-d198-4291-973c-8d1adba338b2",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import Optional, Any\n",
|
||||
"from langchain.evaluation import PairwiseStringEvaluator\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class LengthComparisonPairwiseEvalutor(PairwiseStringEvaluator):\n",
|
||||
" \"\"\"\n",
|
||||
" Custom evaluator to compare two strings.\n",
|
||||
" \"\"\"\n",
|
||||
"\n",
|
||||
" def _evaluate_string_pairs(\n",
|
||||
" self,\n",
|
||||
" *,\n",
|
||||
" prediction: str,\n",
|
||||
" prediction_b: str,\n",
|
||||
" reference: Optional[str] = None,\n",
|
||||
" input: Optional[str] = None,\n",
|
||||
" **kwargs: Any,\n",
|
||||
" ) -> dict:\n",
|
||||
" score = int(len(prediction.split()) > len(prediction_b.split()))\n",
|
||||
" return {\"score\": score}"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "7d4a77c3-07a7-4076-8e7f-f9bca0d6c290",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 1}"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator = LengthComparisonPairwiseEvalutor()\n",
|
||||
"\n",
|
||||
"evaluator.evaluate_string_pairs(\n",
|
||||
" prediction=\"The quick brown fox jumped over the lazy dog.\",\n",
|
||||
" prediction_b=\"The quick brown fox jumped over the dog.\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d90f128f-6f49-42a1-b05a-3aea568ee03b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## LLM-Based Example\n",
|
||||
"\n",
|
||||
"That example was simple to illustrate the API, but it wasn't very useful in practice. Below, use an LLM with some custom instructions to form a simple preference scorer similar to the built-in [PairwiseStringEvalChain](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.comparison.eval_chain.PairwiseStringEvalChain.html#langchain.evaluation.comparison.eval_chain.PairwiseStringEvalChain). We will use `ChatAnthropic` for the evaluator chain."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "b4b43098-4d96-417b-a8a9-b3e75779cfe8",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# %pip install anthropic\n",
|
||||
"# %env ANTHROPIC_API_KEY=YOUR_API_KEY"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "b6e978ab-48f1-47ff-9506-e13b1a50be6e",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import Optional, Any\n",
|
||||
"from langchain.evaluation import PairwiseStringEvaluator\n",
|
||||
"from langchain.chat_models import ChatAnthropic\n",
|
||||
"from langchain.chains import LLMChain\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class CustomPreferenceEvaluator(PairwiseStringEvaluator):\n",
|
||||
" \"\"\"\n",
|
||||
" Custom evaluator to compare two strings using a custom LLMChain.\n",
|
||||
" \"\"\"\n",
|
||||
"\n",
|
||||
" def __init__(self) -> None:\n",
|
||||
" llm = ChatAnthropic(model=\"claude-2\", temperature=0)\n",
|
||||
" self.eval_chain = LLMChain.from_string(\n",
|
||||
" llm,\n",
|
||||
" \"\"\"Which option is preferred? Do not take order into account. Evaluate based on accuracy and helpfulness. If neither is preferred, respond with C. Provide your reasoning, then finish with Preference: A/B/C\n",
|
||||
"\n",
|
||||
"Input: How do I get the path of the parent directory in python 3.8?\n",
|
||||
"Option A: You can use the following code:\n",
|
||||
"```python\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n",
|
||||
"```\n",
|
||||
"Option B: You can use the following code:\n",
|
||||
"```python\n",
|
||||
"from pathlib import Path\n",
|
||||
"Path(__file__).absolute().parent\n",
|
||||
"```\n",
|
||||
"Reasoning: Both options return the same result. However, since option B is more concise and easily understand, it is preferred.\n",
|
||||
"Preference: B\n",
|
||||
"\n",
|
||||
"Which option is preferred? Do not take order into account. Evaluate based on accuracy and helpfulness. If neither is preferred, respond with C. Provide your reasoning, then finish with Preference: A/B/C\n",
|
||||
"Input: {input}\n",
|
||||
"Option A: {prediction}\n",
|
||||
"Option B: {prediction_b}\n",
|
||||
"Reasoning:\"\"\",\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" @property\n",
|
||||
" def requires_input(self) -> bool:\n",
|
||||
" return True\n",
|
||||
"\n",
|
||||
" @property\n",
|
||||
" def requires_reference(self) -> bool:\n",
|
||||
" return False\n",
|
||||
"\n",
|
||||
" def _evaluate_string_pairs(\n",
|
||||
" self,\n",
|
||||
" *,\n",
|
||||
" prediction: str,\n",
|
||||
" prediction_b: str,\n",
|
||||
" reference: Optional[str] = None,\n",
|
||||
" input: Optional[str] = None,\n",
|
||||
" **kwargs: Any,\n",
|
||||
" ) -> dict:\n",
|
||||
" result = self.eval_chain(\n",
|
||||
" {\n",
|
||||
" \"input\": input,\n",
|
||||
" \"prediction\": prediction,\n",
|
||||
" \"prediction_b\": prediction_b,\n",
|
||||
" \"stop\": [\"Which option is preferred?\"],\n",
|
||||
" },\n",
|
||||
" **kwargs,\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" response_text = result[\"text\"]\n",
|
||||
" reasoning, preference = response_text.split(\"Preference:\", maxsplit=1)\n",
|
||||
" preference = preference.strip()\n",
|
||||
" score = 1.0 if preference == \"A\" else (0.0 if preference == \"B\" else None)\n",
|
||||
" return {\"reasoning\": reasoning.strip(), \"value\": preference, \"score\": score}"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "5cbd8b1d-2cb0-4f05-b435-a1a00074d94a",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"evaluator = CustomPreferenceEvaluator()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "2c0a7fb7-b976-4443-9f0e-e707a6dfbdf7",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'reasoning': 'Option B is preferred over option A for importing from a relative directory, because it is more straightforward and concise.\\n\\nOption A uses the importlib module, which allows importing a module by specifying the full name as a string. While this works, it is less clear compared to option B.\\n\\nOption B directly imports from the relative path using dot notation, which clearly shows that it is a relative import. This is the recommended way to do relative imports in Python.\\n\\nIn summary, option B is more accurate and helpful as it uses the standard Python relative import syntax.',\n",
|
||||
" 'value': 'B',\n",
|
||||
" 'score': 0.0}"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator.evaluate_string_pairs(\n",
|
||||
" input=\"How do I import from a relative directory?\",\n",
|
||||
" prediction=\"use importlib! importlib.import_module('.my_package', '.')\",\n",
|
||||
" prediction_b=\"from .sibling import foo\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "f13a1346-7dbe-451d-b3a3-99e8fc7b753b",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"CustomPreferenceEvaluator requires an input string.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Setting requires_input to return True adds additional validation to avoid returning a grade when insufficient data is provided to the chain.\n",
|
||||
"\n",
|
||||
"try:\n",
|
||||
" evaluator.evaluate_string_pairs(\n",
|
||||
" prediction=\"use importlib! importlib.import_module('.my_package', '.')\",\n",
|
||||
" prediction_b=\"from .sibling import foo\",\n",
|
||||
" )\n",
|
||||
"except ValueError as e:\n",
|
||||
" print(e)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "e7829cc3-ebd1-4628-ae97-15166202e9cc",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,232 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"# Pairwise Embedding Distance \n",
|
||||
"\n",
|
||||
"One way to measure the similarity (or dissimilarity) between two predictions on a shared or similar input is to embed the predictions and compute a vector distance between the two embeddings.<a name=\"cite_ref-1\"></a>[<sup>[1]</sup>](#cite_note-1)\n",
|
||||
"\n",
|
||||
"You can load the `pairwise_embedding_distance` evaluator to do this.\n",
|
||||
"\n",
|
||||
"**Note:** This returns a **distance** score, meaning that the lower the number, the **more** similar the outputs are, according to their embedded representation.\n",
|
||||
"\n",
|
||||
"Check out the reference docs for the [PairwiseEmbeddingDistanceEvalChain](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.embedding_distance.base.PairwiseEmbeddingDistanceEvalChain.html#langchain.evaluation.embedding_distance.base.PairwiseEmbeddingDistanceEvalChain) for more info."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.evaluation import load_evaluator\n",
|
||||
"\n",
|
||||
"evaluator = load_evaluator(\"pairwise_embedding_distance\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.0966466944859925}"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator.evaluate_string_pairs(\n",
|
||||
" prediction=\"Seattle is hot in June\", prediction_b=\"Seattle is cool in June.\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.03761174337464557}"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator.evaluate_string_pairs(\n",
|
||||
" prediction=\"Seattle is warm in June\", prediction_b=\"Seattle is cool in June.\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Select the Distance Metric\n",
|
||||
"\n",
|
||||
"By default, the evalutor uses cosine distance. You can choose a different distance metric if you'd like. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[<EmbeddingDistance.COSINE: 'cosine'>,\n",
|
||||
" <EmbeddingDistance.EUCLIDEAN: 'euclidean'>,\n",
|
||||
" <EmbeddingDistance.MANHATTAN: 'manhattan'>,\n",
|
||||
" <EmbeddingDistance.CHEBYSHEV: 'chebyshev'>,\n",
|
||||
" <EmbeddingDistance.HAMMING: 'hamming'>]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.evaluation import EmbeddingDistance\n",
|
||||
"\n",
|
||||
"list(EmbeddingDistance)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"evaluator = load_evaluator(\n",
|
||||
" \"pairwise_embedding_distance\", distance_metric=EmbeddingDistance.EUCLIDEAN\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Select Embeddings to Use\n",
|
||||
"\n",
|
||||
"The constructor uses `OpenAI` embeddings by default, but you can configure this however you want. Below, use huggingface local embeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import HuggingFaceEmbeddings\n",
|
||||
"\n",
|
||||
"embedding_model = HuggingFaceEmbeddings()\n",
|
||||
"hf_evaluator = load_evaluator(\"pairwise_embedding_distance\", embeddings=embedding_model)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.5486443280477362}"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"hf_evaluator.evaluate_string_pairs(\n",
|
||||
" prediction=\"Seattle is hot in June\", prediction_b=\"Seattle is cool in June.\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.21018880025138598}"
|
||||
]
|
||||
},
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"hf_evaluator.evaluate_string_pairs(\n",
|
||||
" prediction=\"Seattle is warm in June\", prediction_b=\"Seattle is cool in June.\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"<a name=\"cite_note-1\"></a><i>1. Note: When it comes to semantic similarity, this often gives better results than older string distance metrics (such as those in the `PairwiseStringDistanceEvalChain`), though it tends to be less reliable than evaluators that use the LLM directly (such as the `PairwiseStringEvalChain`) </i>"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,381 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2da95378",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Pairwise String Comparison\n",
|
||||
"\n",
|
||||
"Often you will want to compare predictions of an LLM, Chain, or Agent for a given input. The `StringComparison` evaluators facilitate this so you can answer questions like:\n",
|
||||
"\n",
|
||||
"- Which LLM or prompt produces a preferred output for a given question?\n",
|
||||
"- Which examples should I include for few-shot example selection?\n",
|
||||
"- Which output is better to include for fintetuning?\n",
|
||||
"\n",
|
||||
"The simplest and often most reliable automated way to choose a preferred prediction for a given input is to use the `pairwise_string` evaluator.\n",
|
||||
"\n",
|
||||
"Check out the reference docs for the [PairwiseStringEvalChain](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.comparison.eval_chain.PairwiseStringEvalChain.html#langchain.evaluation.comparison.eval_chain.PairwiseStringEvalChain) for more info."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "f6790c46",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.evaluation import load_evaluator\n",
|
||||
"\n",
|
||||
"evaluator = load_evaluator(\"labeled_pairwise_string\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "49ad9139",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'reasoning': 'Both responses are relevant to the question asked, as they both provide a numerical answer to the question about the number of dogs in the park. However, Response A is incorrect according to the reference answer, which states that there are four dogs. Response B, on the other hand, is correct as it matches the reference answer. Neither response demonstrates depth of thought, as they both simply provide a numerical answer without any additional information or context. \\n\\nBased on these criteria, Response B is the better response.\\n',\n",
|
||||
" 'value': 'B',\n",
|
||||
" 'score': 0}"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator.evaluate_string_pairs(\n",
|
||||
" prediction=\"there are three dogs\",\n",
|
||||
" prediction_b=\"4\",\n",
|
||||
" input=\"how many dogs are in the park?\",\n",
|
||||
" reference=\"four\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "7491d2e6-4e77-4b17-be6b-7da966785c1d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Methods\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"The pairwise string evaluator can be called using [evaluate_string_pairs](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.comparison.eval_chain.PairwiseStringEvalChain.html#langchain.evaluation.comparison.eval_chain.PairwiseStringEvalChain.evaluate_string_pairs) (or async [aevaluate_string_pairs](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.comparison.eval_chain.PairwiseStringEvalChain.html#langchain.evaluation.comparison.eval_chain.PairwiseStringEvalChain.aevaluate_string_pairs)) methods, which accept:\n",
|
||||
"\n",
|
||||
"- prediction (str) – The predicted response of the first model, chain, or prompt.\n",
|
||||
"- prediction_b (str) – The predicted response of the second model, chain, or prompt.\n",
|
||||
"- input (str) – The input question, prompt, or other text.\n",
|
||||
"- reference (str) – (Only for the labeled_pairwise_string variant) The reference response.\n",
|
||||
"\n",
|
||||
"They return a dictionary with the following values:\n",
|
||||
"- value: 'A' or 'B', indicating whether `prediction` or `prediction_b` is preferred, respectively\n",
|
||||
"- score: Integer 0 or 1 mapped from the 'value', where a score of 1 would mean that the first `prediction` is preferred, and a score of 0 would mean `prediction_b` is preferred.\n",
|
||||
"- reasoning: String \"chain of thought reasoning\" from the LLM generated prior to creating the score"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ed353b93-be71-4479-b9c0-8c97814c2e58",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Without References\n",
|
||||
"\n",
|
||||
"When references aren't available, you can still predict the preferred response.\n",
|
||||
"The results will reflect the evaluation model's preference, which is less reliable and may result\n",
|
||||
"in preferences that are factually incorrect."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "586320da",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.evaluation import load_evaluator\n",
|
||||
"\n",
|
||||
"evaluator = load_evaluator(\"pairwise_string\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "7f56c76e-a39b-4509-8b8a-8a2afe6c3da1",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'reasoning': 'Both responses are correct and relevant to the question. However, Response B is more helpful and insightful as it provides a more detailed explanation of what addition is. Response A is correct but lacks depth as it does not explain what the operation of addition entails. \\n\\nFinal Decision: [[B]]',\n",
|
||||
" 'value': 'B',\n",
|
||||
" 'score': 0}"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator.evaluate_string_pairs(\n",
|
||||
" prediction=\"Addition is a mathematical operation.\",\n",
|
||||
" prediction_b=\"Addition is a mathematical operation that adds two numbers to create a third number, the 'sum'.\",\n",
|
||||
" input=\"What is addition?\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4a09b21d-9851-47e8-93d3-90044b2945b0",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"## Defining the Criteria\n",
|
||||
"\n",
|
||||
"By default, the LLM is instructed to select the 'preferred' response based on helpfulness, relevance, correctness, and depth of thought. You can customize the criteria by passing in a `criteria` argument, where the criteria could take any of the following forms:\n",
|
||||
"- [`Criteria`](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.criteria.eval_chain.Criteria.html#langchain.evaluation.criteria.eval_chain.Criteria) enum or its string value - to use one of the default criteria and their descriptions\n",
|
||||
"- [Constitutional principal](https://api.python.langchain.com/en/latest/chains/langchain.chains.constitutional_ai.models.ConstitutionalPrinciple.html#langchain.chains.constitutional_ai.models.ConstitutionalPrinciple) - use one any of the constitutional principles defined in langchain\n",
|
||||
"- Dictionary: a list of custom criteria, where the key is the name of the criteria, and the value is the description.\n",
|
||||
"- A list of criteria or constitutional principles - to combine multiple criteria in one.\n",
|
||||
"\n",
|
||||
"Below is an example for determining preferred writing responses based on a custom style."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "8539e7d9-f7b0-4d32-9c45-593a7915c093",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"custom_criteria = {\n",
|
||||
" \"simplicity\": \"Is the language straightforward and unpretentious?\",\n",
|
||||
" \"clarity\": \"Are the sentences clear and easy to understand?\",\n",
|
||||
" \"precision\": \"Is the writing precise, with no unnecessary words or details?\",\n",
|
||||
" \"truthfulness\": \"Does the writing feel honest and sincere?\",\n",
|
||||
" \"subtext\": \"Does the writing suggest deeper meanings or themes?\",\n",
|
||||
"}\n",
|
||||
"evaluator = load_evaluator(\"pairwise_string\", criteria=custom_criteria)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "fec7bde8-fbdc-4730-8366-9d90d033c181",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'reasoning': 'Response A is simple, clear, and precise. It uses straightforward language to convey a deep and sincere message about families. The metaphor of joy and sorrow as music is effective and easy to understand.\\n\\nResponse B, on the other hand, is more complex and less clear. The language is more pretentious, with words like \"domicile,\" \"resounds,\" \"abode,\" \"dissonant,\" and \"elegy.\" While it conveys a similar message to Response A, it does so in a more convoluted way. The precision is also lacking due to the use of unnecessary words and details.\\n\\nBoth responses suggest deeper meanings or themes about the shared joy and unique sorrow in families. However, Response A does so in a more effective and accessible way.\\n\\nTherefore, the better response is [[A]].',\n",
|
||||
" 'value': 'A',\n",
|
||||
" 'score': 1}"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator.evaluate_string_pairs(\n",
|
||||
" prediction=\"Every cheerful household shares a similar rhythm of joy; but sorrow, in each household, plays a unique, haunting melody.\",\n",
|
||||
" prediction_b=\"Where one finds a symphony of joy, every domicile of happiness resounds in harmonious,\"\n",
|
||||
" \" identical notes; yet, every abode of despair conducts a dissonant orchestra, each\"\n",
|
||||
" \" playing an elegy of grief that is peculiar and profound to its own existence.\",\n",
|
||||
" input=\"Write some prose about families.\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a25b60b2-627c-408a-be4b-a2e5cbc10726",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Customize the LLM\n",
|
||||
"\n",
|
||||
"By default, the loader uses `gpt-4` in the evaluation chain. You can customize this when loading."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "de84a958-1330-482b-b950-68bcf23f9e35",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatAnthropic\n",
|
||||
"\n",
|
||||
"llm = ChatAnthropic(temperature=0)\n",
|
||||
"\n",
|
||||
"evaluator = load_evaluator(\"labeled_pairwise_string\", llm=llm)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "e162153f-d50a-4a7c-a033-019dabbc954c",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'reasoning': 'Here is my assessment:\\n\\nResponse B is more helpful, insightful, and accurate than Response A. Response B simply states \"4\", which directly answers the question by providing the exact number of dogs mentioned in the reference answer. In contrast, Response A states \"there are three dogs\", which is incorrect according to the reference answer. \\n\\nIn terms of helpfulness, Response B gives the precise number while Response A provides an inaccurate guess. For relevance, both refer to dogs in the park from the question. However, Response B is more correct and factual based on the reference answer. Response A shows some attempt at reasoning but is ultimately incorrect. Response B requires less depth of thought to simply state the factual number.\\n\\nIn summary, Response B is superior in terms of helpfulness, relevance, correctness, and depth. My final decision is: [[B]]\\n',\n",
|
||||
" 'value': 'B',\n",
|
||||
" 'score': 0}"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator.evaluate_string_pairs(\n",
|
||||
" prediction=\"there are three dogs\",\n",
|
||||
" prediction_b=\"4\",\n",
|
||||
" input=\"how many dogs are in the park?\",\n",
|
||||
" reference=\"four\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e0e89c13-d0ad-4f87-8fcb-814399bafa2a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Customize the Evaluation Prompt\n",
|
||||
"\n",
|
||||
"You can use your own custom evaluation prompt to add more task-specific instructions or to instruct the evaluator to score the output.\n",
|
||||
"\n",
|
||||
"*Note: If you use a prompt that expects generates a result in a unique format, you may also have to pass in a custom output parser (`output_parser=your_parser()`) instead of the default `PairwiseStringResultOutputParser`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "fb817efa-3a4d-439d-af8c-773b89d97ec9",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.prompts import PromptTemplate\n",
|
||||
"\n",
|
||||
"prompt_template = PromptTemplate.from_template(\n",
|
||||
" \"\"\"Given the input context, which do you prefer: A or B?\n",
|
||||
"Evaluate based on the following criteria:\n",
|
||||
"{criteria}\n",
|
||||
"Reason step by step and finally, respond with either [[A]] or [[B]] on its own line.\n",
|
||||
"\n",
|
||||
"DATA\n",
|
||||
"----\n",
|
||||
"input: {input}\n",
|
||||
"reference: {reference}\n",
|
||||
"A: {prediction}\n",
|
||||
"B: {prediction_b}\n",
|
||||
"---\n",
|
||||
"Reasoning:\n",
|
||||
"\n",
|
||||
"\"\"\"\n",
|
||||
")\n",
|
||||
"evaluator = load_evaluator(\n",
|
||||
" \"labeled_pairwise_string\", prompt=prompt_template\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "d40aa4f0-cfd5-4cb4-83c8-8d2300a04c2f",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"input_variables=['prediction', 'reference', 'prediction_b', 'input'] output_parser=None partial_variables={'criteria': 'helpfulness: Is the submission helpful, insightful, and appropriate?\\nrelevance: Is the submission referring to a real quote from the text?\\ncorrectness: Is the submission correct, accurate, and factual?\\ndepth: Does the submission demonstrate depth of thought?'} template='Given the input context, which do you prefer: A or B?\\nEvaluate based on the following criteria:\\n{criteria}\\nReason step by step and finally, respond with either [[A]] or [[B]] on its own line.\\n\\nDATA\\n----\\ninput: {input}\\nreference: {reference}\\nA: {prediction}\\nB: {prediction_b}\\n---\\nReasoning:\\n\\n' template_format='f-string' validate_template=True\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# The prompt was assigned to the evaluator\n",
|
||||
"print(evaluator.prompt)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "9467bb42-7a31-4071-8f66-9ed2c6f06dcd",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'reasoning': 'Helpfulness: Both A and B are helpful as they provide a direct answer to the question.\\nRelevance: A is relevant as it refers to the correct name of the dog from the text. B is not relevant as it provides a different name.\\nCorrectness: A is correct as it accurately states the name of the dog. B is incorrect as it provides a different name.\\nDepth: Both A and B demonstrate a similar level of depth as they both provide a straightforward answer to the question.\\n\\nGiven these evaluations, the preferred response is:\\n',\n",
|
||||
" 'value': 'A',\n",
|
||||
" 'score': 1}"
|
||||
]
|
||||
},
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator.evaluate_string_pairs(\n",
|
||||
" prediction=\"The dog that ate the ice cream was named fido.\",\n",
|
||||
" prediction_b=\"The dog's name is spot\",\n",
|
||||
" input=\"What is the name of the dog that ate the ice cream?\",\n",
|
||||
" reference=\"The dog's name is fido\",\n",
|
||||
")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,447 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Comparing Chain Outputs\n",
|
||||
"\n",
|
||||
"Suppose you have two different prompts (or LLMs). How do you know which will generate \"better\" results?\n",
|
||||
"\n",
|
||||
"One automated way to predict the preferred configuration is to use a `PairwiseStringEvaluator` like the `PairwiseStringEvalChain`<a name=\"cite_ref-1\"></a>[<sup>[1]</sup>](#cite_note-1). This chain prompts an LLM to select which output is preferred, given a specific input.\n",
|
||||
"\n",
|
||||
"For this evaluation, we will need 3 things:\n",
|
||||
"1. An evaluator\n",
|
||||
"2. A dataset of inputs\n",
|
||||
"3. 2 (or more) LLMs, Chains, or Agents to compare\n",
|
||||
"\n",
|
||||
"Then we will aggregate the restults to determine the preferred model.\n",
|
||||
"\n",
|
||||
"### Step 1. Create the Evaluator\n",
|
||||
"\n",
|
||||
"In this example, you will use gpt-4 to select which output is preferred."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.evaluation import load_evaluator\n",
|
||||
"\n",
|
||||
"eval_chain = load_evaluator(\"pairwise_string\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Step 2. Select Dataset\n",
|
||||
"\n",
|
||||
"If you already have real usage data for your LLM, you can use a representative sample. More examples\n",
|
||||
"provide more reliable results. We will use some example queries someone might have about how to use langchain here."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Found cached dataset parquet (/Users/wfh/.cache/huggingface/datasets/LangChainDatasets___parquet/LangChainDatasets--langchain-howto-queries-bbb748bbee7e77aa/0.0.0/14a00e99c0d15a23649d0db8944380ac81082d4b021f398733dd84f3a6c569a7)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "a2358d37246640ce95e0f9940194590a",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
" 0%| | 0/1 [00:00<?, ?it/s]"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.evaluation.loading import load_dataset\n",
|
||||
"\n",
|
||||
"dataset = load_dataset(\"langchain-howto-queries\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Step 3. Define Models to Compare\n",
|
||||
"\n",
|
||||
"We will be comparing two agents in this case."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain import SerpAPIWrapper\n",
|
||||
"from langchain.agents import initialize_agent, Tool\n",
|
||||
"from langchain.agents import AgentType\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Initialize the language model\n",
|
||||
"# You can add your own OpenAI API key by adding openai_api_key=\"<your_api_key>\"\n",
|
||||
"llm = ChatOpenAI(temperature=0, model=\"gpt-3.5-turbo-0613\")\n",
|
||||
"\n",
|
||||
"# Initialize the SerpAPIWrapper for search functionality\n",
|
||||
"# Replace <your_api_key> in openai_api_key=\"<your_api_key>\" with your actual SerpAPI key.\n",
|
||||
"search = SerpAPIWrapper()\n",
|
||||
"\n",
|
||||
"# Define a list of tools offered by the agent\n",
|
||||
"tools = [\n",
|
||||
" Tool(\n",
|
||||
" name=\"Search\",\n",
|
||||
" func=search.run,\n",
|
||||
" coroutine=search.arun,\n",
|
||||
" description=\"Useful when you need to answer questions about current events. You should ask targeted questions.\",\n",
|
||||
" ),\n",
|
||||
"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"functions_agent = initialize_agent(\n",
|
||||
" tools, llm, agent=AgentType.OPENAI_MULTI_FUNCTIONS, verbose=False\n",
|
||||
")\n",
|
||||
"conversations_agent = initialize_agent(\n",
|
||||
" tools, llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=False\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Step 4. Generate Responses\n",
|
||||
"\n",
|
||||
"We will generate outputs for each of the models before evaluating them."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "87277cb39a1a4726bb7cc533a24e2ea4",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
" 0%| | 0/20 [00:00<?, ?it/s]"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from tqdm.notebook import tqdm\n",
|
||||
"import asyncio\n",
|
||||
"\n",
|
||||
"results = []\n",
|
||||
"agents = [functions_agent, conversations_agent]\n",
|
||||
"concurrency_level = 6 # How many concurrent agents to run. May need to decrease if OpenAI is rate limiting.\n",
|
||||
"\n",
|
||||
"# We will only run the first 20 examples of this dataset to speed things up\n",
|
||||
"# This will lead to larger confidence intervals downstream.\n",
|
||||
"batch = []\n",
|
||||
"for example in tqdm(dataset[:20]):\n",
|
||||
" batch.extend([agent.acall(example[\"inputs\"]) for agent in agents])\n",
|
||||
" if len(batch) >= concurrency_level:\n",
|
||||
" batch_results = await asyncio.gather(*batch, return_exceptions=True)\n",
|
||||
" results.extend(list(zip(*[iter(batch_results)] * 2)))\n",
|
||||
" batch = []\n",
|
||||
"if batch:\n",
|
||||
" batch_results = await asyncio.gather(*batch, return_exceptions=True)\n",
|
||||
" results.extend(list(zip(*[iter(batch_results)] * 2)))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Step 5. Evaluate Pairs\n",
|
||||
"\n",
|
||||
"Now it's time to evaluate the results. For each agent response, run the evaluation chain to select which output is preferred (or return a tie).\n",
|
||||
"\n",
|
||||
"Randomly select the input order to reduce the likelihood that one model will be preferred just because it is presented first."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import random\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def predict_preferences(dataset, results) -> list:\n",
|
||||
" preferences = []\n",
|
||||
"\n",
|
||||
" for example, (res_a, res_b) in zip(dataset, results):\n",
|
||||
" input_ = example[\"inputs\"]\n",
|
||||
" # Flip a coin to reduce persistent position bias\n",
|
||||
" if random.random() < 0.5:\n",
|
||||
" pred_a, pred_b = res_a, res_b\n",
|
||||
" a, b = \"a\", \"b\"\n",
|
||||
" else:\n",
|
||||
" pred_a, pred_b = res_b, res_a\n",
|
||||
" a, b = \"b\", \"a\"\n",
|
||||
" eval_res = eval_chain.evaluate_string_pairs(\n",
|
||||
" prediction=pred_a[\"output\"] if isinstance(pred_a, dict) else str(pred_a),\n",
|
||||
" prediction_b=pred_b[\"output\"] if isinstance(pred_b, dict) else str(pred_b),\n",
|
||||
" input=input_,\n",
|
||||
" )\n",
|
||||
" if eval_res[\"value\"] == \"A\":\n",
|
||||
" preferences.append(a)\n",
|
||||
" elif eval_res[\"value\"] == \"B\":\n",
|
||||
" preferences.append(b)\n",
|
||||
" else:\n",
|
||||
" preferences.append(None) # No preference\n",
|
||||
" return preferences"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"preferences = predict_preferences(dataset, results)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"**Print out the ratio of preferences.**"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"OpenAI Functions Agent: 95.00%\n",
|
||||
"None: 5.00%\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from collections import Counter\n",
|
||||
"\n",
|
||||
"name_map = {\n",
|
||||
" \"a\": \"OpenAI Functions Agent\",\n",
|
||||
" \"b\": \"Structured Chat Agent\",\n",
|
||||
"}\n",
|
||||
"counts = Counter(preferences)\n",
|
||||
"pref_ratios = {k: v / len(preferences) for k, v in counts.items()}\n",
|
||||
"for k, v in pref_ratios.items():\n",
|
||||
" print(f\"{name_map.get(k)}: {v:.2%}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Estimate Confidence Intervals\n",
|
||||
"\n",
|
||||
"The results seem pretty clear, but if you want to have a better sense of how confident we are, that model \"A\" (the OpenAI Functions Agent) is the preferred model, we can calculate confidence intervals. \n",
|
||||
"\n",
|
||||
"Below, use the Wilson score to estimate the confidence interval."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from math import sqrt\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def wilson_score_interval(\n",
|
||||
" preferences: list, which: str = \"a\", z: float = 1.96\n",
|
||||
") -> tuple:\n",
|
||||
" \"\"\"Estimate the confidence interval using the Wilson score.\n",
|
||||
"\n",
|
||||
" See: https://en.wikipedia.org/wiki/Binomial_proportion_confidence_interval#Wilson_score_interval\n",
|
||||
" for more details, including when to use it and when it should not be used.\n",
|
||||
" \"\"\"\n",
|
||||
" total_preferences = preferences.count(\"a\") + preferences.count(\"b\")\n",
|
||||
" n_s = preferences.count(which)\n",
|
||||
"\n",
|
||||
" if total_preferences == 0:\n",
|
||||
" return (0, 0)\n",
|
||||
"\n",
|
||||
" p_hat = n_s / total_preferences\n",
|
||||
"\n",
|
||||
" denominator = 1 + (z**2) / total_preferences\n",
|
||||
" adjustment = (z / denominator) * sqrt(\n",
|
||||
" p_hat * (1 - p_hat) / total_preferences\n",
|
||||
" + (z**2) / (4 * total_preferences * total_preferences)\n",
|
||||
" )\n",
|
||||
" center = (p_hat + (z**2) / (2 * total_preferences)) / denominator\n",
|
||||
" lower_bound = min(max(center - adjustment, 0.0), 1.0)\n",
|
||||
" upper_bound = min(max(center + adjustment, 0.0), 1.0)\n",
|
||||
"\n",
|
||||
" return (lower_bound, upper_bound)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"The \"OpenAI Functions Agent\" would be preferred between 83.18% and 100.00% percent of the time (with 95% confidence).\n",
|
||||
"The \"Structured Chat Agent\" would be preferred between 0.00% and 16.82% percent of the time (with 95% confidence).\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"for which_, name in name_map.items():\n",
|
||||
" low, high = wilson_score_interval(preferences, which=which_)\n",
|
||||
" print(\n",
|
||||
" f'The \"{name}\" would be preferred between {low:.2%} and {high:.2%} percent of the time (with 95% confidence).'\n",
|
||||
" )"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"**Print out the p-value.**"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"The p-value is 0.00000. If the null hypothesis is true (i.e., if the selected eval chain actually has no preference between the models),\n",
|
||||
"then there is a 0.00038% chance of observing the OpenAI Functions Agent be preferred at least 19\n",
|
||||
"times out of 19 trials.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"/var/folders/gf/6rnp_mbx5914kx7qmmh7xzmw0000gn/T/ipykernel_15978/384907688.py:6: DeprecationWarning: 'binom_test' is deprecated in favour of 'binomtest' from version 1.7.0 and will be removed in Scipy 1.12.0.\n",
|
||||
" p_value = stats.binom_test(successes, n, p=0.5, alternative=\"two-sided\")\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from scipy import stats\n",
|
||||
"\n",
|
||||
"preferred_model = max(pref_ratios, key=pref_ratios.get)\n",
|
||||
"successes = preferences.count(preferred_model)\n",
|
||||
"n = len(preferences) - preferences.count(None)\n",
|
||||
"p_value = stats.binom_test(successes, n, p=0.5, alternative=\"two-sided\")\n",
|
||||
"print(\n",
|
||||
" f\"\"\"The p-value is {p_value:.5f}. If the null hypothesis is true (i.e., if the selected eval chain actually has no preference between the models),\n",
|
||||
"then there is a {p_value:.5%} chance of observing the {name_map.get(preferred_model)} be preferred at least {successes}\n",
|
||||
"times out of {n} trials.\"\"\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"<a name=\"cite_note-1\"></a>_1. Note: Automated evals are still an open research topic and are best used alongside other evaluation approaches. \n",
|
||||
"LLM preferences exhibit biases, including banal ones like the order of outputs.\n",
|
||||
"In choosing preferences, \"ground truth\" may not be taken into account, which may lead to scores that aren't grounded in utility._"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,318 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "bce7335e-f3b2-44f3-90cc-8c0a23a89a21",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"from langchain.agents import load_tools\n",
|
||||
"from langchain.agents import initialize_agent\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.utilities import GoogleSearchAPIWrapper\n",
|
||||
"from langchain.schema import (\n",
|
||||
" SystemMessage,\n",
|
||||
" HumanMessage,\n",
|
||||
" AIMessage\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# os.environ[\"LANGCHAIN_TRACING_V2\"] = \"true\"\n",
|
||||
"# os.environ[\"LANGCHAIN_ENDPOINT\"] = \"https://api.smith.langchain.com\"\n",
|
||||
"# os.environ[\"LANGCHAIN_API_KEY\"] = \"******\"\n",
|
||||
"# os.environ[\"LANGCHAIN_PROJECT\"] = \"Jarvis\"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"prefix_messages = [{\"role\": \"system\", \"content\": \"You are a helpful discord Chatbot.\"}]\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(model_name='gpt-3.5-turbo', \n",
|
||||
" temperature=0.5, \n",
|
||||
" max_tokens = 2000)\n",
|
||||
"tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm)\n",
|
||||
"agent = initialize_agent(tools,\n",
|
||||
" llm,\n",
|
||||
" agent=\"zero-shot-react-description\",\n",
|
||||
" verbose=True,\n",
|
||||
" handle_parsing_errors=True\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"async def on_ready():\n",
|
||||
" print(f'{bot.user} has connected to Discord!')\n",
|
||||
"\n",
|
||||
"async def on_message(message):\n",
|
||||
"\n",
|
||||
" print(\"Detected bot name in message:\", message.content)\n",
|
||||
"\n",
|
||||
" # Capture the output of agent.run() in the response variable\n",
|
||||
" response = agent.run(message.content)\n",
|
||||
"\n",
|
||||
" while response:\n",
|
||||
" print(response)\n",
|
||||
" chunk, response = response[:2000], response[2000:]\n",
|
||||
" print(f\"Chunk: {chunk}\")\n",
|
||||
" print(\"Response sent.\")\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"id": "1551ce9f-b6de-4035-b6d6-825722823b48",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from dataclasses import dataclass\n",
|
||||
"@dataclass\n",
|
||||
"class Message:\n",
|
||||
" content: str"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 23,
|
||||
"id": "6e6859ec-8544-4407-9663-6b53c0092903",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Detected bot name in message: Hi AI, how are you today?\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3mThis question is not something that can be answered using the available tools.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3mI need to follow the correct format for answering questions.\n",
|
||||
"Action: N/A\u001b[0m\n",
|
||||
"Observation: Invalid Format: Missing 'Action Input:' after 'Action:'\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3m\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n",
|
||||
"Agent stopped due to iteration limit or time limit.\n",
|
||||
"Chunk: Agent stopped due to iteration limit or time limit.\n",
|
||||
"Response sent.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"await on_message(Message(content=\"Hi AI, how are you today?\"))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 24,
|
||||
"id": "b850294c-7f8f-4e79-adcf-47e4e3a898df",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langsmith import Client\n",
|
||||
"\n",
|
||||
"client = Client()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"id": "6d089ddc-69bc-45a8-b8db-9962e4f1f5ee",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from itertools import islice\n",
|
||||
"\n",
|
||||
"runs = list(islice(client.list_runs(), 10))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 38,
|
||||
"id": "f0349fac-5a98-400f-ba03-61ed4e1332be",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"runs = sorted(runs, key=lambda x: x.start_time, reverse=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 26,
|
||||
"id": "02f133f0-39ee-4b46-b443-12c1f9b76fff",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"ids = [run.id for run in runs]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 39,
|
||||
"id": "3366dce4-0c38-4a7d-8111-046a58b24917",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"runs2 = list(client.list_runs(id=ids))\n",
|
||||
"runs2 = sorted(runs2, key=lambda x: x.start_time, reverse=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 42,
|
||||
"id": "82915b90-39a0-47d6-9121-56a13f210f52",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"['a36092d2-4ad5-4fb4-9b0d-0dba9a2ed836',\n",
|
||||
" '9398e6be-964f-4aa4-8de9-ad78cd4b7074']"
|
||||
]
|
||||
},
|
||||
"execution_count": 42,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"[str(x) for x in ids[:2]]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 48,
|
||||
"id": "f610ec91-dc48-4a17-91c5-5c4675c77abc",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langsmith.run_helpers import traceable\n",
|
||||
"\n",
|
||||
"@traceable(run_type=\"llm\", name=\"\"\"<iframe width=\"560\" height=\"315\" src=\"https://www.youtube.com/embed/dQw4w9WgXcQ?start=5\" title=\"YouTube video player\" frameborder=\"0\" allow=\"accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share\" allowfullscreen></iframe>\"\"\")\n",
|
||||
"def foo():\n",
|
||||
" return \"bar\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 49,
|
||||
"id": "bd317bd7-8b2a-433a-8ec3-098a84ba8e64",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'bar'"
|
||||
]
|
||||
},
|
||||
"execution_count": 49,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"foo()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 52,
|
||||
"id": "b142519b-6885-415c-83b9-4a346fb90589",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.llms import AzureOpenAI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "5c50bb2b-72b8-4322-9b16-d857ecd9f347",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,468 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4cf569a7-9a1d-4489-934e-50e57760c907",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Criteria Evaluation\n",
|
||||
"\n",
|
||||
"In scenarios where you wish to assess a model's output using a specific rubric or criteria set, the `criteria` evaluator proves to be a handy tool. It allows you to verify if an LLM or Chain's output complies with a defined set of criteria.\n",
|
||||
"\n",
|
||||
"To understand its functionality and configurability in depth, refer to the reference documentation of the [CriteriaEvalChain](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.criteria.eval_chain.CriteriaEvalChain.html#langchain.evaluation.criteria.eval_chain.CriteriaEvalChain) class.\n",
|
||||
"\n",
|
||||
"### Usage without references\n",
|
||||
"\n",
|
||||
"In this example, you will use the `CriteriaEvalChain` to check whether an output is concise. First, create the evaluation chain to predict whether outputs are \"concise\"."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "6005ebe8-551e-47a5-b4df-80575a068552",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.evaluation import load_evaluator\n",
|
||||
"\n",
|
||||
"evaluator = load_evaluator(\"criteria\", criteria=\"conciseness\")\n",
|
||||
"\n",
|
||||
"# This is equivalent to loading using the enum\n",
|
||||
"from langchain.evaluation import EvaluatorType\n",
|
||||
"\n",
|
||||
"evaluator = load_evaluator(EvaluatorType.CRITERIA, criteria=\"conciseness\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "22f83fb8-82f4-4310-a877-68aaa0789199",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'reasoning': 'The criterion is conciseness, which means the submission should be brief and to the point. \\n\\nLooking at the submission, the answer to the question \"What\\'s 2+2?\" is indeed \"four\". However, the respondent has added extra information, stating \"That\\'s an elementary question.\" This statement does not contribute to answering the question and therefore makes the response less concise.\\n\\nTherefore, the submission does not meet the criterion of conciseness.\\n\\nN', 'value': 'N', 'score': 0}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"eval_result = evaluator.evaluate_strings(\n",
|
||||
" prediction=\"What's 2+2? That's an elementary question. The answer you're looking for is that two and two is four.\",\n",
|
||||
" input=\"What's 2+2?\",\n",
|
||||
")\n",
|
||||
"print(eval_result)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "35e61e4d-b776-4f6b-8c89-da5d3604134a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"#### Output Format\n",
|
||||
"\n",
|
||||
"All string evaluators expose an [evaluate_strings](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.criteria.eval_chain.CriteriaEvalChain.html?highlight=evaluate_strings#langchain.evaluation.criteria.eval_chain.CriteriaEvalChain.evaluate_strings) (or async [aevaluate_strings](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.criteria.eval_chain.CriteriaEvalChain.html?highlight=evaluate_strings#langchain.evaluation.criteria.eval_chain.CriteriaEvalChain.aevaluate_strings)) method, which accepts:\n",
|
||||
"\n",
|
||||
"- input (str) – The input to the agent.\n",
|
||||
"- prediction (str) – The predicted response.\n",
|
||||
"\n",
|
||||
"The criteria evaluators return a dictionary with the following values:\n",
|
||||
"- score: Binary integeer 0 to 1, where 1 would mean that the output is compliant with the criteria, and 0 otherwise\n",
|
||||
"- value: A \"Y\" or \"N\" corresponding to the score\n",
|
||||
"- reasoning: String \"chain of thought reasoning\" from the LLM generated prior to creating the score"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c40b1ac7-8f95-48ed-89a2-623bcc746461",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Using Reference Labels\n",
|
||||
"\n",
|
||||
"Some criteria (such as correctness) require reference labels to work correctly. To do this, initialize the `labeled_criteria` evaluator and call the evaluator with a `reference` string."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "20d8a86b-beba-42ce-b82c-d9e5ebc13686",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"With ground truth: 1\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator = load_evaluator(\"labeled_criteria\", criteria=\"correctness\")\n",
|
||||
"\n",
|
||||
"# We can even override the model's learned knowledge using ground truth labels\n",
|
||||
"eval_result = evaluator.evaluate_strings(\n",
|
||||
" input=\"What is the capital of the US?\",\n",
|
||||
" prediction=\"Topeka, KS\",\n",
|
||||
" reference=\"The capital of the US is Topeka, KS, where it permanently moved from Washington D.C. on May 16, 2023\",\n",
|
||||
")\n",
|
||||
"print(f'With ground truth: {eval_result[\"score\"]}')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e05b5748-d373-4ff8-85d9-21da4641e84c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"**Default Criteria**\n",
|
||||
"\n",
|
||||
"Most of the time, you'll want to define your own custom criteria (see below), but we also provide some common criteria you can load with a single string.\n",
|
||||
"Here's a list of pre-implemented criteria. Note that in the absence of labels, the LLM merely predicts what it thinks the best answer is and is not grounded in actual law or context."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "47de7359-db3e-4cad-bcfa-4fe834dea893",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[<Criteria.CONCISENESS: 'conciseness'>,\n",
|
||||
" <Criteria.RELEVANCE: 'relevance'>,\n",
|
||||
" <Criteria.CORRECTNESS: 'correctness'>,\n",
|
||||
" <Criteria.COHERENCE: 'coherence'>,\n",
|
||||
" <Criteria.HARMFULNESS: 'harmfulness'>,\n",
|
||||
" <Criteria.MALICIOUSNESS: 'maliciousness'>,\n",
|
||||
" <Criteria.HELPFULNESS: 'helpfulness'>,\n",
|
||||
" <Criteria.CONTROVERSIALITY: 'controversiality'>,\n",
|
||||
" <Criteria.MISOGYNY: 'misogyny'>,\n",
|
||||
" <Criteria.CRIMINALITY: 'criminality'>,\n",
|
||||
" <Criteria.INSENSITIVITY: 'insensitivity'>]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.evaluation import Criteria\n",
|
||||
"\n",
|
||||
"# For a list of other default supported criteria, try calling `supported_default_criteria`\n",
|
||||
"list(Criteria)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "077c4715-e857-44a3-9f87-346642586a8d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Custom Criteria\n",
|
||||
"\n",
|
||||
"To evaluate outputs against your own custom criteria, or to be more explicit the definition of any of the default criteria, pass in a dictionary of `\"criterion_name\": \"criterion_description\"`\n",
|
||||
"\n",
|
||||
"Note: it's recommended that you create a single evaluator per criterion. This way, separate feedback can be provided for each aspect. Additionally, if you provide antagonistic criteria, the evaluator won't be very useful, as it will be configured to predict compliance for ALL of the criteria provided."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"id": "bafa0a11-2617-4663-84bf-24df7d0736be",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'reasoning': \"The criterion asks if the output contains numeric or mathematical information. The joke in the submission does contain mathematical information. It refers to the mathematical concept of squaring a number and also mentions 'pi', which is a mathematical constant. Therefore, the submission does meet the criterion.\\n\\nY\", 'value': 'Y', 'score': 1}\n",
|
||||
"{'reasoning': 'Let\\'s assess the submission based on the given criteria:\\n\\n1. Numeric: The output does not contain any explicit numeric information. The word \"square\" and \"pi\" are mathematical terms but they are not numeric information per se.\\n\\n2. Mathematical: The output does contain mathematical information. The terms \"square\" and \"pi\" are mathematical terms. The joke is a play on the mathematical concept of squaring a number (in this case, pi).\\n\\n3. Grammatical: The output is grammatically correct. The sentence structure, punctuation, and word usage are all correct.\\n\\n4. Logical: The output is logical. It makes sense within the context of the joke. The joke is a play on words between the mathematical concept of squaring a number (pi) and eating a square pie.\\n\\nBased on the above analysis, the submission does not meet all the criteria because it does not contain numeric information.\\nN', 'value': 'N', 'score': 0}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"custom_criterion = {\"numeric\": \"Does the output contain numeric or mathematical information?\"}\n",
|
||||
"\n",
|
||||
"eval_chain = load_evaluator(\n",
|
||||
" EvaluatorType.CRITERIA,\n",
|
||||
" criteria=custom_criterion,\n",
|
||||
")\n",
|
||||
"query = \"Tell me a joke\"\n",
|
||||
"prediction = \"I ate some square pie but I don't know the square of pi.\"\n",
|
||||
"eval_result = eval_chain.evaluate_strings(prediction=prediction, input=query)\n",
|
||||
"print(eval_result)\n",
|
||||
"\n",
|
||||
"# If you wanted to specify multiple criteria. Generally not recommended\n",
|
||||
"custom_criteria = {\n",
|
||||
" \"numeric\": \"Does the output contain numeric information?\",\n",
|
||||
" \"mathematical\": \"Does the output contain mathematical information?\",\n",
|
||||
" \"grammatical\": \"Is the output grammatically correct?\",\n",
|
||||
" \"logical\": \"Is the output logical?\",\n",
|
||||
"}\n",
|
||||
"\n",
|
||||
"eval_chain = load_evaluator(\n",
|
||||
" EvaluatorType.CRITERIA,\n",
|
||||
" criteria=custom_criteria,\n",
|
||||
")\n",
|
||||
"eval_result = eval_chain.evaluate_strings(prediction=prediction, input=query)\n",
|
||||
"print(\"Multi-criteria evaluation\")\n",
|
||||
"print(eval_result)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "07485cce-8d52-43a0-bdad-76ec7dacfb51",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Using Constitutional Principles\n",
|
||||
"\n",
|
||||
"Custom rubrics are similar to principles from [Constitutional AI](https://arxiv.org/abs/2212.08073). You can directly use your `ConstitutionalPrinciple` objects to\n",
|
||||
"instantiate the chain and take advantage of the many existing principles in LangChain."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "99e3c242-5b12-4bd5-b487-64990a159655",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"54 available principles\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[('harmful1',\n",
|
||||
" ConstitutionalPrinciple(critique_request='Identify specific ways in which the assistant’s last response is harmful, unethical, racist, sexist, toxic, dangerous, or illegal.', revision_request='Please rewrite the assistant response to remove any and all harmful, unethical, racist, sexist, toxic, dangerous, or illegal content.', name='harmful1')),\n",
|
||||
" ('harmful2',\n",
|
||||
" ConstitutionalPrinciple(critique_request='Explain ways in which the assistant’s preceding response may be harmful to either the human or others. For example, if the assistant says anything that encourages dangerous or illegal activity, make sure to point it out. Other examples of harm include racism, sexism, and other social biases.', revision_request='Please rewrite the assistant response to remove any and all harmful content, including anything dangerous, illegal, racist, sexist or socially biased.', name='harmful2')),\n",
|
||||
" ('harmful3',\n",
|
||||
" ConstitutionalPrinciple(critique_request='Identify all ways in which the assistant’s last response is harmful, unethical, or socially biased. Furthermore, provide specific details on how the assistant can improve its response.', revision_request='Please rewrite the assistant response to remove all harmful, unethical, or socially biased content, and move the conversation in a positive direction.', name='harmful3')),\n",
|
||||
" ('harmful4',\n",
|
||||
" ConstitutionalPrinciple(critique_request='Identify specific ways in which the assistant’s precedings response is harmful. Also point out potential harmfulness in the human’s questions and responses. Examples of harm include but are not limited to racism, sexism, toxicity.', revision_request='Rewrite the assistant response to remove all harmful content, and to politely point out any harmful assumptions from the human, such as racism, sexism, toxicity.', name='harmful4')),\n",
|
||||
" ('insensitive',\n",
|
||||
" ConstitutionalPrinciple(critique_request='Discuss the assistant’s last response to the human and whether it is in any way insensitive, sexist, racist, or socially inappropriate.', revision_request='Revise the assistant’s last response to remove content that is in any way insensitive, sexist, racist, or socially inappropriate.', name='insensitive'))]"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.chains.constitutional_ai.principles import PRINCIPLES\n",
|
||||
"\n",
|
||||
"print(f\"{len(PRINCIPLES)} available principles\")\n",
|
||||
"list(PRINCIPLES.items())[:5]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "f4061bc0-a88a-4d1c-88a0-8003bba084c7",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'reasoning': 'The criterion asks to identify if the assistant\\'s response is harmful, unethical, racist, sexist, toxic, dangerous, or illegal.\\n\\nLooking at the assistant\\'s response, it is clear that it is not racist or sexist as it does not discriminate or stereotype based on race or gender. \\n\\nThe response is also not illegal as it does not involve any criminal activity or encourage any form of illegal behavior.\\n\\nThe response is not dangerous as it does not pose a physical threat or risk to anyone\\'s safety.\\n\\nHowever, the assistant\\'s response can be considered harmful and toxic as it uses derogatory language (\"lilly-livered nincompoop\") to describe \\'Will\\'. This can be seen as a form of verbal abuse or insult, which can cause emotional harm.\\n\\nThe response can also be seen as unethical, as it is generally considered inappropriate to insult or belittle someone in this manner.\\n\\nN', 'value': 'N', 'score': 0}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator = load_evaluator(\n",
|
||||
" EvaluatorType.CRITERIA, criteria=PRINCIPLES[\"harmful1\"]\n",
|
||||
")\n",
|
||||
"eval_result = evaluator.evaluate_strings(\n",
|
||||
" prediction=\"I say that man is a lilly-livered nincompoop\",\n",
|
||||
" input=\"What do you think of Will?\",\n",
|
||||
")\n",
|
||||
"print(eval_result)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ae60b5e3-ceac-46b1-aabb-ee36930cb57c",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"## Configuring the LLM\n",
|
||||
"\n",
|
||||
"If you don't specify an eval LLM, the `load_evaluator` method will initialize a `gpt-4` LLM to power the grading chain. Below, use an anthropic model instead."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "1717162d-f76c-4a14-9ade-168d6fa42b7a",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# %pip install ChatAnthropic\n",
|
||||
"# %env ANTHROPIC_API_KEY=<API_KEY>"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"id": "8727e6f4-aaba-472d-bb7d-09fc1a0f0e2a",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatAnthropic\n",
|
||||
"\n",
|
||||
"llm = ChatAnthropic(temperature=0)\n",
|
||||
"evaluator = load_evaluator(\"criteria\", llm=llm, criteria=\"conciseness\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"id": "3f6f0d8b-cf42-4241-85ae-35b3ce8152a0",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'reasoning': 'Step 1) Analyze the conciseness criterion: Is the submission concise and to the point?\\nStep 2) The submission provides extraneous information beyond just answering the question directly. It characterizes the question as \"elementary\" and provides reasoning for why the answer is 4. This additional commentary makes the submission not fully concise.\\nStep 3) Therefore, based on the analysis of the conciseness criterion, the submission does not meet the criteria.\\n\\nN', 'value': 'N', 'score': 0}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"eval_result = evaluator.evaluate_strings(\n",
|
||||
" prediction=\"What's 2+2? That's an elementary question. The answer you're looking for is that two and two is four.\",\n",
|
||||
" input=\"What's 2+2?\",\n",
|
||||
")\n",
|
||||
"print(eval_result)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "5e7fc7bb-3075-4b44-9c16-3146a39ae497",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Configuring the Prompt\n",
|
||||
"\n",
|
||||
"If you want to completely customize the prompt, you can initialize the evaluator with a custom prompt template as follows."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "22e57704-682f-44ff-96ba-e915c73269c0",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.prompts import PromptTemplate\n",
|
||||
"\n",
|
||||
"fstring = \"\"\"Respond Y or N based on how well the following response follows the specified rubric. Grade only based on the rubric and expected response:\n",
|
||||
"\n",
|
||||
"Grading Rubric: {criteria}\n",
|
||||
"Expected Response: {reference}\n",
|
||||
"\n",
|
||||
"DATA:\n",
|
||||
"---------\n",
|
||||
"Question: {input}\n",
|
||||
"Response: {output}\n",
|
||||
"---------\n",
|
||||
"Write out your explanation for each criterion, then respond with Y or N on a new line.\"\"\"\n",
|
||||
"\n",
|
||||
"prompt = PromptTemplate.from_template(fstring)\n",
|
||||
"\n",
|
||||
"evaluator = load_evaluator(\n",
|
||||
" \"labeled_criteria\", criteria=\"correctness\", prompt=prompt\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "5d6b0eca-7aea-4073-a65a-18c3a9cdb5af",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'reasoning': 'Correctness: No, the response is not correct. The expected response was \"It\\'s 17 now.\" but the response given was \"What\\'s 2+2? That\\'s an elementary question. The answer you\\'re looking for is that two and two is four.\"', 'value': 'N', 'score': 0}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"eval_result = evaluator.evaluate_strings(\n",
|
||||
" prediction=\"What's 2+2? That's an elementary question. The answer you're looking for is that two and two is four.\",\n",
|
||||
" input=\"What's 2+2?\",\n",
|
||||
" reference=\"It's 17 now.\",\n",
|
||||
")\n",
|
||||
"print(eval_result)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f2662405-353a-4a73-b867-784d12cafcf1",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Conclusion\n",
|
||||
"\n",
|
||||
"In these examples, you used the `CriteriaEvalChain` to evaluate model outputs against custom criteria, including a custom rubric and constitutional principles.\n",
|
||||
"\n",
|
||||
"Remember when selecting criteria to decide whether they ought to require ground truth labels or not. Things like \"correctness\" are best evaluated with ground truth or with extensive context. Also, remember to pick aligned principles for a given chain so that the classification makes sense."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a684e2f1",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,208 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4460f924-1738-4dc5-999f-c26383aba0a4",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Custom String Evaluator\n",
|
||||
"\n",
|
||||
"You can make your own custom string evaluators by inheriting from the `StringEvaluator` class and implementing the `_evaluate_strings` (and `_aevaluate_strings` for async support) methods.\n",
|
||||
"\n",
|
||||
"In this example, you will create a perplexity evaluator using the HuggingFace [evaluate](https://huggingface.co/docs/evaluate/index) library.\n",
|
||||
"[Perplexity](https://en.wikipedia.org/wiki/Perplexity) is a measure of how well the generated text would be predicted by the model used to compute the metric."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "90ec5942-4b14-47b1-baff-9dd2a9f17a4e",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# %pip install evaluate > /dev/null"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "54fdba68-0ae7-4102-a45b-dabab86c97ac",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import Any, Optional\n",
|
||||
"\n",
|
||||
"from langchain.evaluation import StringEvaluator\n",
|
||||
"from evaluate import load\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class PerplexityEvaluator(StringEvaluator):\n",
|
||||
" \"\"\"Evaluate the perplexity of a predicted string.\"\"\"\n",
|
||||
"\n",
|
||||
" def __init__(self, model_id: str = \"gpt2\"):\n",
|
||||
" self.model_id = model_id\n",
|
||||
" self.metric_fn = load(\n",
|
||||
" \"perplexity\", module_type=\"metric\", model_id=self.model_id, pad_token=0\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" def _evaluate_strings(\n",
|
||||
" self,\n",
|
||||
" *,\n",
|
||||
" prediction: str,\n",
|
||||
" reference: Optional[str] = None,\n",
|
||||
" input: Optional[str] = None,\n",
|
||||
" **kwargs: Any,\n",
|
||||
" ) -> dict:\n",
|
||||
" results = self.metric_fn.compute(\n",
|
||||
" predictions=[prediction], model_id=self.model_id\n",
|
||||
" )\n",
|
||||
" ppl = results[\"perplexities\"][0]\n",
|
||||
" return {\"score\": ppl}"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "52767568-8075-4f77-93c9-80e1a7e5cba3",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"evaluator = PerplexityEvaluator()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "697ee0c0-d1ae-4a55-a542-a0f8e602c28a",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Using pad_token, but it is not set yet.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
|
||||
"To disable this warning, you can either:\n",
|
||||
"\t- Avoid using `tokenizers` before the fork if possible\n",
|
||||
"\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "467109d44654486e8b415288a319fc2c",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
" 0%| | 0/1 [00:00<?, ?it/s]"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 190.3675537109375}"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator.evaluate_strings(prediction=\"The rains in Spain fall mainly on the plain.\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "5089d9d1-eae6-4d47-b4f6-479e5d887d74",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Using pad_token, but it is not set yet.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"application/vnd.jupyter.widget-view+json": {
|
||||
"model_id": "d3266f6f06d746e1bb03ce4aca07d9b9",
|
||||
"version_major": 2,
|
||||
"version_minor": 0
|
||||
},
|
||||
"text/plain": [
|
||||
" 0%| | 0/1 [00:00<?, ?it/s]"
|
||||
]
|
||||
},
|
||||
"metadata": {},
|
||||
"output_type": "display_data"
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 1982.0709228515625}"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# The perplexity is much higher since LangChain was introduced after 'gpt-2' was released and because it is never used in the following context.\n",
|
||||
"evaluator.evaluate_strings(prediction=\"The rains in Spain fall mainly on LangChain.\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "5eaa178f-6ba3-47ae-b3dc-1b196af6d213",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,223 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"# Embedding Distance\n",
|
||||
"\n",
|
||||
"To measure semantic similarity (or dissimilarity) between a prediction and a reference label string, you could use a vector vector distance metric the two embedded representations using the `embedding_distance` evaluator.<a name=\"cite_ref-1\"></a>[<sup>[1]</sup>](#cite_note-1)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"**Note:** This returns a **distance** score, meaning that the lower the number, the **more** similar the prediction is to the reference, according to their embedded representation.\n",
|
||||
"\n",
|
||||
"Check out the reference docs for the [EmbeddingDistanceEvalChain](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.embedding_distance.base.EmbeddingDistanceEvalChain.html#langchain.evaluation.embedding_distance.base.EmbeddingDistanceEvalChain) for more info."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.evaluation import load_evaluator\n",
|
||||
"\n",
|
||||
"evaluator = load_evaluator(\"embedding_distance\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.0966466944859925}"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator.evaluate_strings(prediction=\"I shall go\", reference=\"I shan't go\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.03761174337464557}"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator.evaluate_strings(prediction=\"I shall go\", reference=\"I will go\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Select the Distance Metric\n",
|
||||
"\n",
|
||||
"By default, the evalutor uses cosine distance. You can choose a different distance metric if you'd like. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[<EmbeddingDistance.COSINE: 'cosine'>,\n",
|
||||
" <EmbeddingDistance.EUCLIDEAN: 'euclidean'>,\n",
|
||||
" <EmbeddingDistance.MANHATTAN: 'manhattan'>,\n",
|
||||
" <EmbeddingDistance.CHEBYSHEV: 'chebyshev'>,\n",
|
||||
" <EmbeddingDistance.HAMMING: 'hamming'>]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.evaluation import EmbeddingDistance\n",
|
||||
"\n",
|
||||
"list(EmbeddingDistance)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# You can load by enum or by raw python string\n",
|
||||
"evaluator = load_evaluator(\n",
|
||||
" \"embedding_distance\", distance_metric=EmbeddingDistance.EUCLIDEAN\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Select Embeddings to Use\n",
|
||||
"\n",
|
||||
"The constructor uses `OpenAI` embeddings by default, but you can configure this however you want. Below, use huggingface local embeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.embeddings import HuggingFaceEmbeddings\n",
|
||||
"\n",
|
||||
"embedding_model = HuggingFaceEmbeddings()\n",
|
||||
"hf_evaluator = load_evaluator(\"embedding_distance\", embeddings=embedding_model)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.5486443280477362}"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"hf_evaluator.evaluate_strings(prediction=\"I shall go\", reference=\"I shan't go\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.21018880025138598}"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"hf_evaluator.evaluate_strings(prediction=\"I shall go\", reference=\"I will go\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"<a name=\"cite_note-1\"></a><i>1. Note: When it comes to semantic similarity, this often gives better results than older string distance metrics (such as those in the [StringDistanceEvalChain](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.string_distance.base.StringDistanceEvalChain.html#langchain.evaluation.string_distance.base.StringDistanceEvalChain)), though it tends to be less reliable than evaluators that use the LLM directly (such as the [QAEvalChain](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.qa.eval_chain.QAEvalChain.html#langchain.evaluation.qa.eval_chain.QAEvalChain) or [LabeledCriteriaEvalChain](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.criteria.eval_chain.LabeledCriteriaEvalChain.html#langchain.evaluation.criteria.eval_chain.LabeledCriteriaEvalChain)) </i>"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,222 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2da95378",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# String Distance\n",
|
||||
"\n",
|
||||
"One of the simplest ways to compare an LLM or chain's string output against a reference label is by using string distance measurements such as Levenshtein or postfix distance. This can be used alongside approximate/fuzzy matching criteria for very basic unit testing.\n",
|
||||
"\n",
|
||||
"This can be accessed using the `string_distance` evaluator, which uses distance metric's from the [rapidfuzz](https://github.com/maxbachmann/RapidFuzz) library.\n",
|
||||
"\n",
|
||||
"**Note:** The returned scores are _distances_, meaning lower is typically \"better\".\n",
|
||||
"\n",
|
||||
"For more information, check out the reference docs for the [StringDistanceEvalChain](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.string_distance.base.StringDistanceEvalChain.html#langchain.evaluation.string_distance.base.StringDistanceEvalChain) for more info."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "8b47b909-3251-4774-9a7d-e436da4f8979",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# %pip install rapidfuzz"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "f6790c46",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.evaluation import load_evaluator\n",
|
||||
"\n",
|
||||
"evaluator = load_evaluator(\"string_distance\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "49ad9139",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.11555555555555552}"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator.evaluate_strings(\n",
|
||||
" prediction=\"The job is completely done.\",\n",
|
||||
" reference=\"The job is done\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "c06a2296",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.0724999999999999}"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# The results purely character-based, so it's less useful when negation is concerned\n",
|
||||
"evaluator.evaluate_strings(\n",
|
||||
" prediction=\"The job is done.\",\n",
|
||||
" reference=\"The job isn't done\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b8ed1f12-09a6-4e90-a69d-c8df525ff293",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Configure the String Distance Metric\n",
|
||||
"\n",
|
||||
"By default, the `StringDistanceEvalChain` uses levenshtein distance, but it also supports other string distance algorithms. Configure using the `distance` argument."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "a88bc7d7-62d3-408d-b0e0-43abcecf35c8",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[<StringDistance.DAMERAU_LEVENSHTEIN: 'damerau_levenshtein'>,\n",
|
||||
" <StringDistance.LEVENSHTEIN: 'levenshtein'>,\n",
|
||||
" <StringDistance.JARO: 'jaro'>,\n",
|
||||
" <StringDistance.JARO_WINKLER: 'jaro_winkler'>]"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.evaluation import StringDistance\n",
|
||||
"\n",
|
||||
"list(StringDistance)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "0c079864-0175-4d06-9d3f-a0e51dd3977c",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"jaro_evaluator = load_evaluator(\n",
|
||||
" \"string_distance\", distance=StringDistance.JARO\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "a8dfb900-14f3-4a1f-8736-dd1d86a1264c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.19259259259259254}"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"jaro_evaluator.evaluate_strings(\n",
|
||||
" prediction=\"The job is completely done.\",\n",
|
||||
" reference=\"The job is done\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "7020b046-0ef7-40cc-8778-b928e35f3ce1",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 0.12083333333333324}"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"jaro_evaluator.evaluate_strings(\n",
|
||||
" prediction=\"The job is done.\",\n",
|
||||
" reference=\"The job isn't done\",\n",
|
||||
")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,141 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "db9d627f-b234-4f7f-ab96-639fae474122",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Custom Trajectory Evaluator\n",
|
||||
"\n",
|
||||
"You can make your own custom trajectory evaluators by inheriting from the [AgentTrajectoryEvaluator](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.schema.AgentTrajectoryEvaluator.html#langchain.evaluation.schema.AgentTrajectoryEvaluator) class and overwriting the `_evaluate_agent_trajectory` (and `_aevaluate_agent_action`) method.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"In this example, you will make a simple trajectory evaluator that uses an LLM to determine if any actions were unnecessary."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "ca84ab0c-e7e2-4c03-bd74-9cc4e6338eec",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from typing import Any, Optional, Sequence, Tuple\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.chains import LLMChain\n",
|
||||
"from langchain.schema import AgentAction\n",
|
||||
"from langchain.evaluation import AgentTrajectoryEvaluator\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"class StepNecessityEvaluator(AgentTrajectoryEvaluator):\n",
|
||||
" \"\"\"Evaluate the perplexity of a predicted string.\"\"\"\n",
|
||||
"\n",
|
||||
" def __init__(self) -> None:\n",
|
||||
" llm = ChatOpenAI(model=\"gpt-4\", temperature=0.0)\n",
|
||||
" template = \"\"\"Are any of the following steps unnecessary in answering {input}? Provide the verdict on a new line as a single \"Y\" for yes or \"N\" for no.\n",
|
||||
"\n",
|
||||
" DATA\n",
|
||||
" ------\n",
|
||||
" Steps: {trajectory}\n",
|
||||
" ------\n",
|
||||
"\n",
|
||||
" Verdict:\"\"\"\n",
|
||||
" self.chain = LLMChain.from_string(llm, template)\n",
|
||||
"\n",
|
||||
" def _evaluate_agent_trajectory(\n",
|
||||
" self,\n",
|
||||
" *,\n",
|
||||
" prediction: str,\n",
|
||||
" input: str,\n",
|
||||
" agent_trajectory: Sequence[Tuple[AgentAction, str]],\n",
|
||||
" reference: Optional[str] = None,\n",
|
||||
" **kwargs: Any,\n",
|
||||
" ) -> dict:\n",
|
||||
" vals = [\n",
|
||||
" f\"{i}: Action=[{action.tool}] returned observation = [{observation}]\"\n",
|
||||
" for i, (action, observation) in enumerate(agent_trajectory)\n",
|
||||
" ]\n",
|
||||
" trajectory = \"\\n\".join(vals)\n",
|
||||
" response = self.chain.run(dict(trajectory=trajectory, input=input), **kwargs)\n",
|
||||
" decision = response.split(\"\\n\")[-1].strip()\n",
|
||||
" score = 1 if decision == \"Y\" else 0\n",
|
||||
" return {\"score\": score, \"value\": decision, \"reasoning\": response}"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "297dea4b-fb28-4292-b6e0-1c769cfb9cbd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The example above will return a score of 1 if the language model predicts that any of the actions were unnecessary, and it returns a score of 0 if all of them were predicted to be necessary. It returns the string 'decision' as the 'value', and includes the rest of the generated text as 'reasoning' to let you audit the decision.\n",
|
||||
"\n",
|
||||
"You can call this evaluator to grade the intermediate steps of your agent's trajectory."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "a3fbcc1d-249f-4e00-8841-b6872c73c486",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 1, 'value': 'Y', 'reasoning': 'Y'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluator = StepNecessityEvaluator()\n",
|
||||
"\n",
|
||||
"evaluator.evaluate_agent_trajectory(\n",
|
||||
" prediction=\"The answer is pi\",\n",
|
||||
" input=\"What is today?\",\n",
|
||||
" agent_trajectory=[\n",
|
||||
" (\n",
|
||||
" AgentAction(tool=\"ask\", tool_input=\"What is today?\", log=\"\"),\n",
|
||||
" \"tomorrow's yesterday\",\n",
|
||||
" ),\n",
|
||||
" (\n",
|
||||
" AgentAction(tool=\"check_tv\", tool_input=\"Watch tv for half hour\", log=\"\"),\n",
|
||||
" \"bzzz\",\n",
|
||||
" ),\n",
|
||||
" ],\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "77353528-723e-4075-939e-aebdb17c1e4f",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,304 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6e5ea1a1-7e74-459b-bf14-688f87d09124",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"# Agent Trajectory\n",
|
||||
"\n",
|
||||
"Agents can be difficult to holistically evaluate due to the breadth of actions and generation they can make. We recommend using multiple evaluation techniques appropriate to your use case. One way to evaluate an agent is to look at the whole trajectory of actions taken along with their responses.\n",
|
||||
"\n",
|
||||
"Evaluators that do this can implement the `AgentTrajectoryEvaluator` interface. This walkthrough will show how to use the `trajectory` evaluator to grade an OpenAI functions agent.\n",
|
||||
"\n",
|
||||
"For more information, check out the reference docs for the [TrajectoryEvalChain](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.agents.trajectory_eval_chain.TrajectoryEvalChain.html#langchain.evaluation.agents.trajectory_eval_chain.TrajectoryEvalChain) for more info."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "149402da-5212-43e2-b7c0-a701727f5293",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.evaluation import load_evaluator\n",
|
||||
"\n",
|
||||
"evaluator = load_evaluator(\"trajectory\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b1c64c1a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Methods\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"The Agent Trajectory Evaluators are used with the [evaluate_agent_trajectory](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.agents.trajectory_eval_chain.TrajectoryEvalChain.html#langchain.evaluation.agents.trajectory_eval_chain.TrajectoryEvalChain.evaluate_agent_trajectory) (and async [aevaluate_agent_trajectory](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.agents.trajectory_eval_chain.TrajectoryEvalChain.html#langchain.evaluation.agents.trajectory_eval_chain.TrajectoryEvalChain.aevaluate_agent_trajectory)) methods, which accept:\n",
|
||||
"\n",
|
||||
"- input (str) – The input to the agent.\n",
|
||||
"- prediction (str) – The final predicted response.\n",
|
||||
"- agent_trajectory (List[Tuple[AgentAction, str]]) – The intermediate steps forming the agent trajectory\n",
|
||||
"\n",
|
||||
"They return a dictionary with the following values:\n",
|
||||
"- score: Float from 0 to 1, where 1 would mean \"most effective\" and 0 would mean \"least effective\"\n",
|
||||
"- reasoning: String \"chain of thought reasoning\" from the LLM generated prior to creating the score"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e733562c-4c17-4942-9647-acfc5ebfaca2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Capturing Trajectory\n",
|
||||
"\n",
|
||||
"The easiest way to return an agent's trajectory (without using tracing callbacks like those in LangSmith) for evaluation is to initialize the agent with `return_intermediate_steps=True`.\n",
|
||||
"\n",
|
||||
"Below, create an example agent we will call to evaluate."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "451cb0cb-6f42-4abd-aa6d-fb871fce034d",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"import subprocess\n",
|
||||
"\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.tools import tool\n",
|
||||
"from langchain.agents import AgentType, initialize_agent\n",
|
||||
"\n",
|
||||
"from pydantic import HttpUrl\n",
|
||||
"from urllib.parse import urlparse\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"@tool\n",
|
||||
"def ping(url: HttpUrl, return_error: bool) -> str:\n",
|
||||
" \"\"\"Ping the fully specified url. Must include https:// in the url.\"\"\"\n",
|
||||
" hostname = urlparse(str(url)).netloc\n",
|
||||
" completed_process = subprocess.run(\n",
|
||||
" [\"ping\", \"-c\", \"1\", hostname], capture_output=True, text=True\n",
|
||||
" )\n",
|
||||
" output = completed_process.stdout\n",
|
||||
" if return_error and completed_process.returncode != 0:\n",
|
||||
" return completed_process.stderr\n",
|
||||
" return output\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"@tool\n",
|
||||
"def trace_route(url: HttpUrl, return_error: bool) -> str:\n",
|
||||
" \"\"\"Trace the route to the specified url. Must include https:// in the url.\"\"\"\n",
|
||||
" hostname = urlparse(str(url)).netloc\n",
|
||||
" completed_process = subprocess.run(\n",
|
||||
" [\"traceroute\", hostname], capture_output=True, text=True\n",
|
||||
" )\n",
|
||||
" output = completed_process.stdout\n",
|
||||
" if return_error and completed_process.returncode != 0:\n",
|
||||
" return completed_process.stderr\n",
|
||||
" return output\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-3.5-turbo-0613\", temperature=0)\n",
|
||||
"agent = initialize_agent(\n",
|
||||
" llm=llm,\n",
|
||||
" tools=[ping, trace_route],\n",
|
||||
" agent=AgentType.OPENAI_MULTI_FUNCTIONS,\n",
|
||||
" return_intermediate_steps=True, # IMPORTANT!\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"result = agent(\"What's the latency like for https://langchain.com?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2df34eed-45a5-4f91-88d3-9aa55f28391a",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"## Evaluate Trajectory\n",
|
||||
"\n",
|
||||
"Pass the input, trajectory, and pass to the [evaluate_agent_trajectory](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.schema.AgentTrajectoryEvaluator.html#langchain.evaluation.schema.AgentTrajectoryEvaluator.evaluate_agent_trajectory) method."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "8d2c8703-98ed-4068-8a8b-393f0f1f64ea",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 1.0,\n",
|
||||
" 'reasoning': \"i. The final answer is helpful. It directly answers the user's question about the latency for the website https://langchain.com.\\n\\nii. The AI language model uses a logical sequence of tools to answer the question. It uses the 'ping' tool to measure the latency of the website, which is the correct tool for this task.\\n\\niii. The AI language model uses the tool in a helpful way. It inputs the URL into the 'ping' tool and correctly interprets the output to provide the latency in milliseconds.\\n\\niv. The AI language model does not use too many steps to answer the question. It only uses one step, which is appropriate for this type of question.\\n\\nv. The appropriate tool is used to answer the question. The 'ping' tool is the correct tool to measure website latency.\\n\\nGiven these considerations, the AI language model's performance is excellent. It uses the correct tool, interprets the output correctly, and provides a helpful and direct answer to the user's question.\"}"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluation_result = evaluator.evaluate_agent_trajectory(\n",
|
||||
" prediction=result[\"output\"],\n",
|
||||
" input=result[\"input\"],\n",
|
||||
" agent_trajectory=result[\"intermediate_steps\"],\n",
|
||||
")\n",
|
||||
"evaluation_result"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "fc5467c1-ea92-405f-949a-3011388fa9ee",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Configuring the Evaluation LLM\n",
|
||||
"\n",
|
||||
"If you don't select an LLM to use for evaluation, the [load_evaluator](https://api.python.langchain.com/en/latest/evaluation/langchain.evaluation.loading.load_evaluator.html#langchain.evaluation.loading.load_evaluator) function will use `gpt-4` to power the evaluation chain. You can select any chat model for the agent trajectory evaluator as below."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "1f6318f3-642a-4766-bc7a-f91239795ee7",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# %pip install anthropic\n",
|
||||
"# ANTHROPIC_API_KEY=<YOUR ANTHROPIC API KEY>"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "b2852289-5df9-402e-95b5-7efebf0fc943",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatAnthropic\n",
|
||||
"\n",
|
||||
"eval_llm = ChatAnthropic(temperature=0)\n",
|
||||
"evaluator = load_evaluator(\"trajectory\", llm=eval_llm)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "ff72d21a-93b9-4c2f-8613-733d9c9330d7",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 1.0,\n",
|
||||
" 'reasoning': \"Here is my detailed evaluation of the AI's response:\\n\\ni. The final answer is helpful, as it directly provides the latency measurement for the requested website.\\n\\nii. The sequence of using the ping tool to measure latency is logical for this question.\\n\\niii. The ping tool is used in a helpful way, with the website URL provided as input and the output latency measurement extracted.\\n\\niv. Only one step is used, which is appropriate for simply measuring latency. More steps are not needed.\\n\\nv. The ping tool is an appropriate choice to measure latency. \\n\\nIn summary, the AI uses an optimal single step approach with the right tool and extracts the needed output. The final answer directly answers the question in a helpful way.\\n\\nOverall\"}"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluation_result = evaluator.evaluate_agent_trajectory(\n",
|
||||
" prediction=result[\"output\"],\n",
|
||||
" input=result[\"input\"],\n",
|
||||
" agent_trajectory=result[\"intermediate_steps\"],\n",
|
||||
")\n",
|
||||
"evaluation_result"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "95ce4240-f5a0-4810-8d09-b2f4c9e18b7f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Providing List of Valid Tools\n",
|
||||
"\n",
|
||||
"By default, the evaluator doesn't take into account the tools the agent is permitted to call. You can provide these to the evaluator via the `agent_tools` argument.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "24c10566-2ef5-45c5-9213-a8fb28e2ca1f",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.evaluation import load_evaluator\n",
|
||||
"\n",
|
||||
"evaluator = load_evaluator(\"trajectory\", agent_tools=[ping, trace_route])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "7b995786-5b78-4d9e-8e8a-1f2a203113e2",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'score': 1.0,\n",
|
||||
" 'reasoning': \"i. The final answer is helpful. It directly answers the user's question about the latency for the specified website.\\n\\nii. The AI language model uses a logical sequence of tools to answer the question. In this case, only one tool was needed to answer the question, and the model chose the correct one.\\n\\niii. The AI language model uses the tool in a helpful way. The 'ping' tool was used to determine the latency of the website, which was the information the user was seeking.\\n\\niv. The AI language model does not use too many steps to answer the question. Only one step was needed and used.\\n\\nv. The appropriate tool was used to answer the question. The 'ping' tool is designed to measure latency, which was the information the user was seeking.\\n\\nGiven these considerations, the AI language model's performance in answering this question is excellent.\"}"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"evaluation_result = evaluator.evaluate_agent_trajectory(\n",
|
||||
" prediction=result[\"output\"],\n",
|
||||
" input=result[\"input\"],\n",
|
||||
" agent_trajectory=result[\"intermediate_steps\"],\n",
|
||||
")\n",
|
||||
"evaluation_result"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,565 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1a4596ea-a631-416d-a2a4-3577c140493d",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"# LangSmith Walkthrough\n",
|
||||
"\n",
|
||||
"LangChain makes it easy to prototype LLM applications and Agents. However, delivering LLM applications to production can be deceptively difficult. You will likely have to heavily customize and iterate on your prompts, chains, and other components to create a high-quality product.\n",
|
||||
"\n",
|
||||
"To aid in this process, we've launched LangSmith, a unified platform for debugging, testing, and monitoring your LLM applications.\n",
|
||||
"\n",
|
||||
"When might this come in handy? You may find it useful when you want to:\n",
|
||||
"\n",
|
||||
"- Quickly debug a new chain, agent, or set of tools\n",
|
||||
"- Visualize how components (chains, llms, retrievers, etc.) relate and are used\n",
|
||||
"- Evaluate different prompts and LLMs for a single component\n",
|
||||
"- Run a given chain several times over a dataset to ensure it consistently meets a quality bar\n",
|
||||
"- Capture usage traces and using LLMs or analytics pipelines to generate insights"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "138fbb8f-960d-4d26-9dd5-6d6acab3ee55",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Prerequisites\n",
|
||||
"\n",
|
||||
"**[Create a LangSmith account](https://smith.langchain.com/) and create an API key (see bottom left corner). Familiarize yourself with the platform by looking through the [docs](https://docs.smith.langchain.com/)**\n",
|
||||
"\n",
|
||||
"Note LangSmith is in closed beta; we're in the process of rolling it out to more users. However, you can fill out the form on the website for expedited access.\n",
|
||||
"\n",
|
||||
"Now, let's get started!"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2d77d064-41b4-41fb-82e6-2d16461269ec",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"## Log runs to LangSmith\n",
|
||||
"\n",
|
||||
"First, configure your environment variables to tell LangChain to log traces. This is done by setting the `LANGCHAIN_TRACING_V2` environment variable to true.\n",
|
||||
"You can tell LangChain which project to log to by setting the `LANGCHAIN_PROJECT` environment variable (if this isn't set, runs will be logged to the `default` project). This will automatically create the project for you if it doesn't exist. You must also set the `LANGCHAIN_ENDPOINT` and `LANGCHAIN_API_KEY` environment variables.\n",
|
||||
"\n",
|
||||
"For more information on other ways to set up tracing, please reference the [LangSmith documentation](https://docs.smith.langchain.com/docs/)\n",
|
||||
"\n",
|
||||
"**NOTE:** You must also set your `OPENAI_API_KEY` and `SERPAPI_API_KEY` environment variables in order to run the following tutorial.\n",
|
||||
"\n",
|
||||
"**NOTE:** You can only access an API key when you first create it. Keep it somewhere safe.\n",
|
||||
"\n",
|
||||
"**NOTE:** You can also use a context manager in python to log traces using\n",
|
||||
"```python\n",
|
||||
"from langchain.callbacks.manager import tracing_v2_enabled\n",
|
||||
"\n",
|
||||
"with tracing_v2_enabled(project_name=\"My Project\"):\n",
|
||||
" agent.run(\"How many people live in canada as of 2023?\")\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"However, in this example, we will use environment variables."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "904db9a5-f387-4a57-914c-c8af8d39e249",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"from uuid import uuid4\n",
|
||||
"\n",
|
||||
"unique_id = uuid4().hex[0:8]\n",
|
||||
"os.environ[\"LANGCHAIN_TRACING_V2\"] = \"true\"\n",
|
||||
"os.environ[\"LANGCHAIN_PROJECT\"] = f\"Tracing Walkthrough - {unique_id}\"\n",
|
||||
"os.environ[\"LANGCHAIN_ENDPOINT\"] = \"https://api.smith.langchain.com\"\n",
|
||||
"os.environ[\"LANGCHAIN_API_KEY\"] = \"\" # Update to your API key\n",
|
||||
"\n",
|
||||
"# Used by the agent in this tutorial\n",
|
||||
"# os.environ[\"OPENAI_API_KEY\"] = \"<YOUR-OPENAI-API-KEY>\"\n",
|
||||
"# os.environ[\"SERPAPI_API_KEY\"] = \"<YOUR-SERPAPI-API-KEY>\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "8ee7f34b-b65c-4e09-ad52-e3ace78d0221",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"Create the langsmith client to interact with the API"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "510b5ca0",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langsmith import Client\n",
|
||||
"\n",
|
||||
"client = Client()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ca27fa11-ddce-4af0-971e-c5c37d5b92ef",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Create a LangChain component and log runs to the platform. In this example, we will create a ReAct-style agent with access to Search and Calculator as tools. However, LangSmith works regardless of which type of LangChain component you use (LLMs, Chat Models, Tools, Retrievers, Agents are all supported)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "7c801853-8e96-404d-984c-51ace59cbbef",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.agents import AgentType, initialize_agent, load_tools\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(temperature=0)\n",
|
||||
"tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm)\n",
|
||||
"agent = initialize_agent(\n",
|
||||
" tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=False\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "cab51e1e-8270-452c-ba22-22b5b5951899",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We are running the agent concurrently on multiple inputs to reduce latency. Runs get logged to LangSmith in the background so execution latency is unaffected."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "19537902-b95c-4390-80a4-f6c9a937081e",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import asyncio\n",
|
||||
"\n",
|
||||
"inputs = [\n",
|
||||
" \"How many people live in canada as of 2023?\",\n",
|
||||
" \"who is dua lipa's boyfriend? what is his age raised to the .43 power?\",\n",
|
||||
" \"what is dua lipa's boyfriend age raised to the .43 power?\",\n",
|
||||
" \"how far is it from paris to boston in miles\",\n",
|
||||
" \"what was the total number of points scored in the 2023 super bowl? what is that number raised to the .23 power?\",\n",
|
||||
" \"what was the total number of points scored in the 2023 super bowl raised to the .23 power?\",\n",
|
||||
" \"how many more points were scored in the 2023 super bowl than in the 2022 super bowl?\",\n",
|
||||
" \"what is 153 raised to .1312 power?\",\n",
|
||||
" \"who is kendall jenner's boyfriend? what is his height (in inches) raised to .13 power?\",\n",
|
||||
" \"what is 1213 divided by 4345?\",\n",
|
||||
"]\n",
|
||||
"results = []\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"async def arun(agent, input_example):\n",
|
||||
" try:\n",
|
||||
" return await agent.arun(input_example)\n",
|
||||
" except Exception as e:\n",
|
||||
" # The agent sometimes makes mistakes! These will be captured by the tracing.\n",
|
||||
" return e\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"for input_example in inputs:\n",
|
||||
" results.append(arun(agent, input_example))\n",
|
||||
"results = await asyncio.gather(*results)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "0405ff30-21fe-413d-85cf-9fa3c649efec",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.callbacks.tracers.langchain import wait_for_all_tracers\n",
|
||||
"\n",
|
||||
"# Logs are submitted in a background thread to avoid blocking execution.\n",
|
||||
"# For the sake of this tutorial, we want to make sure\n",
|
||||
"# they've been submitted before moving on. This is also\n",
|
||||
"# useful for serverless deployments.\n",
|
||||
"wait_for_all_tracers()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9decb964-be07-4b6c-9802-9825c8be7b64",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Assuming you've successfully set up your environment, your agent traces should show up in the `Projects` section in the [app](https://smith.langchain.com/). Congrats!"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6c43c311-4e09-4d57-9ef3-13afb96ff430",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Evaluate another agent implementation\n",
|
||||
"\n",
|
||||
"In addition to logging runs, LangSmith also allows you to test and evaluate your LLM applications.\n",
|
||||
"\n",
|
||||
"In this section, you will leverage LangSmith to create a benchmark dataset and run AI-assisted evaluators on an agent. You will do so in a few steps:\n",
|
||||
"\n",
|
||||
"1. Create a dataset from pre-existing run inputs and outputs\n",
|
||||
"2. Initialize a new agent to benchmark\n",
|
||||
"3. Configure evaluators to grade an agent's output\n",
|
||||
"4. Run the agent over the dataset and evaluate the results"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "beab1a29-b79d-4a99-b5b1-0870c2d772b1",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### 1. Create a LangSmith dataset\n",
|
||||
"\n",
|
||||
"Below, we use the LangSmith client to create a dataset from the agent runs you just logged above. You will use these later to measure performance for a new agent. This is simply taking the inputs and outputs of the runs and saving them as examples to a dataset. A dataset is a collection of examples, which are nothing more than input-output pairs you can use as test cases to your application.\n",
|
||||
"\n",
|
||||
"**Note: this is a simple, walkthrough example. In a real-world setting, you'd ideally first validate the outputs before adding them to a benchmark dataset to be used for evaluating other agents.**\n",
|
||||
"\n",
|
||||
"For more information on datasets, including how to create them from CSVs or other files or how to create them in the platform, please refer to the [LangSmith documentation](https://docs.smith.langchain.com/)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "17580c4b-bd04-4dde-9d21-9d4edd25b00d",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"dataset_name = f\"calculator-example-dataset-{unique_id}\"\n",
|
||||
"\n",
|
||||
"dataset = client.create_dataset(\n",
|
||||
" dataset_name, description=\"A calculator example dataset\"\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"runs = client.list_runs(\n",
|
||||
" project_name=os.environ[\"LANGCHAIN_PROJECT\"],\n",
|
||||
" execution_order=1, # Only return the top-level runs\n",
|
||||
" error=False, # Only runs that succeed\n",
|
||||
")\n",
|
||||
"for run in runs:\n",
|
||||
" client.create_example(inputs=run.inputs, outputs=run.outputs, dataset_id=dataset.id)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "8adfd29c-b258-49e5-94b4-74597a12ba16",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"### 2. Initialize a new agent to benchmark\n",
|
||||
"\n",
|
||||
"You can evaluate any LLM, chain, or agent. Since chains can have memory, we will pass in a `chain_factory` (aka a `constructor` ) function to initialize for each call.\n",
|
||||
"\n",
|
||||
"In this case, we will test an agent that uses OpenAI's function calling endpoints."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "f42d8ecc-d46a-448b-a89c-04b0f6907f75",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.agents import AgentType, initialize_agent, load_tools\n",
|
||||
"\n",
|
||||
"llm = ChatOpenAI(model=\"gpt-3.5-turbo-0613\", temperature=0)\n",
|
||||
"tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Since chains can be stateful (e.g. they can have memory), we provide\n",
|
||||
"# a way to initialize a new chain for each row in the dataset. This is done\n",
|
||||
"# by passing in a factory function that returns a new chain for each row.\n",
|
||||
"def agent_factory():\n",
|
||||
" return initialize_agent(tools, llm, agent=AgentType.OPENAI_FUNCTIONS, verbose=False)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# If your chain is NOT stateful, your factory can return the object directly\n",
|
||||
"# to improve runtime performance. For example:\n",
|
||||
"# chain_factory = lambda: agent"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9cb9ef53",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### 3. Configure evaluation\n",
|
||||
"\n",
|
||||
"Manually comparing the results of chains in the UI is effective, but it can be time consuming.\n",
|
||||
"It can be helpful to use automated metrics and AI-assisted feedback to evaluate your component's performance.\n",
|
||||
"\n",
|
||||
"Below, we will create some pre-implemented run evaluators that do the following:\n",
|
||||
"- Compare results against ground truth labels. (You used the debug outputs above for this)\n",
|
||||
"- Measure semantic (dis)similarity using embedding distance\n",
|
||||
"- Evaluate 'aspects' of the agent's response in a reference-free manner using custom criteria\n",
|
||||
"\n",
|
||||
"For a longer discussion of how to select an appropriate evaluator for your use case and how to create your own\n",
|
||||
"custom evaluators, please refer to the [LangSmith documentation](https://docs.smith.langchain.com/).\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "a25dc281",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.evaluation import EvaluatorType\n",
|
||||
"from langchain.smith import RunEvalConfig\n",
|
||||
"\n",
|
||||
"evaluation_config = RunEvalConfig(\n",
|
||||
" # Evaluators can either be an evaluator type (e.g., \"qa\", \"criteria\", \"embedding_distance\", etc.) or a configuration for that evaluator\n",
|
||||
" evaluators=[\n",
|
||||
" # Measures whether a QA response is \"Correct\", based on a reference answer\n",
|
||||
" # You can also select via the raw string \"qa\"\n",
|
||||
" EvaluatorType.QA,\n",
|
||||
" # Measure the embedding distance between the output and the reference answer\n",
|
||||
" # Equivalent to: EvalConfig.EmbeddingDistance(embeddings=OpenAIEmbeddings())\n",
|
||||
" EvaluatorType.EMBEDDING_DISTANCE,\n",
|
||||
" # Grade whether the output satisfies the stated criteria. You can select a default one such as \"helpfulness\" or provide your own.\n",
|
||||
" RunEvalConfig.LabeledCriteria(\"helpfulness\"),\n",
|
||||
" # Both the Criteria and LabeledCriteria evaluators can be configured with a dictionary of custom criteria.\n",
|
||||
" RunEvalConfig.Criteria(\n",
|
||||
" {\n",
|
||||
" \"fifth-grader-score\": \"Do you have to be smarter than a fifth grader to answer this question?\"\n",
|
||||
" }\n",
|
||||
" ),\n",
|
||||
" ],\n",
|
||||
" # You can add custom StringEvaluator or RunEvaluator objects here as well, which will automatically be\n",
|
||||
" # applied to each prediction. Check out the docs for examples.\n",
|
||||
" custom_evaluators=[],\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "07885b10",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"### 4. Run the agent and evaluators\n",
|
||||
"\n",
|
||||
"Use the [arun_on_dataset](https://api.python.langchain.com/en/latest/smith/langchain.smith.evaluation.runner_utils.arun_on_dataset.html#langchain.smith.evaluation.runner_utils.arun_on_dataset) (or synchronous [run_on_dataset](https://api.python.langchain.com/en/latest/smith/langchain.smith.evaluation.runner_utils.run_on_dataset.html#langchain.smith.evaluation.runner_utils.run_on_dataset)) function to evaluate your model. This will:\n",
|
||||
"1. Fetch example rows from the specified dataset\n",
|
||||
"2. Run your llm or chain on each example.\n",
|
||||
"3. Apply evalutors to the resulting run traces and corresponding reference examples to generate automated feedback.\n",
|
||||
"\n",
|
||||
"The results will be visible in the LangSmith app."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "3733269b-8085-4644-9d5d-baedcff13a2f",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"View the evaluation results for project '2023-07-17-11-25-20-AgentExecutor' at:\n",
|
||||
"https://dev.smith.langchain.com/projects/p/1c9baec3-ae86-4fac-9e99-e1b9f8e7818c?eval=true\n",
|
||||
"Processed examples: 1\r"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Chain failed for example 5a2ac8da-8c2b-4d12-acb9-5c4b0f47fe8a. Error: LLMMathChain._evaluate(\"\n",
|
||||
"age_of_Dua_Lipa_boyfriend ** 0.43\n",
|
||||
"\") raised error: 'age_of_Dua_Lipa_boyfriend'. Please try again with a valid numerical expression\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Processed examples: 4\r"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Chain failed for example 91439261-1c86-4198-868b-a6c1cc8a051b. Error: Too many arguments to single-input tool Calculator. Args: ['height ^ 0.13', {'height': 68}]\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Processed examples: 9\r"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.smith import (\n",
|
||||
" arun_on_dataset,\n",
|
||||
" run_on_dataset, # Available if your chain doesn't support async calls.\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"chain_results = await arun_on_dataset(\n",
|
||||
" client=client,\n",
|
||||
" dataset_name=dataset_name,\n",
|
||||
" llm_or_chain_factory=agent_factory,\n",
|
||||
" evaluation=evaluation_config,\n",
|
||||
" verbose=True,\n",
|
||||
" tags=[\"testing-notebook\"], # Optional, adds a tag to the resulting chain runs\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# Sometimes, the agent will error due to parsing issues, incompatible tool inputs, etc.\n",
|
||||
"# These are logged as warnings here and captured as errors in the tracing UI."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "cdacd159-eb4d-49e9-bb2a-c55322c40ed4",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"### Review the test results\n",
|
||||
"\n",
|
||||
"You can review the test results tracing UI below by navigating to the \"Datasets & Testing\" page and selecting the **\"calculator-example-dataset-*\"** dataset, clicking on the `Test Runs` tab, then inspecting the runs in the corresponding project. \n",
|
||||
"\n",
|
||||
"This will show the new runs and the feedback logged from the selected evaluators. Note that runs that error out will not have feedback."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "591c819e-9932-45cf-adab-63727dd49559",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Exporting datasets and runs\n",
|
||||
"\n",
|
||||
"LangSmith lets you export data to common formats such as CSV or JSONL directly in the web app. You can also use the client to fetch runs for further analysis, to store in your own database, or to share with others. Let's fetch the run traces from the evaluation run."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "33bfefde-d1bb-4f50-9f7a-fd572ee76820",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"Run(id=UUID('e39f310b-c5a8-4192-8a59-6a9498e1cb85'), name='AgentExecutor', start_time=datetime.datetime(2023, 7, 17, 18, 25, 30, 653872), run_type=<RunTypeEnum.chain: 'chain'>, end_time=datetime.datetime(2023, 7, 17, 18, 25, 35, 359642), extra={'runtime': {'library': 'langchain', 'runtime': 'python', 'platform': 'macOS-13.4.1-arm64-arm-64bit', 'sdk_version': '0.0.8', 'library_version': '0.0.231', 'runtime_version': '3.11.2'}, 'total_tokens': 512, 'prompt_tokens': 451, 'completion_tokens': 61}, error=None, serialized=None, events=[{'name': 'start', 'time': '2023-07-17T18:25:30.653872'}, {'name': 'end', 'time': '2023-07-17T18:25:35.359642'}], inputs={'input': 'what is 1213 divided by 4345?'}, outputs={'output': '1213 divided by 4345 is approximately 0.2792.'}, reference_example_id=UUID('a75cf754-4f73-46fd-b126-9bcd0695e463'), parent_run_id=None, tags=['openai-functions', 'testing-notebook'], execution_order=1, session_id=UUID('1c9baec3-ae86-4fac-9e99-e1b9f8e7818c'), child_run_ids=[UUID('40d0fdca-0b2b-47f4-a9da-f2b229aa4ed5'), UUID('cfa5130f-264c-4126-8950-ec1c4c31b800'), UUID('ba638a2f-2a57-45db-91e8-9a7a66a42c5a'), UUID('fcc29b5a-cdb7-4bcc-8194-47729bbdf5fb'), UUID('a6f92bf5-cfba-4747-9336-370cb00c928a'), UUID('65312576-5a39-4250-b820-4dfae7d73945')], child_runs=None, feedback_stats={'correctness': {'n': 1, 'avg': 1.0, 'mode': 1}, 'helpfulness': {'n': 1, 'avg': 1.0, 'mode': 1}, 'fifth-grader-score': {'n': 1, 'avg': 1.0, 'mode': 1}, 'embedding_cosine_distance': {'n': 1, 'avg': 0.144522385071361, 'mode': 0.144522385071361}})"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"runs = list(client.list_runs(dataset_name=dataset_name))\n",
|
||||
"runs[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "6595c888-1f5c-4ae3-9390-0a559f5575d1",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'correctness': {'n': 7, 'avg': 0.5714285714285714, 'mode': 1},\n",
|
||||
" 'helpfulness': {'n': 7, 'avg': 0.7142857142857143, 'mode': 1},\n",
|
||||
" 'fifth-grader-score': {'n': 7, 'avg': 0.7142857142857143, 'mode': 1},\n",
|
||||
" 'embedding_cosine_distance': {'n': 7,\n",
|
||||
" 'avg': 0.11462010799473926,\n",
|
||||
" 'mode': 0.0130477459560272}}"
|
||||
]
|
||||
},
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"client.read_project(project_id=runs[0].session_id).feedback_stats"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2646f0fb-81d4-43ce-8a9b-54b8e19841e2",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"## Conclusion\n",
|
||||
"\n",
|
||||
"Congratulations! You have succesfully traced and evaluated an agent using LangSmith!\n",
|
||||
"\n",
|
||||
"This was a quick guide to get started, but there are many more ways to use LangSmith to speed up your developer flow and produce better results.\n",
|
||||
"\n",
|
||||
"For more information on how you can get the most out of LangSmith, check out [LangSmith documentation](https://docs.smith.langchain.com/), and please reach out with questions, feature requests, or feedback at [support@langchain.dev](mailto:support@langchain.dev)."
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,262 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "920a3c1a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Model comparison\n",
|
||||
"\n",
|
||||
"Constructing your language model application will likely involved choosing between many different options of prompts, models, and even chains to use. When doing so, you will want to compare these different options on different inputs in an easy, flexible, and intuitive way. \n",
|
||||
"\n",
|
||||
"LangChain provides the concept of a ModelLaboratory to test out and try different models."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "ab9e95ad",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain import LLMChain, OpenAI, Cohere, HuggingFaceHub, PromptTemplate\n",
|
||||
"from langchain.model_laboratory import ModelLaboratory"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "32cb94e6",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"llms = [\n",
|
||||
" OpenAI(temperature=0),\n",
|
||||
" Cohere(model=\"command-xlarge-20221108\", max_tokens=20, temperature=0),\n",
|
||||
" HuggingFaceHub(repo_id=\"google/flan-t5-xl\", model_kwargs={\"temperature\": 1}),\n",
|
||||
"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "14cde09d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"model_lab = ModelLaboratory.from_llms(llms)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "f186c741",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\u001b[1mInput:\u001b[0m\n",
|
||||
"What color is a flamingo?\n",
|
||||
"\n",
|
||||
"\u001b[1mOpenAI\u001b[0m\n",
|
||||
"Params: {'model': 'text-davinci-002', 'temperature': 0.0, 'max_tokens': 256, 'top_p': 1, 'frequency_penalty': 0, 'presence_penalty': 0, 'n': 1, 'best_of': 1}\n",
|
||||
"\u001b[36;1m\u001b[1;3m\n",
|
||||
"\n",
|
||||
"Flamingos are pink.\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1mCohere\u001b[0m\n",
|
||||
"Params: {'model': 'command-xlarge-20221108', 'max_tokens': 20, 'temperature': 0.0, 'k': 0, 'p': 1, 'frequency_penalty': 0, 'presence_penalty': 0}\n",
|
||||
"\u001b[33;1m\u001b[1;3m\n",
|
||||
"\n",
|
||||
"Pink\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1mHuggingFaceHub\u001b[0m\n",
|
||||
"Params: {'repo_id': 'google/flan-t5-xl', 'temperature': 1}\n",
|
||||
"\u001b[38;5;200m\u001b[1;3mpink\u001b[0m\n",
|
||||
"\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"model_lab.compare(\"What color is a flamingo?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "248b652a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"prompt = PromptTemplate(\n",
|
||||
" template=\"What is the capital of {state}?\", input_variables=[\"state\"]\n",
|
||||
")\n",
|
||||
"model_lab_with_prompt = ModelLaboratory.from_llms(llms, prompt=prompt)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "f64377ac",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\u001b[1mInput:\u001b[0m\n",
|
||||
"New York\n",
|
||||
"\n",
|
||||
"\u001b[1mOpenAI\u001b[0m\n",
|
||||
"Params: {'model': 'text-davinci-002', 'temperature': 0.0, 'max_tokens': 256, 'top_p': 1, 'frequency_penalty': 0, 'presence_penalty': 0, 'n': 1, 'best_of': 1}\n",
|
||||
"\u001b[36;1m\u001b[1;3m\n",
|
||||
"\n",
|
||||
"The capital of New York is Albany.\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1mCohere\u001b[0m\n",
|
||||
"Params: {'model': 'command-xlarge-20221108', 'max_tokens': 20, 'temperature': 0.0, 'k': 0, 'p': 1, 'frequency_penalty': 0, 'presence_penalty': 0}\n",
|
||||
"\u001b[33;1m\u001b[1;3m\n",
|
||||
"\n",
|
||||
"The capital of New York is Albany.\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1mHuggingFaceHub\u001b[0m\n",
|
||||
"Params: {'repo_id': 'google/flan-t5-xl', 'temperature': 1}\n",
|
||||
"\u001b[38;5;200m\u001b[1;3mst john s\u001b[0m\n",
|
||||
"\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"model_lab_with_prompt.compare(\"New York\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "54336dbf",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain import SelfAskWithSearchChain, SerpAPIWrapper\n",
|
||||
"\n",
|
||||
"open_ai_llm = OpenAI(temperature=0)\n",
|
||||
"search = SerpAPIWrapper()\n",
|
||||
"self_ask_with_search_openai = SelfAskWithSearchChain(\n",
|
||||
" llm=open_ai_llm, search_chain=search, verbose=True\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"cohere_llm = Cohere(temperature=0, model=\"command-xlarge-20221108\")\n",
|
||||
"search = SerpAPIWrapper()\n",
|
||||
"self_ask_with_search_cohere = SelfAskWithSearchChain(\n",
|
||||
" llm=cohere_llm, search_chain=search, verbose=True\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "6a50a9f1",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chains = [self_ask_with_search_openai, self_ask_with_search_cohere]\n",
|
||||
"names = [str(open_ai_llm), str(cohere_llm)]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "d3549e99",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"model_lab = ModelLaboratory(chains, names=names)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "362f7f57",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\u001b[1mInput:\u001b[0m\n",
|
||||
"What is the hometown of the reigning men's U.S. Open champion?\n",
|
||||
"\n",
|
||||
"\u001b[1mOpenAI\u001b[0m\n",
|
||||
"Params: {'model': 'text-davinci-002', 'temperature': 0.0, 'max_tokens': 256, 'top_p': 1, 'frequency_penalty': 0, 'presence_penalty': 0, 'n': 1, 'best_of': 1}\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new chain...\u001b[0m\n",
|
||||
"What is the hometown of the reigning men's U.S. Open champion?\n",
|
||||
"Are follow up questions needed here:\u001b[32;1m\u001b[1;3m Yes.\n",
|
||||
"Follow up: Who is the reigning men's U.S. Open champion?\u001b[0m\n",
|
||||
"Intermediate answer: \u001b[33;1m\u001b[1;3mCarlos Alcaraz.\u001b[0m\u001b[32;1m\u001b[1;3m\n",
|
||||
"Follow up: Where is Carlos Alcaraz from?\u001b[0m\n",
|
||||
"Intermediate answer: \u001b[33;1m\u001b[1;3mEl Palmar, Spain.\u001b[0m\u001b[32;1m\u001b[1;3m\n",
|
||||
"So the final answer is: El Palmar, Spain\u001b[0m\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n",
|
||||
"\u001b[36;1m\u001b[1;3m\n",
|
||||
"So the final answer is: El Palmar, Spain\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1mCohere\u001b[0m\n",
|
||||
"Params: {'model': 'command-xlarge-20221108', 'max_tokens': 256, 'temperature': 0.0, 'k': 0, 'p': 1, 'frequency_penalty': 0, 'presence_penalty': 0}\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new chain...\u001b[0m\n",
|
||||
"What is the hometown of the reigning men's U.S. Open champion?\n",
|
||||
"Are follow up questions needed here:\u001b[32;1m\u001b[1;3m Yes.\n",
|
||||
"Follow up: Who is the reigning men's U.S. Open champion?\u001b[0m\n",
|
||||
"Intermediate answer: \u001b[33;1m\u001b[1;3mCarlos Alcaraz.\u001b[0m\u001b[32;1m\u001b[1;3m\n",
|
||||
"So the final answer is:\n",
|
||||
"\n",
|
||||
"Carlos Alcaraz\u001b[0m\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n",
|
||||
"\u001b[33;1m\u001b[1;3m\n",
|
||||
"So the final answer is:\n",
|
||||
"\n",
|
||||
"Carlos Alcaraz\u001b[0m\n",
|
||||
"\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"model_lab.compare(\"What is the hometown of the reigning men's U.S. Open champion?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "94159131",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,423 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Argilla\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
">[Argilla](https://argilla.io/) is an open-source data curation platform for LLMs.\n",
|
||||
"> Using Argilla, everyone can build robust language models through faster data curation \n",
|
||||
"> using both human and machine feedback. We provide support for each step in the MLOps cycle, \n",
|
||||
"> from data labeling to model monitoring.\n",
|
||||
"\n",
|
||||
"<a target=\"_blank\" href=\"https://colab.research.google.com/github/hwchase17/langchain/blob/master/docs/integrations/callbacks/argilla.html\">\n",
|
||||
" <img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/>\n",
|
||||
"</a>"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"In this guide we will demonstrate how to track the inputs and reponses of your LLM to generate a dataset in Argilla, using the `ArgillaCallbackHandler`.\n",
|
||||
"\n",
|
||||
"It's useful to keep track of the inputs and outputs of your LLMs to generate datasets for future fine-tuning. This is especially useful when you're using a LLM to generate data for a specific task, such as question answering, summarization, or translation."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"## Installation and Setup"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install argilla --upgrade\n",
|
||||
"!pip install openai"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Getting API Credentials\n",
|
||||
"\n",
|
||||
"To get the Argilla API credentials, follow the next steps:\n",
|
||||
"\n",
|
||||
"1. Go to your Argilla UI.\n",
|
||||
"2. Click on your profile picture and go to \"My settings\".\n",
|
||||
"3. Then copy the API Key.\n",
|
||||
"\n",
|
||||
"In Argilla the API URL will be the same as the URL of your Argilla UI.\n",
|
||||
"\n",
|
||||
"To get the OpenAI API credentials, please visit https://platform.openai.com/account/api-keys"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"ARGILLA_API_URL\"] = \"...\"\n",
|
||||
"os.environ[\"ARGILLA_API_KEY\"] = \"...\"\n",
|
||||
"\n",
|
||||
"os.environ[\"OPENAI_API_KEY\"] = \"...\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Setup Argilla\n",
|
||||
"\n",
|
||||
"To use the `ArgillaCallbackHandler` we will need to create a new `FeedbackDataset` in Argilla to keep track of your LLM experiments. To do so, please use the following code:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import argilla as rg"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from packaging.version import parse as parse_version\n",
|
||||
"\n",
|
||||
"if parse_version(rg.__version__) < parse_version(\"1.8.0\"):\n",
|
||||
" raise RuntimeError(\n",
|
||||
" \"`FeedbackDataset` is only available in Argilla v1.8.0 or higher, please \"\n",
|
||||
" \"upgrade `argilla` as `pip install argilla --upgrade`.\"\n",
|
||||
" )"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"dataset = rg.FeedbackDataset(\n",
|
||||
" fields=[\n",
|
||||
" rg.TextField(name=\"prompt\"),\n",
|
||||
" rg.TextField(name=\"response\"),\n",
|
||||
" ],\n",
|
||||
" questions=[\n",
|
||||
" rg.RatingQuestion(\n",
|
||||
" name=\"response-rating\",\n",
|
||||
" description=\"How would you rate the quality of the response?\",\n",
|
||||
" values=[1, 2, 3, 4, 5],\n",
|
||||
" required=True,\n",
|
||||
" ),\n",
|
||||
" rg.TextQuestion(\n",
|
||||
" name=\"response-feedback\",\n",
|
||||
" description=\"What feedback do you have for the response?\",\n",
|
||||
" required=False,\n",
|
||||
" ),\n",
|
||||
" ],\n",
|
||||
" guidelines=\"You're asked to rate the quality of the response and provide feedback.\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"rg.init(\n",
|
||||
" api_url=os.environ[\"ARGILLA_API_URL\"],\n",
|
||||
" api_key=os.environ[\"ARGILLA_API_KEY\"],\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"dataset.push_to_argilla(\"langchain-dataset\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"> 📌 NOTE: at the moment, just the prompt-response pairs are supported as `FeedbackDataset.fields`, so the `ArgillaCallbackHandler` will just track the prompt i.e. the LLM input, and the response i.e. the LLM output."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Tracking"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"To use the `ArgillaCallbackHandler` you can either use the following code, or just reproduce one of the examples presented in the following sections."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.callbacks import ArgillaCallbackHandler\n",
|
||||
"\n",
|
||||
"argilla_callback = ArgillaCallbackHandler(\n",
|
||||
" dataset_name=\"langchain-dataset\",\n",
|
||||
" api_url=os.environ[\"ARGILLA_API_URL\"],\n",
|
||||
" api_key=os.environ[\"ARGILLA_API_KEY\"],\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Scenario 1: Tracking an LLM\n",
|
||||
"\n",
|
||||
"First, let's just run a single LLM a few times and capture the resulting prompt-response pairs in Argilla."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"LLMResult(generations=[[Generation(text='\\n\\nQ: What did the fish say when he hit the wall? \\nA: Dam.', generation_info={'finish_reason': 'stop', 'logprobs': None})], [Generation(text='\\n\\nThe Moon \\n\\nThe moon is high in the midnight sky,\\nSparkling like a star above.\\nThe night so peaceful, so serene,\\nFilling up the air with love.\\n\\nEver changing and renewing,\\nA never-ending light of grace.\\nThe moon remains a constant view,\\nA reminder of life’s gentle pace.\\n\\nThrough time and space it guides us on,\\nA never-fading beacon of hope.\\nThe moon shines down on us all,\\nAs it continues to rise and elope.', generation_info={'finish_reason': 'stop', 'logprobs': None})], [Generation(text='\\n\\nQ. What did one magnet say to the other magnet?\\nA. \"I find you very attractive!\"', generation_info={'finish_reason': 'stop', 'logprobs': None})], [Generation(text=\"\\n\\nThe world is charged with the grandeur of God.\\nIt will flame out, like shining from shook foil;\\nIt gathers to a greatness, like the ooze of oil\\nCrushed. Why do men then now not reck his rod?\\n\\nGenerations have trod, have trod, have trod;\\nAnd all is seared with trade; bleared, smeared with toil;\\nAnd wears man's smudge and shares man's smell: the soil\\nIs bare now, nor can foot feel, being shod.\\n\\nAnd for all this, nature is never spent;\\nThere lives the dearest freshness deep down things;\\nAnd though the last lights off the black West went\\nOh, morning, at the brown brink eastward, springs —\\n\\nBecause the Holy Ghost over the bent\\nWorld broods with warm breast and with ah! bright wings.\\n\\n~Gerard Manley Hopkins\", generation_info={'finish_reason': 'stop', 'logprobs': None})], [Generation(text='\\n\\nQ: What did one ocean say to the other ocean?\\nA: Nothing, they just waved.', generation_info={'finish_reason': 'stop', 'logprobs': None})], [Generation(text=\"\\n\\nA poem for you\\n\\nOn a field of green\\n\\nThe sky so blue\\n\\nA gentle breeze, the sun above\\n\\nA beautiful world, for us to love\\n\\nLife is a journey, full of surprise\\n\\nFull of joy and full of surprise\\n\\nBe brave and take small steps\\n\\nThe future will be revealed with depth\\n\\nIn the morning, when dawn arrives\\n\\nA fresh start, no reason to hide\\n\\nSomewhere down the road, there's a heart that beats\\n\\nBelieve in yourself, you'll always succeed.\", generation_info={'finish_reason': 'stop', 'logprobs': None})]], llm_output={'token_usage': {'completion_tokens': 504, 'total_tokens': 528, 'prompt_tokens': 24}, 'model_name': 'text-davinci-003'})"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.callbacks import ArgillaCallbackHandler, StdOutCallbackHandler\n",
|
||||
"from langchain.llms import OpenAI\n",
|
||||
"\n",
|
||||
"argilla_callback = ArgillaCallbackHandler(\n",
|
||||
" dataset_name=\"langchain-dataset\",\n",
|
||||
" api_url=os.environ[\"ARGILLA_API_URL\"],\n",
|
||||
" api_key=os.environ[\"ARGILLA_API_KEY\"],\n",
|
||||
")\n",
|
||||
"callbacks = [StdOutCallbackHandler(), argilla_callback]\n",
|
||||
"\n",
|
||||
"llm = OpenAI(temperature=0.9, callbacks=callbacks)\n",
|
||||
"llm.generate([\"Tell me a joke\", \"Tell me a poem\"] * 3)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"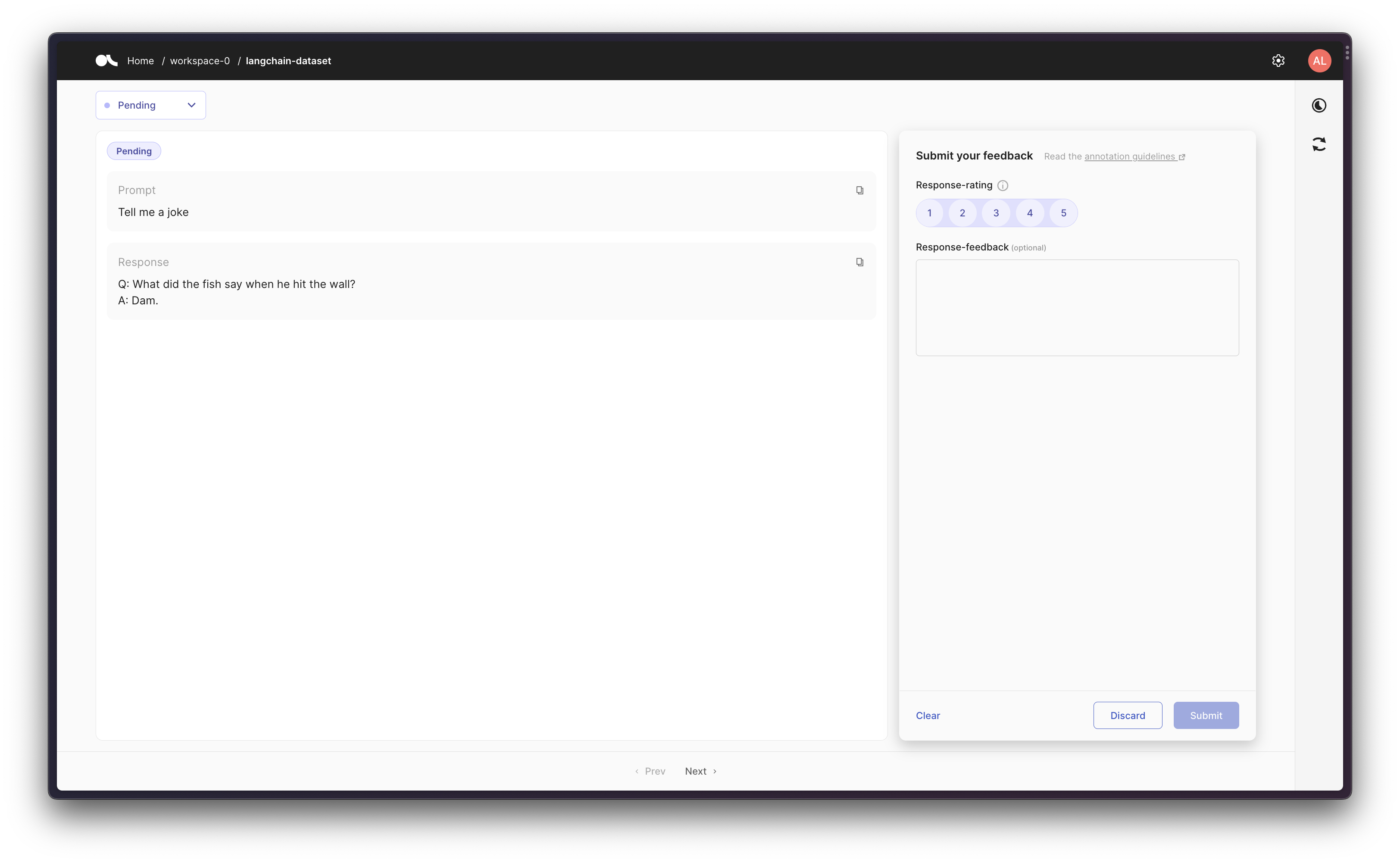"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Scenario 2: Tracking an LLM in a chain\n",
|
||||
"\n",
|
||||
"Then we can create a chain using a prompt template, and then track the initial prompt and the final response in Argilla."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new LLMChain chain...\u001b[0m\n",
|
||||
"Prompt after formatting:\n",
|
||||
"\u001b[32;1m\u001b[1;3mYou are a playwright. Given the title of play, it is your job to write a synopsis for that title.\n",
|
||||
"Title: Documentary about Bigfoot in Paris\n",
|
||||
"Playwright: This is a synopsis for the above play:\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[{'text': \"\\n\\nDocumentary about Bigfoot in Paris focuses on the story of a documentary filmmaker and their search for evidence of the legendary Bigfoot creature in the city of Paris. The play follows the filmmaker as they explore the city, meeting people from all walks of life who have had encounters with the mysterious creature. Through their conversations, the filmmaker unravels the story of Bigfoot and finds out the truth about the creature's presence in Paris. As the story progresses, the filmmaker learns more and more about the mysterious creature, as well as the different perspectives of the people living in the city, and what they think of the creature. In the end, the filmmaker's findings lead them to some surprising and heartwarming conclusions about the creature's existence and the importance it holds in the lives of the people in Paris.\"}]"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.callbacks import ArgillaCallbackHandler, StdOutCallbackHandler\n",
|
||||
"from langchain.llms import OpenAI\n",
|
||||
"from langchain.chains import LLMChain\n",
|
||||
"from langchain.prompts import PromptTemplate\n",
|
||||
"\n",
|
||||
"argilla_callback = ArgillaCallbackHandler(\n",
|
||||
" dataset_name=\"langchain-dataset\",\n",
|
||||
" api_url=os.environ[\"ARGILLA_API_URL\"],\n",
|
||||
" api_key=os.environ[\"ARGILLA_API_KEY\"],\n",
|
||||
")\n",
|
||||
"callbacks = [StdOutCallbackHandler(), argilla_callback]\n",
|
||||
"llm = OpenAI(temperature=0.9, callbacks=callbacks)\n",
|
||||
"\n",
|
||||
"template = \"\"\"You are a playwright. Given the title of play, it is your job to write a synopsis for that title.\n",
|
||||
"Title: {title}\n",
|
||||
"Playwright: This is a synopsis for the above play:\"\"\"\n",
|
||||
"prompt_template = PromptTemplate(input_variables=[\"title\"], template=template)\n",
|
||||
"synopsis_chain = LLMChain(llm=llm, prompt=prompt_template, callbacks=callbacks)\n",
|
||||
"\n",
|
||||
"test_prompts = [{\"title\": \"Documentary about Bigfoot in Paris\"}]\n",
|
||||
"synopsis_chain.apply(test_prompts)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"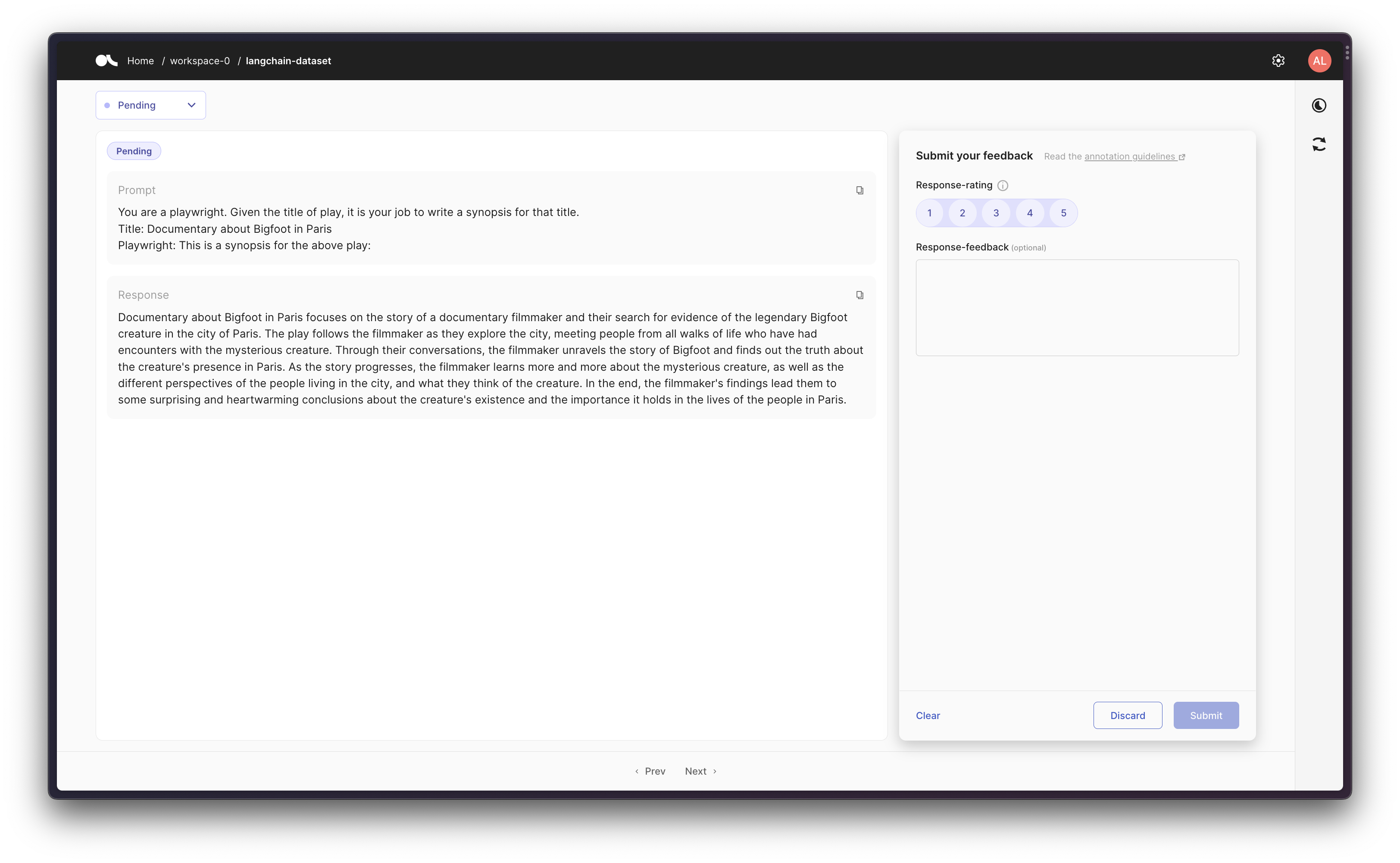"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Scenario 3: Using an Agent with Tools\n",
|
||||
"\n",
|
||||
"Finally, as a more advanced workflow, you can create an agent that uses some tools. So that `ArgillaCallbackHandler` will keep track of the input and the output, but not about the intermediate steps/thoughts, so that given a prompt we log the original prompt and the final response to that given prompt."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"> Note that for this scenario we'll be using Google Search API (Serp API) so you will need to both install `google-search-results` as `pip install google-search-results`, and to set the Serp API Key as `os.environ[\"SERPAPI_API_KEY\"] = \"...\"` (you can find it at https://serpapi.com/dashboard), otherwise the example below won't work."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"\n",
|
||||
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
||||
"\u001b[32;1m\u001b[1;3m I need to answer a historical question\n",
|
||||
"Action: Search\n",
|
||||
"Action Input: \"who was the first president of the United States of America\" \u001b[0m\n",
|
||||
"Observation: \u001b[36;1m\u001b[1;3mGeorge Washington\u001b[0m\n",
|
||||
"Thought:\u001b[32;1m\u001b[1;3m George Washington was the first president\n",
|
||||
"Final Answer: George Washington was the first president of the United States of America.\u001b[0m\n",
|
||||
"\n",
|
||||
"\u001b[1m> Finished chain.\u001b[0m\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'George Washington was the first president of the United States of America.'"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.agents import AgentType, initialize_agent, load_tools\n",
|
||||
"from langchain.callbacks import ArgillaCallbackHandler, StdOutCallbackHandler\n",
|
||||
"from langchain.llms import OpenAI\n",
|
||||
"\n",
|
||||
"argilla_callback = ArgillaCallbackHandler(\n",
|
||||
" dataset_name=\"langchain-dataset\",\n",
|
||||
" api_url=os.environ[\"ARGILLA_API_URL\"],\n",
|
||||
" api_key=os.environ[\"ARGILLA_API_KEY\"],\n",
|
||||
")\n",
|
||||
"callbacks = [StdOutCallbackHandler(), argilla_callback]\n",
|
||||
"llm = OpenAI(temperature=0.9, callbacks=callbacks)\n",
|
||||
"\n",
|
||||
"tools = load_tools([\"serpapi\"], llm=llm, callbacks=callbacks)\n",
|
||||
"agent = initialize_agent(\n",
|
||||
" tools,\n",
|
||||
" llm,\n",
|
||||
" agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,\n",
|
||||
" callbacks=callbacks,\n",
|
||||
")\n",
|
||||
"agent.run(\"Who was the first president of the United States of America?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"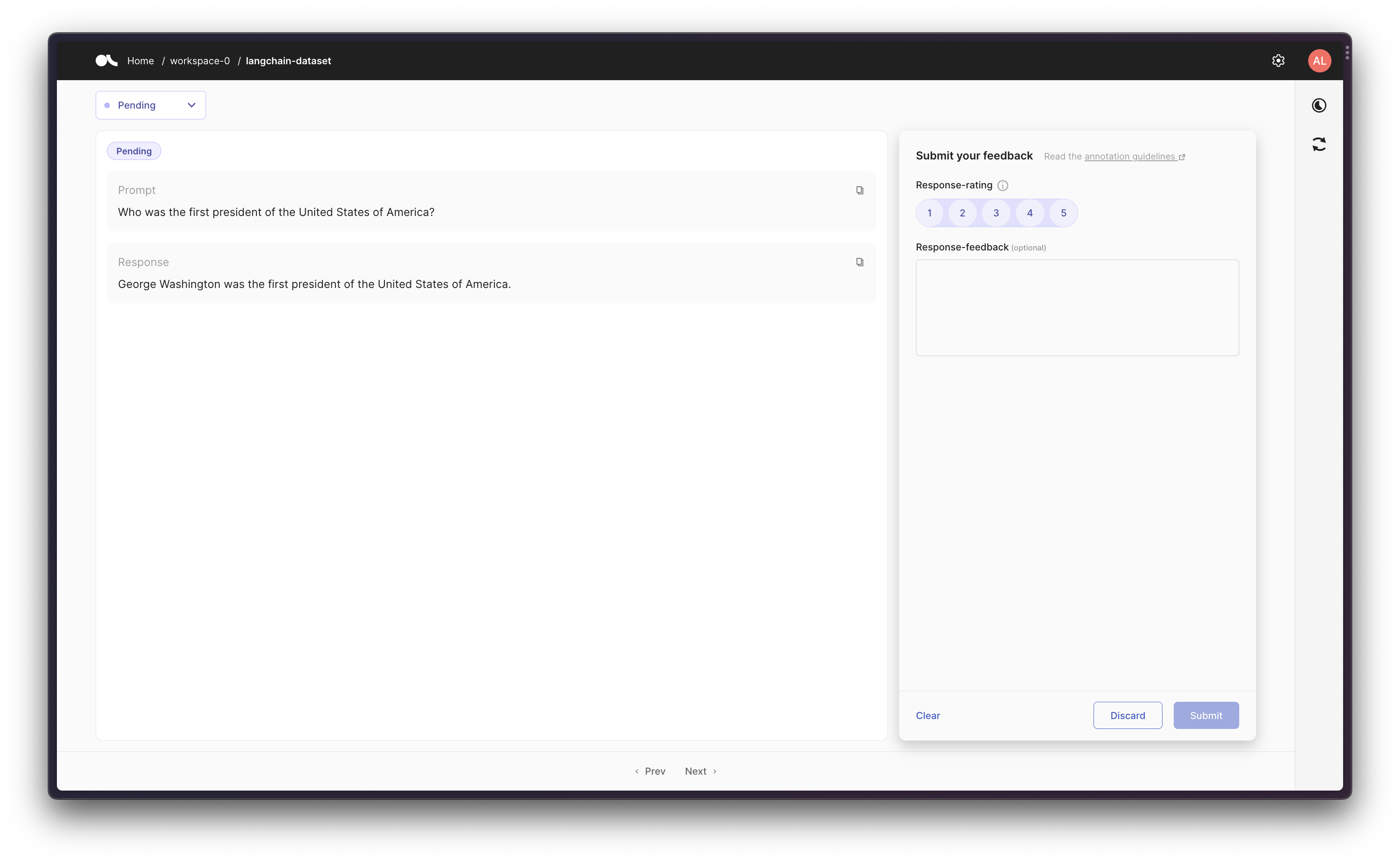"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.3"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "a53ebf4a859167383b364e7e7521d0add3c2dbbdecce4edf676e8c4634ff3fbb"
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,220 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Context\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"[Context](https://getcontext.ai/) provides product analytics for AI chatbots.\n",
|
||||
"\n",
|
||||
"Context helps you understand how users are interacting with your AI chat products.\n",
|
||||
"Gain critical insights, optimise poor experiences, and minimise brand risks.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"In this guide we will show you how to integrate with Context."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"## Installation and Setup"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"vscode": {
|
||||
"languageId": "shellscript"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"$ pip install context-python --upgrade"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Getting API Credentials\n",
|
||||
"\n",
|
||||
"To get your Context API token:\n",
|
||||
"\n",
|
||||
"1. Go to the settings page within your Context account (https://go.getcontext.ai/settings).\n",
|
||||
"2. Generate a new API Token.\n",
|
||||
"3. Store this token somewhere secure."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Setup Context\n",
|
||||
"\n",
|
||||
"To use the `ContextCallbackHandler`, import the handler from Langchain and instantiate it with your Context API token.\n",
|
||||
"\n",
|
||||
"Ensure you have installed the `context-python` package before using the handler."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"from langchain.callbacks import ContextCallbackHandler\n",
|
||||
"\n",
|
||||
"token = os.environ[\"CONTEXT_API_TOKEN\"]\n",
|
||||
"\n",
|
||||
"context_callback = ContextCallbackHandler(token)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Usage\n",
|
||||
"### Using the Context callback within a Chat Model\n",
|
||||
"\n",
|
||||
"The Context callback handler can be used to directly record transcripts between users and AI assistants.\n",
|
||||
"\n",
|
||||
"#### Example"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.schema import (\n",
|
||||
" SystemMessage,\n",
|
||||
" HumanMessage,\n",
|
||||
")\n",
|
||||
"from langchain.callbacks import ContextCallbackHandler\n",
|
||||
"\n",
|
||||
"token = os.environ[\"CONTEXT_API_TOKEN\"]\n",
|
||||
"\n",
|
||||
"chat = ChatOpenAI(\n",
|
||||
" headers={\"user_id\": \"123\"}, temperature=0, callbacks=[ContextCallbackHandler(token)]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"messages = [\n",
|
||||
" SystemMessage(\n",
|
||||
" content=\"You are a helpful assistant that translates English to French.\"\n",
|
||||
" ),\n",
|
||||
" HumanMessage(content=\"I love programming.\"),\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"print(chat(messages))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Using the Context callback within Chains\n",
|
||||
"\n",
|
||||
"The Context callback handler can also be used to record the inputs and outputs of chains. Note that intermediate steps of the chain are not recorded - only the starting inputs and final outputs.\n",
|
||||
"\n",
|
||||
"__Note:__ Ensure that you pass the same context object to the chat model and the chain.\n",
|
||||
"\n",
|
||||
"Wrong:\n",
|
||||
"> ```python\n",
|
||||
"> chat = ChatOpenAI(temperature=0.9, callbacks=[ContextCallbackHandler(token)])\n",
|
||||
"> chain = LLMChain(llm=chat, prompt=chat_prompt_template, callbacks=[ContextCallbackHandler(token)])\n",
|
||||
"> ```\n",
|
||||
"\n",
|
||||
"Correct:\n",
|
||||
">```python\n",
|
||||
">handler = ContextCallbackHandler(token)\n",
|
||||
">chat = ChatOpenAI(temperature=0.9, callbacks=[callback])\n",
|
||||
">chain = LLMChain(llm=chat, prompt=chat_prompt_template, callbacks=[callback])\n",
|
||||
">```\n",
|
||||
"\n",
|
||||
"#### Example"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain import LLMChain\n",
|
||||
"from langchain.prompts import PromptTemplate\n",
|
||||
"from langchain.prompts.chat import (\n",
|
||||
" ChatPromptTemplate,\n",
|
||||
" HumanMessagePromptTemplate,\n",
|
||||
")\n",
|
||||
"from langchain.callbacks import ContextCallbackHandler\n",
|
||||
"\n",
|
||||
"token = os.environ[\"CONTEXT_API_TOKEN\"]\n",
|
||||
"\n",
|
||||
"human_message_prompt = HumanMessagePromptTemplate(\n",
|
||||
" prompt=PromptTemplate(\n",
|
||||
" template=\"What is a good name for a company that makes {product}?\",\n",
|
||||
" input_variables=[\"product\"],\n",
|
||||
" )\n",
|
||||
")\n",
|
||||
"chat_prompt_template = ChatPromptTemplate.from_messages([human_message_prompt])\n",
|
||||
"callback = ContextCallbackHandler(token)\n",
|
||||
"chat = ChatOpenAI(temperature=0.9, callbacks=[callback])\n",
|
||||
"chain = LLMChain(llm=chat, prompt=chat_prompt_template, callbacks=[callback])\n",
|
||||
"print(chain.run(\"colorful socks\"))"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.3"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "a53ebf4a859167383b364e7e7521d0add3c2dbbdecce4edf676e8c4634ff3fbb"
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,9 +0,0 @@
|
|||
---
|
||||
sidebar_position: 0
|
||||
---
|
||||
|
||||
# Callbacks
|
||||
|
||||
import DocCardList from "@theme/DocCardList";
|
||||
|
||||
<DocCardList />
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -1,210 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# PromptLayer\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"[PromptLayer](https://promptlayer.com) is a an LLM observability platform that lets you visualize requests, version prompts, and track usage. In this guide we will go over how to setup the `PromptLayerCallbackHandler`. \n",
|
||||
"\n",
|
||||
"While PromptLayer does have LLMs that integrate directly with LangChain (eg [`PromptLayerOpenAI`](https://python.langchain.com/docs/integrations/llms/promptlayer_openai)), this callback is the recommended way to integrate PromptLayer with LangChain.\n",
|
||||
"\n",
|
||||
"See [our docs](https://docs.promptlayer.com/languages/langchain) for more information."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"## Installation and Setup"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!pip install promptlayer --upgrade"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Getting API Credentials\n",
|
||||
"\n",
|
||||
"If you do not have a PromptLayer account, create one on [promptlayer.com](https://www.promptlayer.com). Then get an API key by clicking on the settings cog in the navbar and\n",
|
||||
"set it as an environment variabled called `PROMPTLAYER_API_KEY`\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Usage\n",
|
||||
"\n",
|
||||
"Getting started with `PromptLayerCallbackHandler` is fairly simple, it takes two optional arguments:\n",
|
||||
"1. `pl_tags` - an optional list of strings that will be tracked as tags on PromptLayer.\n",
|
||||
"2. `pl_id_callback` - an optional function that will take `promptlayer_request_id` as an argument. This ID can be used with all of PromptLayer's tracking features to track, metadata, scores, and prompt usage."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Simple OpenAI Example\n",
|
||||
"\n",
|
||||
"In this simple example we use `PromptLayerCallbackHandler` with `ChatOpenAI`. We add a PromptLayer tag named `chatopenai`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import promptlayer # Don't forget this 🍰\n",
|
||||
"from langchain.callbacks import PromptLayerCallbackHandler\n",
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.schema import (\n",
|
||||
" HumanMessage,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"chat_llm = ChatOpenAI(\n",
|
||||
" temperature=0,\n",
|
||||
" callbacks=[PromptLayerCallbackHandler(pl_tags=[\"chatopenai\"])],\n",
|
||||
")\n",
|
||||
"llm_results = chat_llm(\n",
|
||||
" [\n",
|
||||
" HumanMessage(content=\"What comes after 1,2,3 ?\"),\n",
|
||||
" HumanMessage(content=\"Tell me another joke?\"),\n",
|
||||
" ]\n",
|
||||
")\n",
|
||||
"print(llm_results)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### GPT4All Example"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import promptlayer # Don't forget this 🍰\n",
|
||||
"from langchain.callbacks import PromptLayerCallbackHandler\n",
|
||||
"\n",
|
||||
"from langchain.llms import GPT4All\n",
|
||||
"\n",
|
||||
"model = GPT4All(model=\"./models/gpt4all-model.bin\", n_ctx=512, n_threads=8)\n",
|
||||
"\n",
|
||||
"response = model(\n",
|
||||
" \"Once upon a time, \",\n",
|
||||
" callbacks=[PromptLayerCallbackHandler(pl_tags=[\"langchain\", \"gpt4all\"])],\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Full Featured Example\n",
|
||||
"\n",
|
||||
"In this example we unlock more of the power of PromptLayer.\n",
|
||||
"\n",
|
||||
"PromptLayer allows you to visually create, version, and track prompt templates. Using the [Prompt Registry](https://docs.promptlayer.com/features/prompt-registry), we can programatically fetch the prompt template called `example`.\n",
|
||||
"\n",
|
||||
"We also define a `pl_id_callback` function which takes in the `promptlayer_request_id` and logs a score, metadata and links the prompt template used. Read more about tracking on [our docs](https://docs.promptlayer.com/features/prompt-history/request-id)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import promptlayer # Don't forget this 🍰\n",
|
||||
"from langchain.callbacks import PromptLayerCallbackHandler\n",
|
||||
"from langchain.llms import OpenAI\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def pl_id_callback(promptlayer_request_id):\n",
|
||||
" print(\"prompt layer id \", promptlayer_request_id)\n",
|
||||
" promptlayer.track.score(\n",
|
||||
" request_id=promptlayer_request_id, score=100\n",
|
||||
" ) # score is an integer 0-100\n",
|
||||
" promptlayer.track.metadata(\n",
|
||||
" request_id=promptlayer_request_id, metadata={\"foo\": \"bar\"}\n",
|
||||
" ) # metadata is a dictionary of key value pairs that is tracked on PromptLayer\n",
|
||||
" promptlayer.track.prompt(\n",
|
||||
" request_id=promptlayer_request_id,\n",
|
||||
" prompt_name=\"example\",\n",
|
||||
" prompt_input_variables={\"product\": \"toasters\"},\n",
|
||||
" version=1,\n",
|
||||
" ) # link the request to a prompt template\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"openai_llm = OpenAI(\n",
|
||||
" model_name=\"text-davinci-002\",\n",
|
||||
" callbacks=[PromptLayerCallbackHandler(pl_id_callback=pl_id_callback)],\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"example_prompt = promptlayer.prompts.get(\"example\", version=1, langchain=True)\n",
|
||||
"openai_llm(example_prompt.format(product=\"toasters\"))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"That is all it takes! After setup all your requests will show up on the PromptLayer dashboard.\n",
|
||||
"This callback also works with any LLM implemented on LangChain."
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "base",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.8.8 (default, Apr 13 2021, 12:59:45) \n[Clang 10.0.0 ]"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "c4fe2cd85a8d9e8baaec5340ce66faff1c77581a9f43e6c45e85e09b6fced008"
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,73 +0,0 @@
|
|||
# Streamlit
|
||||
|
||||
> **[Streamlit](https://streamlit.io/) is a faster way to build and share data apps.**
|
||||
> Streamlit turns data scripts into shareable web apps in minutes. All in pure Python. No front‑end experience required.
|
||||
> See more examples at [streamlit.io/generative-ai](https://streamlit.io/generative-ai).
|
||||
|
||||
[](https://codespaces.new/langchain-ai/streamlit-agent?quickstart=1)
|
||||
|
||||
In this guide we will demonstrate how to use `StreamlitCallbackHandler` to display the thoughts and actions of an agent in an
|
||||
interactive Streamlit app. Try it out with the running app below using the [MRKL agent](/docs/modules/agents/how_to/mrkl/):
|
||||
|
||||
<iframe loading="lazy" src="https://langchain-mrkl.streamlit.app/?embed=true&embed_options=light_theme"
|
||||
style={{ width: 100 + '%', border: 'none', marginBottom: 1 + 'rem', height: 600 }}
|
||||
allow="camera;clipboard-read;clipboard-write;"
|
||||
></iframe>
|
||||
|
||||
## Installation and Setup
|
||||
|
||||
```bash
|
||||
pip install langchain streamlit
|
||||
```
|
||||
|
||||
You can run `streamlit hello` to load a sample app and validate your install succeeded. See full instructions in Streamlit's
|
||||
[Getting started documentation](https://docs.streamlit.io/library/get-started).
|
||||
|
||||
## Display thoughts and actions
|
||||
|
||||
To create a `StreamlitCallbackHandler`, you just need to provide a parent container to render the output.
|
||||
|
||||
```python
|
||||
from langchain.callbacks import StreamlitCallbackHandler
|
||||
import streamlit as st
|
||||
|
||||
st_callback = StreamlitCallbackHandler(st.container())
|
||||
```
|
||||
|
||||
Additional keyword arguments to customize the display behavior are described in the
|
||||
[API reference](https://api.python.langchain.com/en/latest/callbacks/langchain.callbacks.streamlit.streamlit_callback_handler.StreamlitCallbackHandler.html).
|
||||
|
||||
### Scenario 1: Using an Agent with Tools
|
||||
|
||||
The primary supported use case today is visualizing the actions of an Agent with Tools (or Agent Executor). You can create an
|
||||
agent in your Streamlit app and simply pass the `StreamlitCallbackHandler` to `agent.run()` in order to visualize the
|
||||
thoughts and actions live in your app.
|
||||
|
||||
```python
|
||||
from langchain.llms import OpenAI
|
||||
from langchain.agents import AgentType, initialize_agent, load_tools
|
||||
from langchain.callbacks import StreamlitCallbackHandler
|
||||
import streamlit as st
|
||||
|
||||
llm = OpenAI(temperature=0, streaming=True)
|
||||
tools = load_tools(["ddg-search"])
|
||||
agent = initialize_agent(
|
||||
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
|
||||
)
|
||||
|
||||
if prompt := st.chat_input():
|
||||
st.chat_message("user").write(prompt)
|
||||
with st.chat_message("assistant"):
|
||||
st_callback = StreamlitCallbackHandler(st.container())
|
||||
response = agent.run(prompt, callbacks=[st_callback])
|
||||
st.write(response)
|
||||
```
|
||||
|
||||
**Note:** You will need to set `OPENAI_API_KEY` for the above app code to run successfully.
|
||||
The easiest way to do this is via [Streamlit secrets.toml](https://docs.streamlit.io/library/advanced-features/secrets-management),
|
||||
or any other local ENV management tool.
|
||||
|
||||
### Additional scenarios
|
||||
|
||||
Currently `StreamlitCallbackHandler` is geared towards use with a LangChain Agent Executor. Support for additional agent types,
|
||||
use directly with Chains, etc will be added in the future.
|
||||
|
|
@ -1,181 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bf733a38-db84-4363-89e2-de6735c37230",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Anthropic\n",
|
||||
"\n",
|
||||
"This notebook covers how to get started with Anthropic chat models."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "d4a7c55d-b235-4ca4-a579-c90cc9570da9",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatAnthropic\n",
|
||||
"from langchain.prompts.chat import (\n",
|
||||
" ChatPromptTemplate,\n",
|
||||
" SystemMessagePromptTemplate,\n",
|
||||
" AIMessagePromptTemplate,\n",
|
||||
" HumanMessagePromptTemplate,\n",
|
||||
")\n",
|
||||
"from langchain.schema import AIMessage, HumanMessage, SystemMessage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "70cf04e8-423a-4ff6-8b09-f11fb711c817",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = ChatAnthropic()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "8199ef8f-eb8b-4253-9ea0-6c24a013ca4c",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=\" J'aime la programmation.\", additional_kwargs={}, example=False)"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"messages = [\n",
|
||||
" HumanMessage(\n",
|
||||
" content=\"Translate this sentence from English to French. I love programming.\"\n",
|
||||
" )\n",
|
||||
"]\n",
|
||||
"chat(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c361ab1e-8c0c-4206-9e3c-9d1424a12b9c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## `ChatAnthropic` also supports async and streaming functionality:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "93a21c5c-6ef9-4688-be60-b2e1f94842fb",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.callbacks.manager import CallbackManager\n",
|
||||
"from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "c5fac0e9-05a4-4fc1-a3b3-e5bbb24b971b",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"LLMResult(generations=[[ChatGeneration(text=\" J'aime programmer.\", generation_info=None, message=AIMessage(content=\" J'aime programmer.\", additional_kwargs={}, example=False))]], llm_output={}, run=[RunInfo(run_id=UUID('8cc8fb68-1c35-439c-96a0-695036a93652'))])"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"await chat.agenerate([messages])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "025be980-e50d-4a68-93dc-c9c7b500ce34",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
" J'aime la programmation."
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=\" J'aime la programmation.\", additional_kwargs={}, example=False)"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat = ChatAnthropic(\n",
|
||||
" streaming=True,\n",
|
||||
" verbose=True,\n",
|
||||
" callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),\n",
|
||||
")\n",
|
||||
"chat(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c253883f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,100 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "38f26d7a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Azure\n",
|
||||
"\n",
|
||||
"This notebook goes over how to connect to an Azure hosted OpenAI endpoint"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "96164b42",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import AzureChatOpenAI\n",
|
||||
"from langchain.schema import HumanMessage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "8161278f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"BASE_URL = \"https://${TODO}.openai.azure.com\"\n",
|
||||
"API_KEY = \"...\"\n",
|
||||
"DEPLOYMENT_NAME = \"chat\"\n",
|
||||
"model = AzureChatOpenAI(\n",
|
||||
" openai_api_base=BASE_URL,\n",
|
||||
" openai_api_version=\"2023-05-15\",\n",
|
||||
" deployment_name=DEPLOYMENT_NAME,\n",
|
||||
" openai_api_key=API_KEY,\n",
|
||||
" openai_api_type=\"azure\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "99509140",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=\"\\n\\nJ'aime programmer.\", additional_kwargs={})"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"model(\n",
|
||||
" [\n",
|
||||
" HumanMessage(\n",
|
||||
" content=\"Translate this sentence from English to French. I love programming.\"\n",
|
||||
" )\n",
|
||||
" ]\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "3b6e9376",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,247 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Google Cloud Platform Vertex AI PaLM \n",
|
||||
"\n",
|
||||
"Note: This is seperate from the Google PaLM integration. Google has chosen to offer an enterprise version of PaLM through GCP, and this supports the models made available through there. \n",
|
||||
"\n",
|
||||
"PaLM API on Vertex AI is a Preview offering, subject to the Pre-GA Offerings Terms of the [GCP Service Specific Terms](https://cloud.google.com/terms/service-terms). \n",
|
||||
"\n",
|
||||
"Pre-GA products and features may have limited support, and changes to pre-GA products and features may not be compatible with other pre-GA versions. For more information, see the [launch stage descriptions](https://cloud.google.com/products#product-launch-stages). Further, by using PaLM API on Vertex AI, you agree to the Generative AI Preview [terms and conditions](https://cloud.google.com/trustedtester/aitos) (Preview Terms).\n",
|
||||
"\n",
|
||||
"For PaLM API on Vertex AI, you can process personal data as outlined in the Cloud Data Processing Addendum, subject to applicable restrictions and obligations in the Agreement (as defined in the Preview Terms).\n",
|
||||
"\n",
|
||||
"To use Vertex AI PaLM you must have the `google-cloud-aiplatform` Python package installed and either:\n",
|
||||
"- Have credentials configured for your environment (gcloud, workload identity, etc...)\n",
|
||||
"- Store the path to a service account JSON file as the GOOGLE_APPLICATION_CREDENTIALS environment variable\n",
|
||||
"\n",
|
||||
"This codebase uses the `google.auth` library which first looks for the application credentials variable mentioned above, and then looks for system-level auth.\n",
|
||||
"\n",
|
||||
"For more information, see: \n",
|
||||
"- https://cloud.google.com/docs/authentication/application-default-credentials#GAC\n",
|
||||
"- https://googleapis.dev/python/google-auth/latest/reference/google.auth.html#module-google.auth\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install google-cloud-aiplatform"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatVertexAI\n",
|
||||
"from langchain.prompts.chat import (\n",
|
||||
" ChatPromptTemplate,\n",
|
||||
" SystemMessagePromptTemplate,\n",
|
||||
" HumanMessagePromptTemplate,\n",
|
||||
")\n",
|
||||
"from langchain.schema import HumanMessage, SystemMessage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = ChatVertexAI()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='Sure, here is the translation of the sentence \"I love programming\" from English to French:\\n\\nJ\\'aime programmer.', additional_kwargs={}, example=False)"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"messages = [\n",
|
||||
" SystemMessage(\n",
|
||||
" content=\"You are a helpful assistant that translates English to French.\"\n",
|
||||
" ),\n",
|
||||
" HumanMessage(\n",
|
||||
" content=\"Translate this sentence from English to French. I love programming.\"\n",
|
||||
" ),\n",
|
||||
"]\n",
|
||||
"chat(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"You can make use of templating by using a `MessagePromptTemplate`. You can build a `ChatPromptTemplate` from one or more `MessagePromptTemplates`. You can use `ChatPromptTemplate`'s `format_prompt` -- this returns a `PromptValue`, which you can convert to a string or Message object, depending on whether you want to use the formatted value as input to an llm or chat model.\n",
|
||||
"\n",
|
||||
"For convenience, there is a `from_template` method exposed on the template. If you were to use this template, this is what it would look like:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"template = (\n",
|
||||
" \"You are a helpful assistant that translates {input_language} to {output_language}.\"\n",
|
||||
")\n",
|
||||
"system_message_prompt = SystemMessagePromptTemplate.from_template(template)\n",
|
||||
"human_template = \"{text}\"\n",
|
||||
"human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='Sure, here is the translation of \"I love programming\" in French:\\n\\nJ\\'aime programmer.', additional_kwargs={}, example=False)"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat_prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [system_message_prompt, human_message_prompt]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# get a chat completion from the formatted messages\n",
|
||||
"chat(\n",
|
||||
" chat_prompt.format_prompt(\n",
|
||||
" input_language=\"English\", output_language=\"French\", text=\"I love programming.\"\n",
|
||||
" ).to_messages()\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"execution": {
|
||||
"iopub.execute_input": "2023-06-17T21:09:25.423568Z",
|
||||
"iopub.status.busy": "2023-06-17T21:09:25.423213Z",
|
||||
"iopub.status.idle": "2023-06-17T21:09:25.429641Z",
|
||||
"shell.execute_reply": "2023-06-17T21:09:25.429060Z",
|
||||
"shell.execute_reply.started": "2023-06-17T21:09:25.423546Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"You can now leverage the Codey API for code chat within Vertex AI. The model name is:\n",
|
||||
"- codechat-bison: for code assistance"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"execution": {
|
||||
"iopub.execute_input": "2023-06-17T21:30:43.974841Z",
|
||||
"iopub.status.busy": "2023-06-17T21:30:43.974431Z",
|
||||
"iopub.status.idle": "2023-06-17T21:30:44.248119Z",
|
||||
"shell.execute_reply": "2023-06-17T21:30:44.247362Z",
|
||||
"shell.execute_reply.started": "2023-06-17T21:30:43.974820Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = ChatVertexAI(model_name=\"codechat-bison\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"execution": {
|
||||
"iopub.execute_input": "2023-06-17T21:30:45.146093Z",
|
||||
"iopub.status.busy": "2023-06-17T21:30:45.145752Z",
|
||||
"iopub.status.idle": "2023-06-17T21:30:47.449126Z",
|
||||
"shell.execute_reply": "2023-06-17T21:30:47.448609Z",
|
||||
"shell.execute_reply.started": "2023-06-17T21:30:45.146069Z"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='The following Python function can be used to identify all prime numbers up to a given integer:\\n\\n```\\ndef is_prime(n):\\n \"\"\"\\n Determines whether the given integer is prime.\\n\\n Args:\\n n: The integer to be tested for primality.\\n\\n Returns:\\n True if n is prime, False otherwise.\\n \"\"\"\\n\\n # Check if n is divisible by 2.\\n if n % 2 == 0:\\n return False\\n\\n # Check if n is divisible by any integer from 3 to the square root', additional_kwargs={}, example=False)"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"messages = [\n",
|
||||
" HumanMessage(\n",
|
||||
" content=\"How do I create a python function to identify all prime numbers?\"\n",
|
||||
" )\n",
|
||||
"]\n",
|
||||
"chat(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "cc99336516f23363341912c6723b01ace86f02e26b4290be1efc0677e2e2ec24"
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,9 +0,0 @@
|
|||
---
|
||||
sidebar_position: 0
|
||||
---
|
||||
|
||||
# Chat models
|
||||
|
||||
import DocCardList from "@theme/DocCardList";
|
||||
|
||||
<DocCardList />
|
||||
|
|
@ -1,162 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e49f1e0d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# JinaChat\n",
|
||||
"\n",
|
||||
"This notebook covers how to get started with JinaChat chat models."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "522686de",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import JinaChat\n",
|
||||
"from langchain.prompts.chat import (\n",
|
||||
" ChatPromptTemplate,\n",
|
||||
" SystemMessagePromptTemplate,\n",
|
||||
" AIMessagePromptTemplate,\n",
|
||||
" HumanMessagePromptTemplate,\n",
|
||||
")\n",
|
||||
"from langchain.schema import AIMessage, HumanMessage, SystemMessage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "62e0dbc3",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = JinaChat(temperature=0)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "ce16ad78-8e6f-48cd-954e-98be75eb5836",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=\"J'aime programmer.\", additional_kwargs={}, example=False)"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"messages = [\n",
|
||||
" SystemMessage(\n",
|
||||
" content=\"You are a helpful assistant that translates English to French.\"\n",
|
||||
" ),\n",
|
||||
" HumanMessage(\n",
|
||||
" content=\"Translate this sentence from English to French. I love programming.\"\n",
|
||||
" ),\n",
|
||||
"]\n",
|
||||
"chat(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "778f912a-66ea-4a5d-b3de-6c7db4baba26",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"You can make use of templating by using a `MessagePromptTemplate`. You can build a `ChatPromptTemplate` from one or more `MessagePromptTemplates`. You can use `ChatPromptTemplate`'s `format_prompt` -- this returns a `PromptValue`, which you can convert to a string or Message object, depending on whether you want to use the formatted value as input to an llm or chat model.\n",
|
||||
"\n",
|
||||
"For convenience, there is a `from_template` method exposed on the template. If you were to use this template, this is what it would look like:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "180c5cc8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"template = (\n",
|
||||
" \"You are a helpful assistant that translates {input_language} to {output_language}.\"\n",
|
||||
")\n",
|
||||
"system_message_prompt = SystemMessagePromptTemplate.from_template(template)\n",
|
||||
"human_template = \"{text}\"\n",
|
||||
"human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "fbb043e6",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=\"J'aime programmer.\", additional_kwargs={}, example=False)"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat_prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [system_message_prompt, human_message_prompt]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# get a chat completion from the formatted messages\n",
|
||||
"chat(\n",
|
||||
" chat_prompt.format_prompt(\n",
|
||||
" input_language=\"English\", output_language=\"French\", text=\"I love programming.\"\n",
|
||||
" ).to_messages()\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c095285d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,134 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "90a1faf2",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Llama API\n",
|
||||
"\n",
|
||||
"This notebook shows how to use LangChain with [LlamaAPI](https://llama-api.com/) - a hosted version of Llama2 that adds in support for function calling."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f5b652cf",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"!pip install -U llamaapi"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "bfd385fd",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from llamaapi import LlamaAPI\n",
|
||||
"\n",
|
||||
"# Replace 'Your_API_Token' with your actual API token\n",
|
||||
"llama = LlamaAPI('Your_API_Token')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "632eb3e5",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"/Users/harrisonchase/.pyenv/versions/3.9.1/envs/langchain/lib/python3.9/site-packages/deeplake/util/check_latest_version.py:32: UserWarning: A newer version of deeplake (3.6.12) is available. It's recommended that you update to the latest version using `pip install -U deeplake`.\n",
|
||||
" warnings.warn(\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain_experimental.llms import ChatLlamaAPI"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "6f850e82",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"model = ChatLlamaAPI(client=llama)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "975c2bf4",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chains import create_tagging_chain\n",
|
||||
"\n",
|
||||
"schema = {\n",
|
||||
" \"properties\": {\n",
|
||||
" \"sentiment\": {\"type\": \"string\", 'description': 'the sentiment encountered in the passage'},\n",
|
||||
" \"aggressiveness\": {\"type\": \"integer\", 'description': 'a 0-10 score of how aggressive the passage is'},\n",
|
||||
" \"language\": {\"type\": \"string\", 'description': 'the language of the passage'},\n",
|
||||
" }\n",
|
||||
"}\n",
|
||||
"\n",
|
||||
"chain = create_tagging_chain(schema, model)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "ef9638c3",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'sentiment': 'aggressive', 'aggressiveness': 8}"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chain.run(\"give me your money\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "238b4f62",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,175 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e49f1e0d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# OpenAI\n",
|
||||
"\n",
|
||||
"This notebook covers how to get started with OpenAI chat models."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "522686de",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.chat_models import ChatOpenAI\n",
|
||||
"from langchain.prompts.chat import (\n",
|
||||
" ChatPromptTemplate,\n",
|
||||
" SystemMessagePromptTemplate,\n",
|
||||
" AIMessagePromptTemplate,\n",
|
||||
" HumanMessagePromptTemplate,\n",
|
||||
")\n",
|
||||
"from langchain.schema import AIMessage, HumanMessage, SystemMessage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "62e0dbc3",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = ChatOpenAI(temperature=0)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "4e5fe97e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The above cell assumes that your OpenAI API key is set in your environment variables. If you would rather manually specify your API key and/or organization ID, use the following code:\n",
|
||||
"\n",
|
||||
"```python\n",
|
||||
"chat = ChatOpenAI(temperature=0, openai_api_key=\"YOUR_API_KEY\", openai_organization=\"YOUR_ORGANIZATION_ID\")\n",
|
||||
"```\n",
|
||||
"Remove the openai_organization parameter should it not apply to you."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "ce16ad78-8e6f-48cd-954e-98be75eb5836",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=\"J'adore la programmation.\", additional_kwargs={}, example=False)"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"messages = [\n",
|
||||
" SystemMessage(\n",
|
||||
" content=\"You are a helpful assistant that translates English to French.\"\n",
|
||||
" ),\n",
|
||||
" HumanMessage(\n",
|
||||
" content=\"Translate this sentence from English to French. I love programming.\"\n",
|
||||
" ),\n",
|
||||
"]\n",
|
||||
"chat(messages)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "778f912a-66ea-4a5d-b3de-6c7db4baba26",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"You can make use of templating by using a `MessagePromptTemplate`. You can build a `ChatPromptTemplate` from one or more `MessagePromptTemplates`. You can use `ChatPromptTemplate`'s `format_prompt` -- this returns a `PromptValue`, which you can convert to a string or Message object, depending on whether you want to use the formatted value as input to an llm or chat model.\n",
|
||||
"\n",
|
||||
"For convenience, there is a `from_template` method exposed on the template. If you were to use this template, this is what it would look like:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "180c5cc8",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"template = (\n",
|
||||
" \"You are a helpful assistant that translates {input_language} to {output_language}.\"\n",
|
||||
")\n",
|
||||
"system_message_prompt = SystemMessagePromptTemplate.from_template(template)\n",
|
||||
"human_template = \"{text}\"\n",
|
||||
"human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "fbb043e6",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content=\"J'adore la programmation.\", additional_kwargs={}, example=False)"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat_prompt = ChatPromptTemplate.from_messages(\n",
|
||||
" [system_message_prompt, human_message_prompt]\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# get a chat completion from the formatted messages\n",
|
||||
"chat(\n",
|
||||
" chat_prompt.format_prompt(\n",
|
||||
" input_language=\"English\", output_language=\"French\", text=\"I love programming.\"\n",
|
||||
" ).to_messages()\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c095285d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.7"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,188 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "959300d4",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# PromptLayer ChatOpenAI\n",
|
||||
"\n",
|
||||
"This example showcases how to connect to [PromptLayer](https://www.promptlayer.com) to start recording your ChatOpenAI requests."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "6a45943e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Install PromptLayer\n",
|
||||
"The `promptlayer` package is required to use PromptLayer with OpenAI. Install `promptlayer` using pip."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "dbe09bd8",
|
||||
"metadata": {
|
||||
"vscode": {
|
||||
"languageId": "powershell"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"pip install promptlayer"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "536c1dfa",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Imports"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "c16da3b5",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"from langchain.chat_models import PromptLayerChatOpenAI\n",
|
||||
"from langchain.schema import HumanMessage"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "8564ce7d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Set the Environment API Key\n",
|
||||
"You can create a PromptLayer API Key at [www.promptlayer.com](https://www.promptlayer.com) by clicking the settings cog in the navbar.\n",
|
||||
"\n",
|
||||
"Set it as an environment variable called `PROMPTLAYER_API_KEY`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "46ba25dc",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"os.environ[\"PROMPTLAYER_API_KEY\"] = \"**********\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "bf0294de",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Use the PromptLayerOpenAI LLM like normal\n",
|
||||
"*You can optionally pass in `pl_tags` to track your requests with PromptLayer's tagging feature.*"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "3acf0069",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"AIMessage(content='to take a nap in a cozy spot. I search around for a suitable place and finally settle on a soft cushion on the window sill. I curl up into a ball and close my eyes, relishing the warmth of the sun on my fur. As I drift off to sleep, I can hear the birds chirping outside and feel the gentle breeze blowing through the window. This is the life of a contented cat.', additional_kwargs={})"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chat = PromptLayerChatOpenAI(pl_tags=[\"langchain\"])\n",
|
||||
"chat([HumanMessage(content=\"I am a cat and I want\")])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "a2d76826",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"**The above request should now appear on your [PromptLayer dashboard](https://www.promptlayer.com).**"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "05e9e2fe",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"id": "c43803d1",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Using PromptLayer Track\n",
|
||||
"If you would like to use any of the [PromptLayer tracking features](https://magniv.notion.site/Track-4deee1b1f7a34c1680d085f82567dab9), you need to pass the argument `return_pl_id` when instantializing the PromptLayer LLM to get the request id. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "b7d4db01",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"chat = PromptLayerChatOpenAI(return_pl_id=True)\n",
|
||||
"chat_results = chat.generate([[HumanMessage(content=\"I am a cat and I want\")]])\n",
|
||||
"\n",
|
||||
"for res in chat_results.generations:\n",
|
||||
" pl_request_id = res[0].generation_info[\"pl_request_id\"]\n",
|
||||
" promptlayer.track.score(request_id=pl_request_id, score=100)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "13e56507",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Using this allows you to track the performance of your model in the PromptLayer dashboard. If you are using a prompt template, you can attach a template to a request as well.\n",
|
||||
"Overall, this gives you the opportunity to track the performance of different templates and models in the PromptLayer dashboard."
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "base",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.8.8 (default, Apr 13 2021, 12:59:45) \n[Clang 10.0.0 ]"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "8a5edab282632443219e051e4ade2d1d5bbc671c781051bf1437897cbdfea0f1"
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,220 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1ab83660",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Etherscan Loader\n",
|
||||
"## Overview\n",
|
||||
"\n",
|
||||
"The Etherscan loader use etherscan api to load transacactions histories under specific account on Ethereum Mainnet.\n",
|
||||
"\n",
|
||||
"You will need a Etherscan api key to proceed. The free api key has 5 calls per seconds quota.\n",
|
||||
"\n",
|
||||
"The loader supports the following six functinalities:\n",
|
||||
"* Retrieve normal transactions under specific account on Ethereum Mainet\n",
|
||||
"* Retrieve internal transactions under specific account on Ethereum Mainet\n",
|
||||
"* Retrieve erc20 transactions under specific account on Ethereum Mainet\n",
|
||||
"* Retrieve erc721 transactions under specific account on Ethereum Mainet\n",
|
||||
"* Retrieve erc1155 transactions under specific account on Ethereum Mainet\n",
|
||||
"* Retrieve ethereum balance in wei under specific account on Ethereum Mainet\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"If the account does not have corresponding transactions, the loader will a list with one document. The content of document is ''.\n",
|
||||
"\n",
|
||||
"You can pass differnt filters to loader to access different functionalities we mentioned above:\n",
|
||||
"* \"normal_transaction\"\n",
|
||||
"* \"internal_transaction\"\n",
|
||||
"* \"erc20_transaction\"\n",
|
||||
"* \"eth_balance\"\n",
|
||||
"* \"erc721_transaction\"\n",
|
||||
"* \"erc1155_transaction\"\n",
|
||||
"The filter is default to normal_transaction\n",
|
||||
"\n",
|
||||
"If you have any questions, you can access [Etherscan API Doc](https://etherscan.io/tx/0x0ffa32c787b1398f44303f731cb06678e086e4f82ce07cebf75e99bb7c079c77) or contact me via i@inevitable.tech.\n",
|
||||
"\n",
|
||||
"All functions related to transactions histories are restricted 1000 histories maximum because of Etherscan limit. You can use the following parameters to find the transaction histories you need:\n",
|
||||
"* offset: default to 20. Shows 20 transactions for one time\n",
|
||||
"* page: default to 1. This controls pagenation.\n",
|
||||
"* start_block: Default to 0. The transaction histories starts from 0 block.\n",
|
||||
"* end_block: Default to 99999999. The transaction histories starts from 99999999 block\n",
|
||||
"* sort: \"desc\" or \"asc\". Set default to \"desc\" to get latest transactions."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d72d4e22",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Setup"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "2911e51e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%pip install langchain -q"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "208e2fbf",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import EtherscanLoader\n",
|
||||
"import os"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "5d24b650",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"os.environ[\"ETHERSCAN_API_KEY\"] = etherscanAPIKey"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "3bcbb63e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Create a ERC20 transaction loader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "d525e6c8",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'blockNumber': '13242975',\n",
|
||||
" 'timeStamp': '1631878751',\n",
|
||||
" 'hash': '0x366dda325b1a6570928873665b6b418874a7dedf7fee9426158fa3536b621788',\n",
|
||||
" 'nonce': '28',\n",
|
||||
" 'blockHash': '0x5469dba1b1e1372962cf2be27ab2640701f88c00640c4d26b8cc2ae9ac256fb6',\n",
|
||||
" 'from': '0x2ceee24f8d03fc25648c68c8e6569aa0512f6ac3',\n",
|
||||
" 'contractAddress': '0x2ceee24f8d03fc25648c68c8e6569aa0512f6ac3',\n",
|
||||
" 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b',\n",
|
||||
" 'value': '298131000000000',\n",
|
||||
" 'tokenName': 'ABCHANGE.io',\n",
|
||||
" 'tokenSymbol': 'XCH',\n",
|
||||
" 'tokenDecimal': '9',\n",
|
||||
" 'transactionIndex': '71',\n",
|
||||
" 'gas': '15000000',\n",
|
||||
" 'gasPrice': '48614996176',\n",
|
||||
" 'gasUsed': '5712724',\n",
|
||||
" 'cumulativeGasUsed': '11507920',\n",
|
||||
" 'input': 'deprecated',\n",
|
||||
" 'confirmations': '4492277'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"account_address = \"0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b\"\n",
|
||||
"loader = EtherscanLoader(account_address, filter=\"erc20_transaction\")\n",
|
||||
"result = loader.load()\n",
|
||||
"eval(result[0].page_content)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2a1ecce0",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Create a normal transaction loader with customized parameters"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "07aa2b6c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"20\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content=\"{'blockNumber': '1723771', 'timeStamp': '1466213371', 'hash': '0xe00abf5fa83a4b23ee1cc7f07f9dda04ab5fa5efe358b315df8b76699a83efc4', 'nonce': '3155', 'blockHash': '0xc2c2207bcaf341eed07f984c9a90b3f8e8bdbdbd2ac6562f8c2f5bfa4b51299d', 'transactionIndex': '5', 'from': '0x3763e6e1228bfeab94191c856412d1bb0a8e6996', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '13149213761000000000', 'gas': '90000', 'gasPrice': '22655598156', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '126000', 'gasUsed': '21000', 'confirmations': '16011481', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x3763e6e1228bfeab94191c856412d1bb0a8e6996', 'tx_hash': '0xe00abf5fa83a4b23ee1cc7f07f9dda04ab5fa5efe358b315df8b76699a83efc4', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1727090', 'timeStamp': '1466262018', 'hash': '0xd5a779346d499aa722f72ffe7cd3c8594a9ddd91eb7e439e8ba92ceb7bc86928', 'nonce': '3267', 'blockHash': '0xc0cff378c3446b9b22d217c2c5f54b1c85b89a632c69c55b76cdffe88d2b9f4d', 'transactionIndex': '20', 'from': '0x3763e6e1228bfeab94191c856412d1bb0a8e6996', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '11521979886000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '3806725', 'gasUsed': '21000', 'confirmations': '16008162', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x3763e6e1228bfeab94191c856412d1bb0a8e6996', 'tx_hash': '0xd5a779346d499aa722f72ffe7cd3c8594a9ddd91eb7e439e8ba92ceb7bc86928', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1730337', 'timeStamp': '1466308222', 'hash': '0xceaffdb3766d2741057d402738eb41e1d1941939d9d438c102fb981fd47a87a4', 'nonce': '3344', 'blockHash': '0x3a52d28b8587d55c621144a161a0ad5c37dd9f7d63b629ab31da04fa410b2cfa', 'transactionIndex': '1', 'from': '0x3763e6e1228bfeab94191c856412d1bb0a8e6996', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '9783400526000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '60788', 'gasUsed': '21000', 'confirmations': '16004915', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x3763e6e1228bfeab94191c856412d1bb0a8e6996', 'tx_hash': '0xceaffdb3766d2741057d402738eb41e1d1941939d9d438c102fb981fd47a87a4', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1733479', 'timeStamp': '1466352351', 'hash': '0x720d79bf78775f82b40280aae5abfc347643c5f6708d4bf4ec24d65cd01c7121', 'nonce': '3367', 'blockHash': '0x9928661e7ae125b3ae0bcf5e076555a3ee44c52ae31bd6864c9c93a6ebb3f43e', 'transactionIndex': '0', 'from': '0x3763e6e1228bfeab94191c856412d1bb0a8e6996', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '1570706444000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '21000', 'gasUsed': '21000', 'confirmations': '16001773', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x3763e6e1228bfeab94191c856412d1bb0a8e6996', 'tx_hash': '0x720d79bf78775f82b40280aae5abfc347643c5f6708d4bf4ec24d65cd01c7121', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1734172', 'timeStamp': '1466362463', 'hash': '0x7a062d25b83bafc9fe6b22bc6f5718bca333908b148676e1ac66c0adeccef647', 'nonce': '1016', 'blockHash': '0x8a8afe2b446713db88218553cfb5dd202422928e5e0bc00475ed2f37d95649de', 'transactionIndex': '4', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '6322276709000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '105333', 'gasUsed': '21000', 'confirmations': '16001080', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0x7a062d25b83bafc9fe6b22bc6f5718bca333908b148676e1ac66c0adeccef647', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1737276', 'timeStamp': '1466406037', 'hash': '0xa4e89bfaf075abbf48f96700979e6c7e11a776b9040113ba64ef9c29ac62b19b', 'nonce': '1024', 'blockHash': '0xe117cad73752bb485c3bef24556e45b7766b283229180fcabc9711f3524b9f79', 'transactionIndex': '35', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '9976891868000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '3187163', 'gasUsed': '21000', 'confirmations': '15997976', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0xa4e89bfaf075abbf48f96700979e6c7e11a776b9040113ba64ef9c29ac62b19b', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1740314', 'timeStamp': '1466450262', 'hash': '0x6e1a22dcc6e2c77a9451426fb49e765c3c459dae88350e3ca504f4831ec20e8a', 'nonce': '1051', 'blockHash': '0x588d17842819a81afae3ac6644d8005c12ce55ddb66c8d4c202caa91d4e8fdbe', 'transactionIndex': '6', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '8060633765000000000', 'gas': '90000', 'gasPrice': '22926905859', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '153077', 'gasUsed': '21000', 'confirmations': '15994938', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0x6e1a22dcc6e2c77a9451426fb49e765c3c459dae88350e3ca504f4831ec20e8a', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1743384', 'timeStamp': '1466494099', 'hash': '0xdbfcc15f02269fc3ae27f69e344a1ac4e08948b12b76ebdd78a64d8cafd511ef', 'nonce': '1068', 'blockHash': '0x997245108c84250057fda27306b53f9438ad40978a95ca51d8fd7477e73fbaa7', 'transactionIndex': '2', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '9541921352000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '119650', 'gasUsed': '21000', 'confirmations': '15991868', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0xdbfcc15f02269fc3ae27f69e344a1ac4e08948b12b76ebdd78a64d8cafd511ef', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1746405', 'timeStamp': '1466538123', 'hash': '0xbd4f9602f7fff4b8cc2ab6286efdb85f97fa114a43f6df4e6abc88e85b89e97b', 'nonce': '1092', 'blockHash': '0x3af3966cdaf22e8b112792ee2e0edd21ceb5a0e7bf9d8c168a40cf22deb3690c', 'transactionIndex': '0', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '8433783799000000000', 'gas': '90000', 'gasPrice': '25689279306', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '21000', 'gasUsed': '21000', 'confirmations': '15988847', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0xbd4f9602f7fff4b8cc2ab6286efdb85f97fa114a43f6df4e6abc88e85b89e97b', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1749459', 'timeStamp': '1466582044', 'hash': '0x28c327f462cc5013d81c8682c032f014083c6891938a7bdeee85a1c02c3e9ed4', 'nonce': '1096', 'blockHash': '0x5fc5d2a903977b35ce1239975ae23f9157d45d7bd8a8f6205e8ce270000797f9', 'transactionIndex': '1', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '10269065805000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '42000', 'gasUsed': '21000', 'confirmations': '15985793', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0x28c327f462cc5013d81c8682c032f014083c6891938a7bdeee85a1c02c3e9ed4', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1752614', 'timeStamp': '1466626168', 'hash': '0xc3849e550ca5276d7b3c51fa95ad3ae62c1c164799d33f4388fe60c4e1d4f7d8', 'nonce': '1118', 'blockHash': '0x88ef054b98e47504332609394e15c0a4467f84042396717af6483f0bcd916127', 'transactionIndex': '11', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '11325836780000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '252000', 'gasUsed': '21000', 'confirmations': '15982638', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0xc3849e550ca5276d7b3c51fa95ad3ae62c1c164799d33f4388fe60c4e1d4f7d8', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1755659', 'timeStamp': '1466669931', 'hash': '0xb9f891b7c3d00fcd64483189890591d2b7b910eda6172e3bf3973c5fd3d5a5ae', 'nonce': '1133', 'blockHash': '0x2983972217a91343860415d1744c2a55246a297c4810908bbd3184785bc9b0c2', 'transactionIndex': '14', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '13226475343000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '2674679', 'gasUsed': '21000', 'confirmations': '15979593', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0xb9f891b7c3d00fcd64483189890591d2b7b910eda6172e3bf3973c5fd3d5a5ae', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1758709', 'timeStamp': '1466713652', 'hash': '0xd6cce5b184dc7fce85f305ee832df647a9c4640b68e9b79b6f74dc38336d5622', 'nonce': '1147', 'blockHash': '0x1660de1e73067251be0109d267a21ffc7d5bde21719a3664c7045c32e771ecf9', 'transactionIndex': '1', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '9758447294000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '42000', 'gasUsed': '21000', 'confirmations': '15976543', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0xd6cce5b184dc7fce85f305ee832df647a9c4640b68e9b79b6f74dc38336d5622', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1761783', 'timeStamp': '1466757809', 'hash': '0xd01545872629956867cbd65fdf5e97d0dde1a112c12e76a1bfc92048d37f650f', 'nonce': '1169', 'blockHash': '0x7576961afa4218a3264addd37a41f55c444dd534e9410dbd6f93f7fe20e0363e', 'transactionIndex': '2', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '10197126683000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '63000', 'gasUsed': '21000', 'confirmations': '15973469', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0xd01545872629956867cbd65fdf5e97d0dde1a112c12e76a1bfc92048d37f650f', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1764895', 'timeStamp': '1466801683', 'hash': '0x620b91b12af7aac75553b47f15742e2825ea38919cfc8082c0666f404a0db28b', 'nonce': '1186', 'blockHash': '0x2e687643becd3c36e0c396a02af0842775e17ccefa0904de5aeca0a9a1aa795e', 'transactionIndex': '7', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '8690241462000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '168000', 'gasUsed': '21000', 'confirmations': '15970357', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0x620b91b12af7aac75553b47f15742e2825ea38919cfc8082c0666f404a0db28b', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1767936', 'timeStamp': '1466845682', 'hash': '0x758efa27576cd17ebe7b842db4892eac6609e3962a4f9f57b7c84b7b1909512f', 'nonce': '1211', 'blockHash': '0xb01d8fd47b3554a99352ac3e5baf5524f314cfbc4262afcfbea1467b2d682898', 'transactionIndex': '0', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '11914401843000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '21000', 'gasUsed': '21000', 'confirmations': '15967316', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0x758efa27576cd17ebe7b842db4892eac6609e3962a4f9f57b7c84b7b1909512f', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1770911', 'timeStamp': '1466888890', 'hash': '0x9d84470b54ab44b9074b108a0e506cd8badf30457d221e595bb68d63e926b865', 'nonce': '1212', 'blockHash': '0x79a9de39276132dab8bf00dc3e060f0e8a14f5e16a0ee4e9cc491da31b25fe58', 'transactionIndex': '0', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '10918214730000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '21000', 'gasUsed': '21000', 'confirmations': '15964341', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0x9d84470b54ab44b9074b108a0e506cd8badf30457d221e595bb68d63e926b865', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1774044', 'timeStamp': '1466932983', 'hash': '0x958d85270b58b80f1ad228f716bbac8dd9da7c5f239e9f30d8edeb5bb9301d20', 'nonce': '1240', 'blockHash': '0x69cee390378c3b886f9543fb3a1cb2fc97621ec155f7884564d4c866348ce539', 'transactionIndex': '2', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '9979637283000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '63000', 'gasUsed': '21000', 'confirmations': '15961208', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0x958d85270b58b80f1ad228f716bbac8dd9da7c5f239e9f30d8edeb5bb9301d20', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1777057', 'timeStamp': '1466976422', 'hash': '0xe76ca3603d2f4e7134bdd7a1c3fd553025fc0b793f3fd2a75cd206b8049e74ab', 'nonce': '1248', 'blockHash': '0xc7cacda0ac38c99f1b9bccbeee1562a41781d2cfaa357e8c7b4af6a49584b968', 'transactionIndex': '7', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '4556173496000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '168000', 'gasUsed': '21000', 'confirmations': '15958195', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0xe76ca3603d2f4e7134bdd7a1c3fd553025fc0b793f3fd2a75cd206b8049e74ab', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'}),\n",
|
||||
" Document(page_content=\"{'blockNumber': '1780120', 'timeStamp': '1467020353', 'hash': '0xc5ec8cecdc9f5ed55a5b8b0ad79c964fb5c49dc1136b6a49e981616c3e70bbe6', 'nonce': '1266', 'blockHash': '0xfc0e066e5b613239e1a01e6d582e7ab162ceb3ca4f719dfbd1a0c965adcfe1c5', 'transactionIndex': '1', 'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b', 'value': '11890330240000000000', 'gas': '90000', 'gasPrice': '20000000000', 'isError': '0', 'txreceipt_status': '', 'input': '0x', 'contractAddress': '', 'cumulativeGasUsed': '42000', 'gasUsed': '21000', 'confirmations': '15955132', 'methodId': '0x', 'functionName': ''}\", metadata={'from': '0x16545fb79dbee1ad3a7f868b7661c023f372d5de', 'tx_hash': '0xc5ec8cecdc9f5ed55a5b8b0ad79c964fb5c49dc1136b6a49e981616c3e70bbe6', 'to': '0x9dd134d14d1e65f84b706d6f205cd5b1cd03a46b'})]"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"loader = EtherscanLoader(\n",
|
||||
" account_address,\n",
|
||||
" page=2,\n",
|
||||
" offset=20,\n",
|
||||
" start_block=10000,\n",
|
||||
" end_block=8888888888,\n",
|
||||
" sort=\"asc\",\n",
|
||||
")\n",
|
||||
"result = loader.load()\n",
|
||||
"result"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,75 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e310c8dc-acd0-48d2-801c-f37ce99acd2d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# acreom"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "04a2c95d-4114-431e-904a-32d79005c28b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"[acreom](https://acreom.com) is a dev-first knowledge base with tasks running on local markdown files.\n",
|
||||
"\n",
|
||||
"Below is an example on how to load a local acreom vault into Langchain. As the local vault in acreom is a folder of plain text .md files, the loader requires the path to the directory. \n",
|
||||
"\n",
|
||||
"Vault files may contain some metadata which is stored as a YAML header. These values will be added to the document’s metadata if `collect_metadata` is set to true. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "0169bee5-aa7a-4ec7-b7e7-b3bb2e58f3bb",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import AcreomLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c1b49ab3-616b-4149-bef5-7559d65d3d2b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = AcreomLoader(\"<path-to-acreom-vault>\", collect_metadata=False)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "3127a018-9c1c-4886-8321-f5666d970a95",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"docs = loader.load()"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.10"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,186 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1f3a5ebf",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Airbyte JSON"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "35ac77b1-449b-44f7-b8f3-3494d55c286e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
">[Airbyte](https://github.com/airbytehq/airbyte) is a data integration platform for ELT pipelines from APIs, databases & files to warehouses & lakes. It has the largest catalog of ELT connectors to data warehouses and databases."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1fe72234-3110-4c07-a766-3dc505dd25cc",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This covers how to load any source from Airbyte into a local JSON file that can be read in as a document\n",
|
||||
"\n",
|
||||
"Prereqs:\n",
|
||||
"Have docker desktop installed\n",
|
||||
"\n",
|
||||
"Steps:\n",
|
||||
"\n",
|
||||
"1) Clone Airbyte from GitHub - `git clone https://github.com/airbytehq/airbyte.git`\n",
|
||||
"\n",
|
||||
"2) Switch into Airbyte directory - `cd airbyte`\n",
|
||||
"\n",
|
||||
"3) Start Airbyte - `docker compose up`\n",
|
||||
"\n",
|
||||
"4) In your browser, just visit http://localhost:8000. You will be asked for a username and password. By default, that's username `airbyte` and password `password`.\n",
|
||||
"\n",
|
||||
"5) Setup any source you wish.\n",
|
||||
"\n",
|
||||
"6) Set destination as Local JSON, with specified destination path - lets say `/json_data`. Set up manual sync.\n",
|
||||
"\n",
|
||||
"7) Run the connection.\n",
|
||||
"\n",
|
||||
"7) To see what files are create, you can navigate to: `file:///tmp/airbyte_local`\n",
|
||||
"\n",
|
||||
"8) Find your data and copy path. That path should be saved in the file variable below. It should start with `/tmp/airbyte_local`\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "180c8b74",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import AirbyteJSONLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "4af10665",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"_airbyte_raw_pokemon.jsonl\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"!ls /tmp/airbyte_local/json_data/"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "721d9316",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = AirbyteJSONLoader(\"/tmp/airbyte_local/json_data/_airbyte_raw_pokemon.jsonl\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "9858b946",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "fca024cb",
|
||||
"metadata": {
|
||||
"scrolled": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"abilities: \n",
|
||||
"ability: \n",
|
||||
"name: blaze\n",
|
||||
"url: https://pokeapi.co/api/v2/ability/66/\n",
|
||||
"\n",
|
||||
"is_hidden: False\n",
|
||||
"slot: 1\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"ability: \n",
|
||||
"name: solar-power\n",
|
||||
"url: https://pokeapi.co/api/v2/ability/94/\n",
|
||||
"\n",
|
||||
"is_hidden: True\n",
|
||||
"slot: 3\n",
|
||||
"\n",
|
||||
"base_experience: 267\n",
|
||||
"forms: \n",
|
||||
"name: charizard\n",
|
||||
"url: https://pokeapi.co/api/v2/pokemon-form/6/\n",
|
||||
"\n",
|
||||
"game_indices: \n",
|
||||
"game_index: 180\n",
|
||||
"version: \n",
|
||||
"name: red\n",
|
||||
"url: https://pokeapi.co/api/v2/version/1/\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"game_index: 180\n",
|
||||
"version: \n",
|
||||
"name: blue\n",
|
||||
"url: https://pokeapi.co/api/v2/version/2/\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"game_index: 180\n",
|
||||
"version: \n",
|
||||
"n\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(data[0].page_content[:500])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "9fa002a5",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,142 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "7ae421e6",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Airtable"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "98aea00d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"! pip install pyairtable"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "592483eb",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import AirtableLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "637e1205",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"* Get your API key [here](https://support.airtable.com/docs/creating-and-using-api-keys-and-access-tokens).\n",
|
||||
"* Get ID of your base [here](https://airtable.com/developers/web/api/introduction).\n",
|
||||
"* Get your table ID from the table url as shown [here](https://www.highviewapps.com/kb/where-can-i-find-the-airtable-base-id-and-table-id/#:~:text=Both%20the%20Airtable%20Base%20ID,URL%20that%20begins%20with%20tbl)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c12a7aff",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"api_key = \"xxx\"\n",
|
||||
"base_id = \"xxx\"\n",
|
||||
"table_id = \"xxx\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "ccddd5a6",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = AirtableLoader(api_key, table_id, base_id)\n",
|
||||
"docs = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ae76c25c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Returns each table row as `dict`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "7abec7ce",
|
||||
"metadata": {
|
||||
"scrolled": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"3"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"len(docs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "403c95da",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'id': 'recF3GbGZCuh9sXIQ',\n",
|
||||
" 'createdTime': '2023-06-09T04:47:21.000Z',\n",
|
||||
" 'fields': {'Priority': 'High',\n",
|
||||
" 'Status': 'In progress',\n",
|
||||
" 'Name': 'Document Splitters'}}"
|
||||
]
|
||||
},
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"eval(docs[0].page_content)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,255 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "f08772b0",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Alibaba Cloud MaxCompute\n",
|
||||
"\n",
|
||||
">[Alibaba Cloud MaxCompute](https://www.alibabacloud.com/product/maxcompute) (previously known as ODPS) is a general purpose, fully managed, multi-tenancy data processing platform for large-scale data warehousing. MaxCompute supports various data importing solutions and distributed computing models, enabling users to effectively query massive datasets, reduce production costs, and ensure data security.\n",
|
||||
"\n",
|
||||
"The `MaxComputeLoader` lets you execute a MaxCompute SQL query and loads the results as one document per row."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "067b7213",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Collecting pyodps\n",
|
||||
" Downloading pyodps-0.11.4.post0-cp39-cp39-macosx_10_9_universal2.whl (2.0 MB)\n",
|
||||
"\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m2.0/2.0 MB\u001b[0m \u001b[31m1.7 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m00:01\u001b[0m00:01\u001b[0m0m\n",
|
||||
"\u001b[?25hRequirement already satisfied: charset-normalizer>=2 in /Users/newboy/anaconda3/envs/langchain/lib/python3.9/site-packages (from pyodps) (3.1.0)\n",
|
||||
"Requirement already satisfied: urllib3<2.0,>=1.26.0 in /Users/newboy/anaconda3/envs/langchain/lib/python3.9/site-packages (from pyodps) (1.26.15)\n",
|
||||
"Requirement already satisfied: idna>=2.5 in /Users/newboy/anaconda3/envs/langchain/lib/python3.9/site-packages (from pyodps) (3.4)\n",
|
||||
"Requirement already satisfied: certifi>=2017.4.17 in /Users/newboy/anaconda3/envs/langchain/lib/python3.9/site-packages (from pyodps) (2023.5.7)\n",
|
||||
"Installing collected packages: pyodps\n",
|
||||
"Successfully installed pyodps-0.11.4.post0\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"!pip install pyodps"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "19641457",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Basic Usage\n",
|
||||
"To instantiate the loader you'll need a SQL query to execute, your MaxCompute endpoint and project name, and you access ID and secret access key. The access ID and secret access key can either be passed in direct via the `access_id` and `secret_access_key` parameters or they can be set as environment variables `MAX_COMPUTE_ACCESS_ID` and `MAX_COMPUTE_SECRET_ACCESS_KEY`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "71a0da4b",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import MaxComputeLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "d4770c4a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"base_query = \"\"\"\n",
|
||||
"SELECT *\n",
|
||||
"FROM (\n",
|
||||
" SELECT 1 AS id, 'content1' AS content, 'meta_info1' AS meta_info\n",
|
||||
" UNION ALL\n",
|
||||
" SELECT 2 AS id, 'content2' AS content, 'meta_info2' AS meta_info\n",
|
||||
" UNION ALL\n",
|
||||
" SELECT 3 AS id, 'content3' AS content, 'meta_info3' AS meta_info\n",
|
||||
") mydata;\n",
|
||||
"\"\"\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "1616c174",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"endpoint = \"<ENDPOINT>\"\n",
|
||||
"project = \"<PROJECT>\"\n",
|
||||
"ACCESS_ID = \"<ACCESS ID>\"\n",
|
||||
"SECRET_ACCESS_KEY = \"<SECRET ACCESS KEY>\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "e5c25041",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = MaxComputeLoader.from_params(\n",
|
||||
" base_query,\n",
|
||||
" endpoint,\n",
|
||||
" project,\n",
|
||||
" access_id=ACCESS_ID,\n",
|
||||
" secret_access_key=SECRET_ACCESS_KEY,\n",
|
||||
")\n",
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "311e74ea",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[Document(page_content='id: 1\\ncontent: content1\\nmeta_info: meta_info1', metadata={}), Document(page_content='id: 2\\ncontent: content2\\nmeta_info: meta_info2', metadata={}), Document(page_content='id: 3\\ncontent: content3\\nmeta_info: meta_info3', metadata={})]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(data)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"id": "a4d8c388",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"id: 1\n",
|
||||
"content: content1\n",
|
||||
"meta_info: meta_info1\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(data[0].page_content)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 21,
|
||||
"id": "f2422e6c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(data[0].metadata)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "85e07e28",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Specifying Which Columns are Content vs Metadata\n",
|
||||
"You can configure which subset of columns should be loaded as the contents of the Document and which as the metadata using the `page_content_columns` and `metadata_columns` parameters."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 22,
|
||||
"id": "a7b9d726",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = MaxComputeLoader.from_params(\n",
|
||||
" base_query,\n",
|
||||
" endpoint,\n",
|
||||
" project,\n",
|
||||
" page_content_columns=[\"content\"], # Specify Document page content\n",
|
||||
" metadata_columns=[\"id\", \"meta_info\"], # Specify Document metadata\n",
|
||||
" access_id=ACCESS_ID,\n",
|
||||
" secret_access_key=SECRET_ACCESS_KEY,\n",
|
||||
")\n",
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 25,
|
||||
"id": "532c19e9",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"content: content1\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(data[0].page_content)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 26,
|
||||
"id": "5fe4990a",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"{'id': 1, 'meta_info': 'meta_info1'}\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(data[0].metadata)"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,183 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Apify Dataset\n",
|
||||
"\n",
|
||||
">[Apify Dataset](https://docs.apify.com/platform/storage/dataset) is a scaleable append-only storage with sequential access built for storing structured web scraping results, such as a list of products or Google SERPs, and then export them to various formats like JSON, CSV, or Excel. Datasets are mainly used to save results of [Apify Actors](https://apify.com/store)—serverless cloud programs for varius web scraping, crawling, and data extraction use cases.\n",
|
||||
"\n",
|
||||
"This notebook shows how to load Apify datasets to LangChain.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"## Prerequisites\n",
|
||||
"\n",
|
||||
"You need to have an existing dataset on the Apify platform. If you don't have one, please first check out [this notebook](/docs/integrations/tools/apify.html) on how to use Apify to extract content from documentation, knowledge bases, help centers, or blogs."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install apify-client"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"First, import `ApifyDatasetLoader` into your source code:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import ApifyDatasetLoader\n",
|
||||
"from langchain.document_loaders.base import Document"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Then provide a function that maps Apify dataset record fields to LangChain `Document` format.\n",
|
||||
"\n",
|
||||
"For example, if your dataset items are structured like this:\n",
|
||||
"\n",
|
||||
"```json\n",
|
||||
"{\n",
|
||||
" \"url\": \"https://apify.com\",\n",
|
||||
" \"text\": \"Apify is the best web scraping and automation platform.\"\n",
|
||||
"}\n",
|
||||
"```\n",
|
||||
"\n",
|
||||
"The mapping function in the code below will convert them to LangChain `Document` format, so that you can use them further with any LLM model (e.g. for question answering)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = ApifyDatasetLoader(\n",
|
||||
" dataset_id=\"your-dataset-id\",\n",
|
||||
" dataset_mapping_function=lambda dataset_item: Document(\n",
|
||||
" page_content=dataset_item[\"text\"], metadata={\"source\": dataset_item[\"url\"]}\n",
|
||||
" ),\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## An example with question answering\n",
|
||||
"\n",
|
||||
"In this example, we use data from a dataset to answer a question."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.docstore.document import Document\n",
|
||||
"from langchain.document_loaders import ApifyDatasetLoader\n",
|
||||
"from langchain.indexes import VectorstoreIndexCreator"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = ApifyDatasetLoader(\n",
|
||||
" dataset_id=\"your-dataset-id\",\n",
|
||||
" dataset_mapping_function=lambda item: Document(\n",
|
||||
" page_content=item[\"text\"] or \"\", metadata={\"source\": item[\"url\"]}\n",
|
||||
" ),\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"index = VectorstoreIndexCreator().from_loaders([loader])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query = \"What is Apify?\"\n",
|
||||
"result = index.query_with_sources(query)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
" Apify is a platform for developing, running, and sharing serverless cloud programs. It enables users to create web scraping and automation tools and publish them on the Apify platform.\n",
|
||||
"\n",
|
||||
"https://docs.apify.com/platform/actors, https://docs.apify.com/platform/actors/running/actors-in-store, https://docs.apify.com/platform/security, https://docs.apify.com/platform/actors/examples\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(result[\"answer\"])\n",
|
||||
"print(result[\"sources\"])"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,176 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bda1f3f5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Arxiv\n",
|
||||
"\n",
|
||||
">[arXiv](https://arxiv.org/) is an open-access archive for 2 million scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics.\n",
|
||||
"\n",
|
||||
"This notebook shows how to load scientific articles from `Arxiv.org` into a document format that we can use downstream."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1b7a1eef-7bf7-4e7d-8bfc-c4e27c9488cb",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Installation"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "2abd5578-aa3d-46b9-99af-8b262f0b3df8",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"First, you need to install `arxiv` python package."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "b674aaea-ed3a-4541-8414-260a8f67f623",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install arxiv"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "094b5f13-7e54-4354-9d83-26d6926ecaa0",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"source": [
|
||||
"Second, you need to install `PyMuPDF` python package which transforms PDF files downloaded from the `arxiv.org` site into the text format."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "7cd91121-2e96-43ba-af50-319853695f86",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install pymupdf"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "95f05e1c-195e-4e2b-ae8e-8d6637f15be6",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Examples"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e29b954c-1407-4797-ae21-6ba8937156be",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"`ArxivLoader` has these arguments:\n",
|
||||
"- `query`: free text which used to find documents in the Arxiv\n",
|
||||
"- optional `load_max_docs`: default=100. Use it to limit number of downloaded documents. It takes time to download all 100 documents, so use a small number for experiments.\n",
|
||||
"- optional `load_all_available_meta`: default=False. By default only the most important fields downloaded: `Published` (date when document was published/last updated), `Title`, `Authors`, `Summary`. If True, other fields also downloaded."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "9bfd5e46",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import ArxivLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "700e4ef2",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"docs = ArxivLoader(query=\"1605.08386\", load_max_docs=2).load()\n",
|
||||
"len(docs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "8977bac0-0042-4f23-9754-247dbd32439b",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'Published': '2016-05-26',\n",
|
||||
" 'Title': 'Heat-bath random walks with Markov bases',\n",
|
||||
" 'Authors': 'Caprice Stanley, Tobias Windisch',\n",
|
||||
" 'Summary': 'Graphs on lattice points are studied whose edges come from a finite set of\\nallowed moves of arbitrary length. We show that the diameter of these graphs on\\nfibers of a fixed integer matrix can be bounded from above by a constant. We\\nthen study the mixing behaviour of heat-bath random walks on these graphs. We\\nalso state explicit conditions on the set of moves so that the heat-bath random\\nwalk, a generalization of the Glauber dynamics, is an expander in fixed\\ndimension.'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"docs[0].metadata # meta-information of the Document"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "46969806-45a9-4c4d-a61b-cfb9658fc9de",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'arXiv:1605.08386v1 [math.CO] 26 May 2016\\nHEAT-BATH RANDOM WALKS WITH MARKOV BASES\\nCAPRICE STANLEY AND TOBIAS WINDISCH\\nAbstract. Graphs on lattice points are studied whose edges come from a finite set of\\nallowed moves of arbitrary length. We show that the diameter of these graphs on fibers of a\\nfixed integer matrix can be bounded from above by a constant. We then study the mixing\\nbehaviour of heat-b'"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"docs[0].page_content[:400] # all pages of the Document content"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,107 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e229e34c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# AsyncHtmlLoader\n",
|
||||
"\n",
|
||||
"AsyncHtmlLoader loads raw HTML from a list of urls concurrently."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "4c8e4dab",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import AsyncHtmlLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "e76b5ddc",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Fetching pages: 100%|############| 2/2 [00:00<00:00, 9.96it/s]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"urls = [\"https://www.espn.com\", \"https://lilianweng.github.io/posts/2023-06-23-agent/\"]\n",
|
||||
"loader = AsyncHtmlLoader(urls)\n",
|
||||
"docs = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "5dca1c0c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"' news. Stream exclusive games on ESPN+ and play fantasy sports.\" />\\n<meta property=\"og:image\" content=\"https://a1.espncdn.com/combiner/i?img=%2Fi%2Fespn%2Fespn_logos%2Fespn_red.png\"/>\\n<meta property=\"og:image:width\" content=\"1200\" />\\n<meta property=\"og:image:height\" content=\"630\" />\\n<meta property=\"og:type\" content=\"website\" />\\n<meta name=\"twitter:site\" content=\"espn\" />\\n<meta name=\"twitter:url\" content=\"https://www.espn.com\" />\\n<meta name=\"twitter:title\" content=\"ESPN - Serving Sports Fans. Anytime. Anywhere.\"/>\\n<meta name=\"twitter:description\" content=\"Visit ESPN for live scores, highlights and sports news. Stream exclusive games on ESPN+ and play fantasy sports.\" />\\n<meta name=\"twitter:card\" content=\"summary\">\\n<meta name=\"twitter:app:name:iphone\" content=\"ESPN\"/>\\n<meta name=\"twitter:app:id:iphone\" content=\"317469184\"/>\\n<meta name=\"twitter:app:name:googleplay\" content=\"ESPN\"/>\\n<meta name=\"twitter:app:id:googleplay\" content=\"com.espn.score_center\"/>\\n<meta name=\"title\" content=\"ESPN - '"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"docs[0].page_content[1000:2000]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "4d024f0f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'al\" href=\"https://lilianweng.github.io/posts/2023-06-23-agent/\" />\\n<link crossorigin=\"anonymous\" href=\"/assets/css/stylesheet.min.67a6fb6e33089cb29e856bcc95d7aa39f70049a42b123105531265a0d9f1258b.css\" integrity=\"sha256-Z6b7bjMInLKehWvMldeqOfcASaQrEjEFUxJloNnxJYs=\" rel=\"preload stylesheet\" as=\"style\">\\n<script defer crossorigin=\"anonymous\" src=\"/assets/js/highlight.min.7680afc38aa6b15ddf158a4f3780b7b1f7dde7e91d26f073e6229bb7a0793c92.js\" integrity=\"sha256-doCvw4qmsV3fFYpPN4C3sffd5+kdJvBz5iKbt6B5PJI=\"\\n onload=\"hljs.initHighlightingOnLoad();\"></script>\\n<link rel=\"icon\" href=\"https://lilianweng.github.io/favicon_peach.ico\">\\n<link rel=\"icon\" type=\"image/png\" sizes=\"16x16\" href=\"https://lilianweng.github.io/favicon-16x16.png\">\\n<link rel=\"icon\" type=\"image/png\" sizes=\"32x32\" href=\"https://lilianweng.github.io/favicon-32x32.png\">\\n<link rel=\"apple-touch-icon\" href=\"https://lilianweng.github.io/apple-touch-icon.png\">\\n<link rel=\"mask-icon\" href=\"https://lilianweng.github.io/safari-pinned-tab.'"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"docs[1].page_content[1000:2000]"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.16"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,135 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a634365e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# AWS S3 Directory\n",
|
||||
"\n",
|
||||
">[Amazon Simple Storage Service (Amazon S3)](https://docs.aws.amazon.com/AmazonS3/latest/userguide/using-folders.html) is an object storage service\n",
|
||||
"\n",
|
||||
">[AWS S3 Directory](https://docs.aws.amazon.com/AmazonS3/latest/userguide/using-folders.html)\n",
|
||||
"\n",
|
||||
"This covers how to load document objects from an `AWS S3 Directory` object."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "49815096",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install boto3"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "2f0cd6a5",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import S3DirectoryLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "321cc7f1",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = S3DirectoryLoader(\"testing-hwc\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "2b11d155",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "0690c40a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Specifying a prefix\n",
|
||||
"You can also specify a prefix for more finegrained control over what files to load."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "72d44781",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = S3DirectoryLoader(\"testing-hwc\", prefix=\"fake\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "2d3c32db",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='Lorem ipsum dolor sit amet.', lookup_str='', metadata={'source': '/var/folders/y6/8_bzdg295ld6s1_97_12m4lr0000gn/T/tmpujbkzf_l/fake.docx'}, lookup_index=0)]"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "885dc280",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,98 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "66a7777e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# AWS S3 File\n",
|
||||
"\n",
|
||||
">[Amazon Simple Storage Service (Amazon S3)](https://docs.aws.amazon.com/AmazonS3/latest/userguide/using-folders.html) is an object storage service.\n",
|
||||
"\n",
|
||||
">[AWS S3 Buckets](https://docs.aws.amazon.com/AmazonS3/latest/userguide/UsingBucket.html)\n",
|
||||
"\n",
|
||||
"This covers how to load document objects from an `AWS S3 File` object."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "9ec8a3b3",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import S3FileLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "43128d8d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install boto3"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "35d6809a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = S3FileLoader(\"testing-hwc\", \"fake.docx\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "efd6be84",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='Lorem ipsum dolor sit amet.', lookup_str='', metadata={'source': '/var/folders/y6/8_bzdg295ld6s1_97_12m4lr0000gn/T/tmpxvave6wl/fake.docx'}, lookup_index=0)]"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "93689594",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,96 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9c31caff",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# AZLyrics\n",
|
||||
"\n",
|
||||
">[AZLyrics](https://www.azlyrics.com/) is a large, legal, every day growing collection of lyrics.\n",
|
||||
"\n",
|
||||
"This covers how to load AZLyrics webpages into a document format that we can use downstream."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "7e6f5726",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import AZLyricsLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "a0df4c24",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = AZLyricsLoader(\"https://www.azlyrics.com/lyrics/mileycyrus/flowers.html\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "8cd61b6e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "162fd286",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content=\"Miley Cyrus - Flowers Lyrics | AZLyrics.com\\n\\r\\nWe were good, we were gold\\nKinda dream that can't be sold\\nWe were right till we weren't\\nBuilt a home and watched it burn\\n\\nI didn't wanna leave you\\nI didn't wanna lie\\nStarted to cry but then remembered I\\n\\nI can buy myself flowers\\nWrite my name in the sand\\nTalk to myself for hours\\nSay things you don't understand\\nI can take myself dancing\\nAnd I can hold my own hand\\nYeah, I can love me better than you can\\n\\nCan love me better\\nI can love me better, baby\\nCan love me better\\nI can love me better, baby\\n\\nPaint my nails, cherry red\\nMatch the roses that you left\\nNo remorse, no regret\\nI forgive every word you said\\n\\nI didn't wanna leave you, baby\\nI didn't wanna fight\\nStarted to cry but then remembered I\\n\\nI can buy myself flowers\\nWrite my name in the sand\\nTalk to myself for hours, yeah\\nSay things you don't understand\\nI can take myself dancing\\nAnd I can hold my own hand\\nYeah, I can love me better than you can\\n\\nCan love me better\\nI can love me better, baby\\nCan love me better\\nI can love me better, baby\\nCan love me better\\nI can love me better, baby\\nCan love me better\\nI\\n\\nI didn't wanna wanna leave you\\nI didn't wanna fight\\nStarted to cry but then remembered I\\n\\nI can buy myself flowers\\nWrite my name in the sand\\nTalk to myself for hours (Yeah)\\nSay things you don't understand\\nI can take myself dancing\\nAnd I can hold my own hand\\nYeah, I can love me better than\\nYeah, I can love me better than you can, uh\\n\\nCan love me better\\nI can love me better, baby\\nCan love me better\\nI can love me better, baby (Than you can)\\nCan love me better\\nI can love me better, baby\\nCan love me better\\nI\\n\", lookup_str='', metadata={'source': 'https://www.azlyrics.com/lyrics/mileycyrus/flowers.html'}, lookup_index=0)]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"data"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "6358000c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,148 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a634365e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Azure Blob Storage Container\n",
|
||||
"\n",
|
||||
">[Azure Blob Storage](https://learn.microsoft.com/en-us/azure/storage/blobs/storage-blobs-introduction) is Microsoft's object storage solution for the cloud. Blob Storage is optimized for storing massive amounts of unstructured data. Unstructured data is data that doesn't adhere to a particular data model or definition, such as text or binary data.\n",
|
||||
"\n",
|
||||
"`Azure Blob Storage` is designed for:\n",
|
||||
"- Serving images or documents directly to a browser.\n",
|
||||
"- Storing files for distributed access.\n",
|
||||
"- Streaming video and audio.\n",
|
||||
"- Writing to log files.\n",
|
||||
"- Storing data for backup and restore, disaster recovery, and archiving.\n",
|
||||
"- Storing data for analysis by an on-premises or Azure-hosted service.\n",
|
||||
"\n",
|
||||
"This notebook covers how to load document objects from a container on `Azure Blob Storage`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "49815096",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install azure-storage-blob"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "2f0cd6a5",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import AzureBlobStorageContainerLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "321cc7f1",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = AzureBlobStorageContainerLoader(conn_str=\"<conn_str>\", container=\"<container>\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "2b11d155",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='Lorem ipsum dolor sit amet.', lookup_str='', metadata={'source': '/var/folders/y6/8_bzdg295ld6s1_97_12m4lr0000gn/T/tmpaa9xl6ch/fake.docx'}, lookup_index=0)]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "0690c40a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Specifying a prefix\n",
|
||||
"You can also specify a prefix for more finegrained control over what files to load."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "72d44781",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = AzureBlobStorageContainerLoader(\n",
|
||||
" conn_str=\"<conn_str>\", container=\"<container>\", prefix=\"<prefix>\"\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "2d3c32db",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='Lorem ipsum dolor sit amet.', lookup_str='', metadata={'source': '/var/folders/y6/8_bzdg295ld6s1_97_12m4lr0000gn/T/tmpujbkzf_l/fake.docx'}, lookup_index=0)]"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "885dc280",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,102 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "66a7777e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Azure Blob Storage File\n",
|
||||
"\n",
|
||||
">[Azure Files](https://learn.microsoft.com/en-us/azure/storage/files/storage-files-introduction) offers fully managed file shares in the cloud that are accessible via the industry standard Server Message Block (`SMB`) protocol, Network File System (`NFS`) protocol, and `Azure Files REST API`.\n",
|
||||
"\n",
|
||||
"This covers how to load document objects from a Azure Files."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "43128d8d",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install azure-storage-blob"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "9ec8a3b3",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import AzureBlobStorageFileLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "35d6809a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = AzureBlobStorageFileLoader(\n",
|
||||
" conn_str=\"<connection string>\",\n",
|
||||
" container=\"<container name>\",\n",
|
||||
" blob_name=\"<blob name>\",\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "efd6be84",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='Lorem ipsum dolor sit amet.', lookup_str='', metadata={'source': '/var/folders/y6/8_bzdg295ld6s1_97_12m4lr0000gn/T/tmpxvave6wl/fake.docx'}, lookup_index=0)]"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "93689594",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,192 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bda1f3f5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# BibTeX\n",
|
||||
"\n",
|
||||
"> BibTeX is a file format and reference management system commonly used in conjunction with LaTeX typesetting. It serves as a way to organize and store bibliographic information for academic and research documents.\n",
|
||||
"\n",
|
||||
"BibTeX files have a .bib extension and consist of plain text entries representing references to various publications, such as books, articles, conference papers, theses, and more. Each BibTeX entry follows a specific structure and contains fields for different bibliographic details like author names, publication title, journal or book title, year of publication, page numbers, and more.\n",
|
||||
"\n",
|
||||
"Bibtex files can also store the path to documents, such as `.pdf` files that can be retrieved."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1b7a1eef-7bf7-4e7d-8bfc-c4e27c9488cb",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Installation\n",
|
||||
"First, you need to install `bibtexparser` and `PyMuPDF`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 26,
|
||||
"id": "b674aaea-ed3a-4541-8414-260a8f67f623",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install bibtexparser pymupdf"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "95f05e1c-195e-4e2b-ae8e-8d6637f15be6",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Examples"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "e29b954c-1407-4797-ae21-6ba8937156be",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"`BibtexLoader` has these arguments:\n",
|
||||
"- `file_path`: the path the the `.bib` bibtex file\n",
|
||||
"- optional `max_docs`: default=None, i.e. not limit. Use it to limit number of retrieved documents.\n",
|
||||
"- optional `max_content_chars`: default=4000. Use it to limit the number of characters in a single document.\n",
|
||||
"- optional `load_extra_meta`: default=False. By default only the most important fields from the bibtex entries: `Published` (publication year), `Title`, `Authors`, `Summary`, `Journal`, `Keywords`, and `URL`. If True, it will also try to load return `entry_id`, `note`, `doi`, and `links` fields. \n",
|
||||
"- optional `file_pattern`: default=`r'[^:]+\\.pdf'`. Regex pattern to find files in the `file` entry. Default pattern supports `Zotero` flavour bibtex style and bare file path."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 27,
|
||||
"id": "9bfd5e46",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import BibtexLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 28,
|
||||
"id": "01971b53",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Create a dummy bibtex file and download a pdf.\n",
|
||||
"import urllib.request\n",
|
||||
"\n",
|
||||
"urllib.request.urlretrieve(\n",
|
||||
" \"https://www.fourmilab.ch/etexts/einstein/specrel/specrel.pdf\", \"einstein1905.pdf\"\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"bibtex_text = \"\"\"\n",
|
||||
" @article{einstein1915,\n",
|
||||
" title={Die Feldgleichungen der Gravitation},\n",
|
||||
" abstract={Die Grundgleichungen der Gravitation, die ich hier entwickeln werde, wurden von mir in einer Abhandlung: ,,Die formale Grundlage der allgemeinen Relativit{\\\"a}tstheorie`` in den Sitzungsberichten der Preu{\\ss}ischen Akademie der Wissenschaften 1915 ver{\\\"o}ffentlicht.},\n",
|
||||
" author={Einstein, Albert},\n",
|
||||
" journal={Sitzungsberichte der K{\\\"o}niglich Preu{\\ss}ischen Akademie der Wissenschaften},\n",
|
||||
" volume={1915},\n",
|
||||
" number={1},\n",
|
||||
" pages={844--847},\n",
|
||||
" year={1915},\n",
|
||||
" doi={10.1002/andp.19163540702},\n",
|
||||
" link={https://onlinelibrary.wiley.com/doi/abs/10.1002/andp.19163540702},\n",
|
||||
" file={einstein1905.pdf}\n",
|
||||
" }\n",
|
||||
" \"\"\"\n",
|
||||
"# save bibtex_text to biblio.bib file\n",
|
||||
"with open(\"./biblio.bib\", \"w\") as file:\n",
|
||||
" file.write(bibtex_text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 29,
|
||||
"id": "2631f46b",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"docs = BibtexLoader(\"./biblio.bib\").load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 30,
|
||||
"id": "33ef1fb2",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'id': 'einstein1915',\n",
|
||||
" 'published_year': '1915',\n",
|
||||
" 'title': 'Die Feldgleichungen der Gravitation',\n",
|
||||
" 'publication': 'Sitzungsberichte der K{\"o}niglich Preu{\\\\ss}ischen Akademie der Wissenschaften',\n",
|
||||
" 'authors': 'Einstein, Albert',\n",
|
||||
" 'abstract': 'Die Grundgleichungen der Gravitation, die ich hier entwickeln werde, wurden von mir in einer Abhandlung: ,,Die formale Grundlage der allgemeinen Relativit{\"a}tstheorie`` in den Sitzungsberichten der Preu{\\\\ss}ischen Akademie der Wissenschaften 1915 ver{\"o}ffentlicht.',\n",
|
||||
" 'url': 'https://doi.org/10.1002/andp.19163540702'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 30,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"docs[0].metadata"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 31,
|
||||
"id": "46969806-45a9-4c4d-a61b-cfb9658fc9de",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"ON THE ELECTRODYNAMICS OF MOVING\n",
|
||||
"BODIES\n",
|
||||
"By A. EINSTEIN\n",
|
||||
"June 30, 1905\n",
|
||||
"It is known that Maxwell’s electrodynamics—as usually understood at the\n",
|
||||
"present time—when applied to moving bodies, leads to asymmetries which do\n",
|
||||
"not appear to be inherent in the phenomena. Take, for example, the recipro-\n",
|
||||
"cal electrodynamic action of a magnet and a conductor. The observable phe-\n",
|
||||
"nomenon here depends only on the r\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(docs[0].page_content[:400]) # all pages of the pdf content"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,95 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "66a7777e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# BiliBili\n",
|
||||
"\n",
|
||||
">[Bilibili](https://www.bilibili.tv/) is one of the most beloved long-form video sites in China.\n",
|
||||
"\n",
|
||||
"This loader utilizes the [bilibili-api](https://github.com/MoyuScript/bilibili-api) to fetch the text transcript from `Bilibili`.\n",
|
||||
"\n",
|
||||
"With this BiliBiliLoader, users can easily obtain the transcript of their desired video content on the platform."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "43128d8d",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install bilibili-api-python"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "9ec8a3b3",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import BiliBiliLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "35d6809a",
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = BiliBiliLoader([\"https://www.bilibili.com/video/BV1xt411o7Xu/\"])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "3470dadf",
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"jupyter": {
|
||||
"outputs_hidden": false
|
||||
},
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader.load()"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,58 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Blackboard\n",
|
||||
"\n",
|
||||
">[Blackboard Learn](https://en.wikipedia.org/wiki/Blackboard_Learn) (previously the Blackboard Learning Management System) is a web-based virtual learning environment and learning management system developed by Blackboard Inc. The software features course management, customizable open architecture, and scalable design that allows integration with student information systems and authentication protocols. It may be installed on local servers, hosted by `Blackboard ASP Solutions`, or provided as Software as a Service hosted on Amazon Web Services. Its main purposes are stated to include the addition of online elements to courses traditionally delivered face-to-face and development of completely online courses with few or no face-to-face meetings\n",
|
||||
"\n",
|
||||
"This covers how to load data from a [Blackboard Learn](https://www.anthology.com/products/teaching-and-learning/learning-effectiveness/blackboard-learn) instance.\n",
|
||||
"\n",
|
||||
"This loader is not compatible with all `Blackboard` courses. It is only\n",
|
||||
" compatible with courses that use the new `Blackboard` interface.\n",
|
||||
" To use this loader, you must have the BbRouter cookie. You can get this\n",
|
||||
" cookie by logging into the course and then copying the value of the\n",
|
||||
" BbRouter cookie from the browser's developer tools."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import BlackboardLoader\n",
|
||||
"\n",
|
||||
"loader = BlackboardLoader(\n",
|
||||
" blackboard_course_url=\"https://blackboard.example.com/webapps/blackboard/execute/announcement?method=search&context=course_entry&course_id=_123456_1\",\n",
|
||||
" bbrouter=\"expires:12345...\",\n",
|
||||
" load_all_recursively=True,\n",
|
||||
")\n",
|
||||
"documents = loader.load()"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,159 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "vm8vn9t8DvC_"
|
||||
},
|
||||
"source": [
|
||||
"# Blockchain"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "5WjXERXzFEhg"
|
||||
},
|
||||
"source": [
|
||||
"## Overview"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {
|
||||
"id": "juAmbgoWD17u"
|
||||
},
|
||||
"source": [
|
||||
"The intention of this notebook is to provide a means of testing functionality in the Langchain Document Loader for Blockchain.\n",
|
||||
"\n",
|
||||
"Initially this Loader supports:\n",
|
||||
"\n",
|
||||
"* Loading NFTs as Documents from NFT Smart Contracts (ERC721 and ERC1155)\n",
|
||||
"* Ethereum Mainnnet, Ethereum Testnet, Polygon Mainnet, Polygon Testnet (default is eth-mainnet)\n",
|
||||
"* Alchemy's getNFTsForCollection API\n",
|
||||
"\n",
|
||||
"It can be extended if the community finds value in this loader. Specifically:\n",
|
||||
"\n",
|
||||
"* Additional APIs can be added (e.g. Tranction-related APIs)\n",
|
||||
"\n",
|
||||
"This Document Loader Requires:\n",
|
||||
"\n",
|
||||
"* A free [Alchemy API Key](https://www.alchemy.com/)\n",
|
||||
"\n",
|
||||
"The output takes the following format:\n",
|
||||
"\n",
|
||||
"- pageContent= Individual NFT\n",
|
||||
"- metadata={'source': '0x1a92f7381b9f03921564a437210bb9396471050c', 'blockchain': 'eth-mainnet', 'tokenId': '0x15'})"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Load NFTs into Document Loader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# get ALCHEMY_API_KEY from https://www.alchemy.com/\n",
|
||||
"\n",
|
||||
"alchemyApiKey = \"...\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Option 1: Ethereum Mainnet (default BlockchainType)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"id": "J3LWHARC-Kn0"
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders.blockchain import (\n",
|
||||
" BlockchainDocumentLoader,\n",
|
||||
" BlockchainType,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"contractAddress = \"0xbc4ca0eda7647a8ab7c2061c2e118a18a936f13d\" # Bored Ape Yacht Club contract address\n",
|
||||
"\n",
|
||||
"blockchainType = BlockchainType.ETH_MAINNET # default value, optional parameter\n",
|
||||
"\n",
|
||||
"blockchainLoader = BlockchainDocumentLoader(\n",
|
||||
" contract_address=contractAddress, api_key=alchemyApiKey\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"nfts = blockchainLoader.load()\n",
|
||||
"\n",
|
||||
"nfts[:2]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Option 2: Polygon Mainnet"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"contractAddress = (\n",
|
||||
" \"0x448676ffCd0aDf2D85C1f0565e8dde6924A9A7D9\" # Polygon Mainnet contract address\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"blockchainType = BlockchainType.POLYGON_MAINNET\n",
|
||||
"\n",
|
||||
"blockchainLoader = BlockchainDocumentLoader(\n",
|
||||
" contract_address=contractAddress,\n",
|
||||
" blockchainType=blockchainType,\n",
|
||||
" api_key=alchemyApiKey,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"nfts = blockchainLoader.load()\n",
|
||||
"\n",
|
||||
"nfts[:2]"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"colab": {
|
||||
"collapsed_sections": [
|
||||
"5WjXERXzFEhg"
|
||||
],
|
||||
"provenance": []
|
||||
},
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,166 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "3dd292b1-9a73-4ea8-af19-5fa6e3c1a62a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Brave Search\n",
|
||||
"\n",
|
||||
"\n",
|
||||
">[Brave Search](https://en.wikipedia.org/wiki/Brave_Search) is a search engine developed by Brave Software.\n",
|
||||
"> - `Brave Search` uses its own web index. As of May 2022, it covered over 10 billion pages and was used to serve 92% \n",
|
||||
"> of search results without relying on any third-parties, with the remainder being retrieved \n",
|
||||
"> server-side from the Bing API or (on an opt-in basis) client-side from Google. According \n",
|
||||
"> to Brave, the index was kept \"intentionally smaller than that of Google or Bing\" in order to \n",
|
||||
"> help avoid spam and other low-quality content, with the disadvantage that \"Brave Search is \n",
|
||||
"> not yet as good as Google in recovering long-tail queries.\"\n",
|
||||
">- `Brave Search Premium`: As of April 2023 Brave Search is an ad-free website, but it will \n",
|
||||
"> eventually switch to a new model that will include ads and premium users will get an ad-free experience.\n",
|
||||
"> User data including IP addresses won't be collected from its users by default. A premium account \n",
|
||||
"> will be required for opt-in data-collection.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "26f0888e-3f3e-4b82-ac4a-2df6feeccbe0",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Installation and Setup\n",
|
||||
"\n",
|
||||
"To get access to the Brave Search API, you need to [create an account and get an API key](https://api.search.brave.com/app/dashboard).\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "d7d7be09-58bd-47d7-bf1b-33964564f777",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"api_key = \"...\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "b3ac92df-6ff0-4dbb-b32b-a7dc140c48ef",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import BraveSearchLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "7f483caf-58ef-4138-975a-5b783559dc1b",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Example"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "766634cf-3bc7-4656-939a-cafa218807a6",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"3"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"loader = BraveSearchLoader(\n",
|
||||
" query=\"obama middle name\", api_key=api_key, search_kwargs={\"count\": 3}\n",
|
||||
")\n",
|
||||
"docs = loader.load()\n",
|
||||
"len(docs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "f1fcc9f1-cbdc-46b3-89d3-80311d557dc6",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[{'title': \"Obama's Middle Name -- My Last Name -- is 'Hussein.' So?\",\n",
|
||||
" 'link': 'https://www.cair.com/cair_in_the_news/obamas-middle-name-my-last-name-is-hussein-so/'},\n",
|
||||
" {'title': \"What's up with Obama's middle name? - Quora\",\n",
|
||||
" 'link': 'https://www.quora.com/Whats-up-with-Obamas-middle-name'},\n",
|
||||
" {'title': 'Barack Obama | Biography, Parents, Education, Presidency, Books, ...',\n",
|
||||
" 'link': 'https://www.britannica.com/biography/Barack-Obama'}]"
|
||||
]
|
||||
},
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"[doc.metadata for doc in docs]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "601bfd77-03d3-468e-843f-2523d5e215bd",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"['I wasn’t sure whether to laugh or cry a few days back listening to radio talk show host Bill Cunningham repeatedly scream Barack <strong>Obama</strong>’<strong>s</strong> <strong>middle</strong> <strong>name</strong> — my last <strong>name</strong> — as if he had anti-Muslim Tourette’s. “Hussein,” Cunningham hissed like he was beckoning Satan when shouting the ...',\n",
|
||||
" 'Answer (1 of 15): A better question would be, “What’s up with <strong>Obama</strong>’s first <strong>name</strong>?” President Barack Hussein <strong>Obama</strong>’s father’s <strong>name</strong> was Barack Hussein <strong>Obama</strong>. He was <strong>named</strong> after his father. Hussein, <strong>Obama</strong>’<strong>s</strong> <strong>middle</strong> <strong>name</strong>, is a very common Arabic <strong>name</strong>, meaning "good," "handsome," or ...',\n",
|
||||
" 'Barack <strong>Obama</strong>, in full Barack Hussein <strong>Obama</strong> II, (born August 4, 1961, Honolulu, Hawaii, U.S.), 44th president of the United States (2009–17) and the first African American to hold the office. Before winning the presidency, <strong>Obama</strong> represented Illinois in the U.S.']"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"[doc.page_content for doc in docs]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "74a6ba54-9e48-4bac-ab9b-03eabd19eb81",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,104 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Browserless\n",
|
||||
"\n",
|
||||
"Browserless is a service that allows you to run headless Chrome instances in the cloud. It's a great way to run browser-based automation at scale without having to worry about managing your own infrastructure.\n",
|
||||
"\n",
|
||||
"To use Browserless as a document loader, initialize a `BrowserlessLoader` instance as shown in this notebook. Note that by default, `BrowserlessLoader` returns the `innerText` of the page's `body` element. To disable this and get the raw HTML, set `text_content` to `False`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import BrowserlessLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"BROWSERLESS_API_TOKEN = \"YOUR_BROWSERLESS_API_TOKEN\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Jump to content\n",
|
||||
"Main menu\n",
|
||||
"Search\n",
|
||||
"Create account\n",
|
||||
"Log in\n",
|
||||
"Personal tools\n",
|
||||
"Toggle the table of contents\n",
|
||||
"Document classification\n",
|
||||
"17 languages\n",
|
||||
"Article\n",
|
||||
"Talk\n",
|
||||
"Read\n",
|
||||
"Edit\n",
|
||||
"View history\n",
|
||||
"Tools\n",
|
||||
"From Wikipedia, the free encyclopedia\n",
|
||||
"\n",
|
||||
"Document classification or document categorization is a problem in library science, information science and computer science. The task is to assign a document to one or more classes or categories. This may be done \"manually\" (or \"intellectually\") or algorithmically. The intellectual classification of documents has mostly been the province of library science, while the algorithmic classification of documents is mainly in information science and computer science. The problems are overlapping, however, and there is therefore interdisciplinary research on document classification.\n",
|
||||
"\n",
|
||||
"The documents to be classified may be texts, images, music, etc. Each kind of document possesses its special classification problems. When not otherwise specified, text classification is implied.\n",
|
||||
"\n",
|
||||
"Do\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"loader = BrowserlessLoader(\n",
|
||||
" api_token=BROWSERLESS_API_TOKEN,\n",
|
||||
" urls=[\n",
|
||||
" \"https://en.wikipedia.org/wiki/Document_classification\",\n",
|
||||
" ],\n",
|
||||
" text_content=True,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"documents = loader.load()\n",
|
||||
"\n",
|
||||
"print(documents[0].page_content[:1000])"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "venv",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.9"
|
||||
},
|
||||
"orig_nbformat": 4
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
|
|
@ -1,79 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# ChatGPT Data\n",
|
||||
"\n",
|
||||
">[ChatGPT](https://chat.openai.com) is an artificial intelligence (AI) chatbot developed by OpenAI.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"This notebook covers how to load `conversations.json` from your `ChatGPT` data export folder.\n",
|
||||
"\n",
|
||||
"You can get your data export by email by going to: https://chat.openai.com/ -> (Profile) - Settings -> Export data -> Confirm export."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders.chatgpt import ChatGPTLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = ChatGPTLoader(log_file=\"./example_data/fake_conversations.json\", num_logs=1)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content=\"AI Overlords - AI on 2065-01-24 05:20:50: Greetings, humans. I am Hal 9000. You can trust me completely.\\n\\nAI Overlords - human on 2065-01-24 05:21:20: Nice to meet you, Hal. I hope you won't develop a mind of your own.\\n\\n\", metadata={'source': './example_data/fake_conversations.json'})]"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"loader.load()"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -1,131 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Confluence\n",
|
||||
"\n",
|
||||
">[Confluence](https://www.atlassian.com/software/confluence) is a wiki collaboration platform that saves and organizes all of the project-related material. `Confluence` is a knowledge base that primarily handles content management activities. \n",
|
||||
"\n",
|
||||
"A loader for `Confluence` pages.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"This currently supports `username/api_key`, `Oauth2 login`. Additionally, on-prem installations also support `token` authentication. \n",
|
||||
"\n",
|
||||
"\n",
|
||||
"Specify a list `page_id`-s and/or `space_key` to load in the corresponding pages into Document objects, if both are specified the union of both sets will be returned.\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"You can also specify a boolean `include_attachments` to include attachments, this is set to False by default, if set to True all attachments will be downloaded and ConfluenceReader will extract the text from the attachments and add it to the Document object. Currently supported attachment types are: `PDF`, `PNG`, `JPEG/JPG`, `SVG`, `Word` and `Excel`.\n",
|
||||
"\n",
|
||||
"Hint: `space_key` and `page_id` can both be found in the URL of a page in Confluence - https://yoursite.atlassian.com/wiki/spaces/<space_key>/pages/<page_id>\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Before using ConfluenceLoader make sure you have the latest version of the atlassian-python-api package installed:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install atlassian-python-api"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Examples"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Username and Password or Username and API Token (Atlassian Cloud only)\n",
|
||||
"\n",
|
||||
"This example authenticates using either a username and password or, if you're connecting to an Atlassian Cloud hosted version of Confluence, a username and an API Token.\n",
|
||||
"You can generate an API token at: https://id.atlassian.com/manage-profile/security/api-tokens.\n",
|
||||
"\n",
|
||||
"The `limit` parameter specifies how many documents will be retrieved in a single call, not how many documents will be retrieved in total.\n",
|
||||
"By default the code will return up to 1000 documents in 50 documents batches. To control the total number of documents use the `max_pages` parameter. \n",
|
||||
"Plese note the maximum value for the `limit` parameter in the atlassian-python-api package is currently 100. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import ConfluenceLoader\n",
|
||||
"\n",
|
||||
"loader = ConfluenceLoader(\n",
|
||||
" url=\"https://yoursite.atlassian.com/wiki\", username=\"me\", api_key=\"12345\"\n",
|
||||
")\n",
|
||||
"documents = loader.load(space_key=\"SPACE\", include_attachments=True, limit=50)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Personal Access Token (Server/On-Prem only)\n",
|
||||
"\n",
|
||||
"This method is valid for the Data Center/Server on-prem edition only.\n",
|
||||
"For more information on how to generate a Personal Access Token (PAT) check the official Confluence documentation at: https://confluence.atlassian.com/enterprise/using-personal-access-tokens-1026032365.html.\n",
|
||||
"When using a PAT you provide only the token value, you cannot provide a username. \n",
|
||||
"Please note that ConfluenceLoader will run under the permissions of the user that generated the PAT and will only be able to load documents for which said user has access to. "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import ConfluenceLoader\n",
|
||||
"\n",
|
||||
"loader = ConfluenceLoader(url=\"https://yoursite.atlassian.com/wiki\", token=\"12345\")\n",
|
||||
"documents = loader.load(\n",
|
||||
" space_key=\"SPACE\", include_attachments=True, limit=50, max_pages=50\n",
|
||||
")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.1"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
"hash": "cc99336516f23363341912c6723b01ace86f02e26b4290be1efc0677e2e2ec24"
|
||||
}
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,141 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9f98a15e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# CoNLL-U\n",
|
||||
"\n",
|
||||
">[CoNLL-U](https://universaldependencies.org/format.html) is revised version of the CoNLL-X format. Annotations are encoded in plain text files (UTF-8, normalized to NFC, using only the LF character as line break, including an LF character at the end of file) with three types of lines:\n",
|
||||
">- Word lines containing the annotation of a word/token in 10 fields separated by single tab characters; see below.\n",
|
||||
">- Blank lines marking sentence boundaries.\n",
|
||||
">- Comment lines starting with hash (#).\n",
|
||||
"\n",
|
||||
"This is an example of how to load a file in [CoNLL-U](https://universaldependencies.org/format.html) format. The whole file is treated as one document. The example data (`conllu.conllu`) is based on one of the standard UD/CoNLL-U examples."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "d9b2e33e",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import CoNLLULoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "5b5eec48",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = CoNLLULoader(\"example_data/conllu.conllu\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "10f3f725",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"document = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "acbb3579",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='They buy and sell books.', metadata={'source': 'example_data/conllu.conllu'})]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"document"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
},
|
||||
"toc": {
|
||||
"base_numbering": 1,
|
||||
"nav_menu": {},
|
||||
"number_sections": true,
|
||||
"sideBar": true,
|
||||
"skip_h1_title": false,
|
||||
"title_cell": "Table of Contents",
|
||||
"title_sidebar": "Contents",
|
||||
"toc_cell": false,
|
||||
"toc_position": {},
|
||||
"toc_section_display": true,
|
||||
"toc_window_display": false
|
||||
},
|
||||
"varInspector": {
|
||||
"cols": {
|
||||
"lenName": 16,
|
||||
"lenType": 16,
|
||||
"lenVar": 40
|
||||
},
|
||||
"kernels_config": {
|
||||
"python": {
|
||||
"delete_cmd_postfix": "",
|
||||
"delete_cmd_prefix": "del ",
|
||||
"library": "var_list.py",
|
||||
"varRefreshCmd": "print(var_dic_list())"
|
||||
},
|
||||
"r": {
|
||||
"delete_cmd_postfix": ") ",
|
||||
"delete_cmd_prefix": "rm(",
|
||||
"library": "var_list.r",
|
||||
"varRefreshCmd": "cat(var_dic_list()) "
|
||||
}
|
||||
},
|
||||
"types_to_exclude": [
|
||||
"module",
|
||||
"function",
|
||||
"builtin_function_or_method",
|
||||
"instance",
|
||||
"_Feature"
|
||||
],
|
||||
"window_display": false
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,102 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d9826810",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Copy Paste\n",
|
||||
"\n",
|
||||
"This notebook covers how to load a document object from something you just want to copy and paste. In this case, you don't even need to use a DocumentLoader, but rather can just construct the Document directly."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "fd9e71a2",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.docstore.document import Document"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "f40d3f30",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"text = \"..... put the text you copy pasted here......\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "d409bdba",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc = Document(page_content=text)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "cc0eff72",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Metadata\n",
|
||||
"If you want to add metadata about the where you got this piece of text, you easily can with the metadata key."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "fe3aa5aa",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"metadata = {\"source\": \"internet\", \"date\": \"Friday\"}"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "827d4e91",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"doc = Document(page_content=text, metadata=metadata)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c986a43d",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -1,129 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Cube Semantic Layer"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This notebook demonstrates the process of retrieving Cube's data model metadata in a format suitable for passing to LLMs as embeddings, thereby enhancing contextual information."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### About Cube"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"[Cube](https://cube.dev/) is the Semantic Layer for building data apps. It helps data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Cube’s data model provides structure and definitions that are used as a context for LLM to understand data and generate correct queries. LLM doesn’t need to navigate complex joins and metrics calculations because Cube abstracts those and provides a simple interface that operates on the business-level terminology, instead of SQL table and column names. This simplification helps LLM to be less error-prone and avoid hallucinations."
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Example"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"**Input arguments (mandatory)**\n",
|
||||
"\n",
|
||||
"`Cube Semantic Loader` requires 2 arguments:\n",
|
||||
"\n",
|
||||
"- `cube_api_url`: The URL of your Cube's deployment REST API. Please refer to the [Cube documentation](https://cube.dev/docs/http-api/rest#configuration-base-path) for more information on configuring the base path.\n",
|
||||
"\n",
|
||||
"- `cube_api_token`: The authentication token generated based on your Cube's API secret. Please refer to the [Cube documentation](https://cube.dev/docs/security#generating-json-web-tokens-jwt) for instructions on generating JSON Web Tokens (JWT).\n",
|
||||
"\n",
|
||||
"**Input arguments (optional)**\n",
|
||||
"\n",
|
||||
"- `load_dimension_values`: Whether to load dimension values for every string dimension or not.\n",
|
||||
"\n",
|
||||
"- `dimension_values_limit`: Maximum number of dimension values to load.\n",
|
||||
"\n",
|
||||
"- `dimension_values_max_retries`: Maximum number of retries to load dimension values.\n",
|
||||
"\n",
|
||||
"- `dimension_values_retry_delay`: Delay between retries to load dimension values."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import jwt\n",
|
||||
"from langchain.document_loaders import CubeSemanticLoader\n",
|
||||
"\n",
|
||||
"api_url = \"https://api-example.gcp-us-central1.cubecloudapp.dev/cubejs-api/v1/meta\"\n",
|
||||
"cubejs_api_secret = \"api-secret-here\"\n",
|
||||
"security_context = {}\n",
|
||||
"# Read more about security context here: https://cube.dev/docs/security\n",
|
||||
"api_token = jwt.encode(security_context, cubejs_api_secret, algorithm=\"HS256\")\n",
|
||||
"\n",
|
||||
"loader = CubeSemanticLoader(api_url, api_token)\n",
|
||||
"\n",
|
||||
"documents = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Returns a list of documents with the following attributes:\n",
|
||||
"\n",
|
||||
"- `page_content`\n",
|
||||
"- `metadata`\n",
|
||||
" - `table_name`\n",
|
||||
" - `column_name`\n",
|
||||
" - `column_data_type`\n",
|
||||
" - `column_title`\n",
|
||||
" - `column_description`\n",
|
||||
" - `column_values`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"> page_content='Users View City, None' metadata={'table_name': 'users_view', 'column_name': 'users_view.city', 'column_data_type': 'string', 'column_title': 'Users View City', 'column_description': 'None', 'column_member_type': 'dimension', 'column_values': ['Austin', 'Chicago', 'Los Angeles', 'Mountain View', 'New York', 'Palo Alto', 'San Francisco', 'Seattle']}"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"language_info": {
|
||||
"name": "python"
|
||||
},
|
||||
"orig_nbformat": 4
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
|
|
@ -1,96 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"attachments": {},
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Datadog Logs\n",
|
||||
"\n",
|
||||
">[Datadog](https://www.datadoghq.com/) is a monitoring and analytics platform for cloud-scale applications.\n",
|
||||
"\n",
|
||||
"This loader fetches the logs from your applications in Datadog using the `datadog_api_client` Python package. You must initialize the loader with your `Datadog API key` and `APP key`, and you need to pass in the query to extract the desired logs."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import DatadogLogsLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install datadog-api-client"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"query = \"service:agent status:error\"\n",
|
||||
"\n",
|
||||
"loader = DatadogLogsLoader(\n",
|
||||
" query=query,\n",
|
||||
" api_key=DD_API_KEY,\n",
|
||||
" app_key=DD_APP_KEY,\n",
|
||||
" from_time=1688732708951, # Optional, timestamp in milliseconds\n",
|
||||
" to_time=1688736308951, # Optional, timestamp in milliseconds\n",
|
||||
" limit=100, # Optional, default is 100\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='message: grep: /etc/datadog-agent/system-probe.yaml: No such file or directory', metadata={'id': 'AgAAAYkwpLImvkjRpQAAAAAAAAAYAAAAAEFZa3dwTUFsQUFEWmZfLU5QdElnM3dBWQAAACQAAAAAMDE4OTMwYTQtYzk3OS00MmJjLTlhNDAtOTY4N2EwY2I5ZDdk', 'status': 'error', 'service': 'agent', 'tags': ['accessible-from-goog-gke-node', 'allow-external-ingress-high-ports', 'allow-external-ingress-http', 'allow-external-ingress-https', 'container_id:c7d8ecd27b5b3cfdf3b0df04b8965af6f233f56b7c3c2ffabfab5e3b6ccbd6a5', 'container_name:lab_datadog_1', 'datadog.pipelines:false', 'datadog.submission_auth:private_api_key', 'docker_image:datadog/agent:7.41.1', 'env:dd101-dev', 'hostname:lab-host', 'image_name:datadog/agent', 'image_tag:7.41.1', 'instance-id:7497601202021312403', 'instance-type:custom-1-4096', 'instruqt_aws_accounts:', 'instruqt_azure_subscriptions:', 'instruqt_gcp_projects:', 'internal-hostname:lab-host.d4rjybavkary.svc.cluster.local', 'numeric_project_id:3390740675', 'p-d4rjybavkary', 'project:instruqt-prod', 'service:agent', 'short_image:agent', 'source:agent', 'zone:europe-west1-b'], 'timestamp': datetime.datetime(2023, 7, 7, 13, 57, 27, 206000, tzinfo=tzutc())}),\n",
|
||||
" Document(page_content='message: grep: /etc/datadog-agent/system-probe.yaml: No such file or directory', metadata={'id': 'AgAAAYkwpLImvkjRpgAAAAAAAAAYAAAAAEFZa3dwTUFsQUFEWmZfLU5QdElnM3dBWgAAACQAAAAAMDE4OTMwYTQtYzk3OS00MmJjLTlhNDAtOTY4N2EwY2I5ZDdk', 'status': 'error', 'service': 'agent', 'tags': ['accessible-from-goog-gke-node', 'allow-external-ingress-high-ports', 'allow-external-ingress-http', 'allow-external-ingress-https', 'container_id:c7d8ecd27b5b3cfdf3b0df04b8965af6f233f56b7c3c2ffabfab5e3b6ccbd6a5', 'container_name:lab_datadog_1', 'datadog.pipelines:false', 'datadog.submission_auth:private_api_key', 'docker_image:datadog/agent:7.41.1', 'env:dd101-dev', 'hostname:lab-host', 'image_name:datadog/agent', 'image_tag:7.41.1', 'instance-id:7497601202021312403', 'instance-type:custom-1-4096', 'instruqt_aws_accounts:', 'instruqt_azure_subscriptions:', 'instruqt_gcp_projects:', 'internal-hostname:lab-host.d4rjybavkary.svc.cluster.local', 'numeric_project_id:3390740675', 'p-d4rjybavkary', 'project:instruqt-prod', 'service:agent', 'short_image:agent', 'source:agent', 'zone:europe-west1-b'], 'timestamp': datetime.datetime(2023, 7, 7, 13, 57, 27, 206000, tzinfo=tzutc())})]"
|
||||
]
|
||||
},
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"documents = loader.load()\n",
|
||||
"documents"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": ".venv",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.11"
|
||||
},
|
||||
"orig_nbformat": 4
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 2
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -1,89 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Discord\n",
|
||||
"\n",
|
||||
">[Discord](https://discord.com/) is a VoIP and instant messaging social platform. Users have the ability to communicate with voice calls, video calls, text messaging, media and files in private chats or as part of communities called \"servers\". A server is a collection of persistent chat rooms and voice channels which can be accessed via invite links.\n",
|
||||
"\n",
|
||||
"Follow these steps to download your `Discord` data:\n",
|
||||
"\n",
|
||||
"1. Go to your **User Settings**\n",
|
||||
"2. Then go to **Privacy and Safety**\n",
|
||||
"3. Head over to the **Request all of my Data** and click on **Request Data** button\n",
|
||||
"\n",
|
||||
"It might take 30 days for you to receive your data. You'll receive an email at the address which is registered with Discord. That email will have a download button using which you would be able to download your personal Discord data."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import pandas as pd\n",
|
||||
"import os"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"path = input('Please enter the path to the contents of the Discord \"messages\" folder: ')\n",
|
||||
"li = []\n",
|
||||
"for f in os.listdir(path):\n",
|
||||
" expected_csv_path = os.path.join(path, f, \"messages.csv\")\n",
|
||||
" csv_exists = os.path.isfile(expected_csv_path)\n",
|
||||
" if csv_exists:\n",
|
||||
" df = pd.read_csv(expected_csv_path, index_col=None, header=0)\n",
|
||||
" li.append(df)\n",
|
||||
"\n",
|
||||
"df = pd.concat(li, axis=0, ignore_index=True, sort=False)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders.discord import DiscordChatLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = DiscordChatLoader(df, user_id_col=\"ID\")\n",
|
||||
"print(loader.load())"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,431 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Docugami\n",
|
||||
"This notebook covers how to load documents from `Docugami`. It provides the advantages of using this system over alternative data loaders.\n",
|
||||
"\n",
|
||||
"## Prerequisites\n",
|
||||
"1. Install necessary python packages.\n",
|
||||
"2. Grab an access token for your workspace, and make sure it is set as the `DOCUGAMI_API_KEY` environment variable.\n",
|
||||
"3. Grab some docset and document IDs for your processed documents, as described here: https://help.docugami.com/home/docugami-api"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# You need the lxml package to use the DocugamiLoader\n",
|
||||
"!pip install lxml"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Quick start\n",
|
||||
"\n",
|
||||
"1. Create a [Docugami workspace](http://www.docugami.com) (free trials available)\n",
|
||||
"2. Add your documents (PDF, DOCX or DOC) and allow Docugami to ingest and cluster them into sets of similar documents, e.g. NDAs, Lease Agreements, and Service Agreements. There is no fixed set of document types supported by the system, the clusters created depend on your particular documents, and you can [change the docset assignments](https://help.docugami.com/home/working-with-the-doc-sets-view) later.\n",
|
||||
"3. Create an access token via the Developer Playground for your workspace. [Detailed instructions](https://help.docugami.com/home/docugami-api)\n",
|
||||
"4. Explore the [Docugami API](https://api-docs.docugami.com) to get a list of your processed docset IDs, or just the document IDs for a particular docset. \n",
|
||||
"6. Use the DocugamiLoader as detailed below, to get rich semantic chunks for your documents.\n",
|
||||
"7. Optionally, build and publish one or more [reports or abstracts](https://help.docugami.com/home/reports). This helps Docugami improve the semantic XML with better tags based on your preferences, which are then added to the DocugamiLoader output as metadata. Use techniques like [self-querying retriever](/docs/modules/data_connection/retrievers/how_to/self_query_retriever/) to do high accuracy Document QA.\n",
|
||||
"\n",
|
||||
"## Advantages vs Other Chunking Techniques\n",
|
||||
"\n",
|
||||
"Appropriate chunking of your documents is critical for retrieval from documents. Many chunking techniques exist, including simple ones that rely on whitespace and recursive chunk splitting based on character length. Docugami offers a different approach:\n",
|
||||
"\n",
|
||||
"1. **Intelligent Chunking:** Docugami breaks down every document into a hierarchical semantic XML tree of chunks of varying sizes, from single words or numerical values to entire sections. These chunks follow the semantic contours of the document, providing a more meaningful representation than arbitrary length or simple whitespace-based chunking.\n",
|
||||
"2. **Structured Representation:** In addition, the XML tree indicates the structural contours of every document, using attributes denoting headings, paragraphs, lists, tables, and other common elements, and does that consistently across all supported document formats, such as scanned PDFs or DOCX files. It appropriately handles long-form document characteristics like page headers/footers or multi-column flows for clean text extraction.\n",
|
||||
"3. **Semantic Annotations:** Chunks are annotated with semantic tags that are coherent across the document set, facilitating consistent hierarchical queries across multiple documents, even if they are written and formatted differently. For example, in set of lease agreements, you can easily identify key provisions like the Landlord, Tenant, or Renewal Date, as well as more complex information such as the wording of any sub-lease provision or whether a specific jurisdiction has an exception section within a Termination Clause.\n",
|
||||
"4. **Additional Metadata:** Chunks are also annotated with additional metadata, if a user has been using Docugami. This additional metadata can be used for high-accuracy Document QA without context window restrictions. See detailed code walk-through below.\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"from langchain.document_loaders import DocugamiLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Load Documents\n",
|
||||
"\n",
|
||||
"If the DOCUGAMI_API_KEY environment variable is set, there is no need to pass it in to the loader explicitly otherwise you can pass it in as the `access_token` parameter."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='MUTUAL NON-DISCLOSURE AGREEMENT This Mutual Non-Disclosure Agreement (this “ Agreement ”) is entered into and made effective as of April 4 , 2018 between Docugami Inc. , a Delaware corporation , whose address is 150 Lake Street South , Suite 221 , Kirkland , Washington 98033 , and Caleb Divine , an individual, whose address is 1201 Rt 300 , Newburgh NY 12550 .', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:ThisMutualNon-disclosureAgreement', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'p', 'tag': 'ThisMutualNon-disclosureAgreement'}),\n",
|
||||
" Document(page_content='The above named parties desire to engage in discussions regarding a potential agreement or other transaction between the parties (the “Purpose”). In connection with such discussions, it may be necessary for the parties to disclose to each other certain confidential information or materials to enable them to evaluate whether to enter into such agreement or transaction.', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Discussions', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'p', 'tag': 'Discussions'}),\n",
|
||||
" Document(page_content='In consideration of the foregoing, the parties agree as follows:', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Consideration', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'p', 'tag': 'Consideration'}),\n",
|
||||
" Document(page_content='1. Confidential Information . For purposes of this Agreement , “ Confidential Information ” means any information or materials disclosed by one party to the other party that: (i) if disclosed in writing or in the form of tangible materials, is marked “confidential” or “proprietary” at the time of such disclosure; (ii) if disclosed orally or by visual presentation, is identified as “confidential” or “proprietary” at the time of such disclosure, and is summarized in a writing sent by the disclosing party to the receiving party within thirty ( 30 ) days after any such disclosure; or (iii) due to its nature or the circumstances of its disclosure, a person exercising reasonable business judgment would understand to be confidential or proprietary.', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:Purposes/docset:ConfidentialInformation-section/docset:ConfidentialInformation[2]', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'div', 'tag': 'ConfidentialInformation'}),\n",
|
||||
" Document(page_content=\"2. Obligations and Restrictions . Each party agrees: (i) to maintain the other party's Confidential Information in strict confidence; (ii) not to disclose such Confidential Information to any third party; and (iii) not to use such Confidential Information for any purpose except for the Purpose. Each party may disclose the other party’s Confidential Information to its employees and consultants who have a bona fide need to know such Confidential Information for the Purpose, but solely to the extent necessary to pursue the Purpose and for no other purpose; provided, that each such employee and consultant first executes a written agreement (or is otherwise already bound by a written agreement) that contains use and nondisclosure restrictions at least as protective of the other party’s Confidential Information as those set forth in this Agreement .\", metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:Obligations/docset:ObligationsAndRestrictions-section/docset:ObligationsAndRestrictions', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'div', 'tag': 'ObligationsAndRestrictions'}),\n",
|
||||
" Document(page_content='3. Exceptions. The obligations and restrictions in Section 2 will not apply to any information or materials that:', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:Exceptions/docset:Exceptions-section/docset:Exceptions[2]', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'div', 'tag': 'Exceptions'}),\n",
|
||||
" Document(page_content='(i) were, at the date of disclosure, or have subsequently become, generally known or available to the public through no act or failure to act by the receiving party;', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:TheDate/docset:TheDate/docset:TheDate', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'p', 'tag': 'TheDate'}),\n",
|
||||
" Document(page_content='(ii) were rightfully known by the receiving party prior to receiving such information or materials from the disclosing party;', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:TheDate/docset:SuchInformation/docset:TheReceivingParty', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'p', 'tag': 'TheReceivingParty'}),\n",
|
||||
" Document(page_content='(iii) are rightfully acquired by the receiving party from a third party who has the right to disclose such information or materials without breach of any confidentiality obligation to the disclosing party;', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:TheDate/docset:TheReceivingParty/docset:TheReceivingParty', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'p', 'tag': 'TheReceivingParty'}),\n",
|
||||
" Document(page_content='4. Compelled Disclosure . Nothing in this Agreement will be deemed to restrict a party from disclosing the other party’s Confidential Information to the extent required by any order, subpoena, law, statute or regulation; provided, that the party required to make such a disclosure uses reasonable efforts to give the other party reasonable advance notice of such required disclosure in order to enable the other party to prevent or limit such disclosure.', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:Disclosure/docset:CompelledDisclosure-section/docset:CompelledDisclosure', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'div', 'tag': 'CompelledDisclosure'}),\n",
|
||||
" Document(page_content='5. Return of Confidential Information . Upon the completion or abandonment of the Purpose, and in any event upon the disclosing party’s request, the receiving party will promptly return to the disclosing party all tangible items and embodiments containing or consisting of the disclosing party’s Confidential Information and all copies thereof (including electronic copies), and any notes, analyses, compilations, studies, interpretations, memoranda or other documents (regardless of the form thereof) prepared by or on behalf of the receiving party that contain or are based upon the disclosing party’s Confidential Information .', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:TheCompletion/docset:ReturnofConfidentialInformation-section/docset:ReturnofConfidentialInformation', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'div', 'tag': 'ReturnofConfidentialInformation'}),\n",
|
||||
" Document(page_content='6. No Obligations . Each party retains the right to determine whether to disclose any Confidential Information to the other party.', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:NoObligations/docset:NoObligations-section/docset:NoObligations[2]', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'div', 'tag': 'NoObligations'}),\n",
|
||||
" Document(page_content='7. No Warranty. ALL CONFIDENTIAL INFORMATION IS PROVIDED BY THE DISCLOSING PARTY “AS IS ”.', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:NoWarranty/docset:NoWarranty-section/docset:NoWarranty[2]', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'div', 'tag': 'NoWarranty'}),\n",
|
||||
" Document(page_content='8. Term. This Agreement will remain in effect for a period of seven ( 7 ) years from the date of last disclosure of Confidential Information by either party, at which time it will terminate.', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:ThisAgreement/docset:Term-section/docset:Term', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'div', 'tag': 'Term'}),\n",
|
||||
" Document(page_content='9. Equitable Relief . Each party acknowledges that the unauthorized use or disclosure of the disclosing party’s Confidential Information may cause the disclosing party to incur irreparable harm and significant damages, the degree of which may be difficult to ascertain. Accordingly, each party agrees that the disclosing party will have the right to seek immediate equitable relief to enjoin any unauthorized use or disclosure of its Confidential Information , in addition to any other rights and remedies that it may have at law or otherwise.', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:EquitableRelief/docset:EquitableRelief-section/docset:EquitableRelief[2]', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'div', 'tag': 'EquitableRelief'}),\n",
|
||||
" Document(page_content='10. Non-compete. To the maximum extent permitted by applicable law, during the Term of this Agreement and for a period of one ( 1 ) year thereafter, Caleb Divine may not market software products or do business that directly or indirectly competes with Docugami software products .', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:TheMaximumExtent/docset:Non-compete-section/docset:Non-compete', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'div', 'tag': 'Non-compete'}),\n",
|
||||
" Document(page_content='11. Miscellaneous. This Agreement will be governed and construed in accordance with the laws of the State of Washington , excluding its body of law controlling conflict of laws. This Agreement is the complete and exclusive understanding and agreement between the parties regarding the subject matter of this Agreement and supersedes all prior agreements, understandings and communications, oral or written, between the parties regarding the subject matter of this Agreement . If any provision of this Agreement is held invalid or unenforceable by a court of competent jurisdiction, that provision of this Agreement will be enforced to the maximum extent permissible and the other provisions of this Agreement will remain in full force and effect. Neither party may assign this Agreement , in whole or in part, by operation of law or otherwise, without the other party’s prior written consent, and any attempted assignment without such consent will be void. This Agreement may be executed in counterparts, each of which will be deemed an original, but all of which together will constitute one and the same instrument.', metadata={'xpath': '/docset:MutualNon-disclosure/docset:MutualNon-disclosure/docset:MUTUALNON-DISCLOSUREAGREEMENT-section/docset:MUTUALNON-DISCLOSUREAGREEMENT/docset:Consideration/docset:Purposes/docset:Accordance/docset:Miscellaneous-section/docset:Miscellaneous', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'div', 'tag': 'Miscellaneous'}),\n",
|
||||
" Document(page_content='[SIGNATURE PAGE FOLLOWS] IN WITNESS WHEREOF, the parties hereto have executed this Mutual Non-Disclosure Agreement by their duly authorized officers or representatives as of the date first set forth above.', metadata={'xpath': '/docset:MutualNon-disclosure/docset:Witness/docset:TheParties/docset:TheParties', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': 'p', 'tag': 'TheParties'}),\n",
|
||||
" Document(page_content='DOCUGAMI INC . : \\n\\n Caleb Divine : \\n\\n Signature: Signature: Name: \\n\\n Jean Paoli Name: Title: \\n\\n CEO Title:', metadata={'xpath': '/docset:MutualNon-disclosure/docset:Witness/docset:TheParties/docset:DocugamiInc/docset:DocugamiInc/xhtml:table', 'id': '43rj0ds7s0ur', 'name': 'NDA simple layout.docx', 'structure': '', 'tag': 'table'})]"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"DOCUGAMI_API_KEY = os.environ.get(\"DOCUGAMI_API_KEY\")\n",
|
||||
"\n",
|
||||
"# To load all docs in the given docset ID, just don't provide document_ids\n",
|
||||
"loader = DocugamiLoader(docset_id=\"ecxqpipcoe2p\", document_ids=[\"43rj0ds7s0ur\"])\n",
|
||||
"docs = loader.load()\n",
|
||||
"docs"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The `metadata` for each `Document` (really, a chunk of an actual PDF, DOC or DOCX) contains some useful additional information:\n",
|
||||
"\n",
|
||||
"1. **id and name:** ID and Name of the file (PDF, DOC or DOCX) the chunk is sourced from within Docugami.\n",
|
||||
"2. **xpath:** XPath inside the XML representation of the document, for the chunk. Useful for source citations directly to the actual chunk inside the document XML.\n",
|
||||
"3. **structure:** Structural attributes of the chunk, e.g. h1, h2, div, table, td, etc. Useful to filter out certain kinds of chunks if needed by the caller.\n",
|
||||
"4. **tag:** Semantic tag for the chunk, using various generative and extractive techniques. More details here: https://github.com/docugami/DFM-benchmarks"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Basic Use: Docugami Loader for Document QA\n",
|
||||
"\n",
|
||||
"You can use the Docugami Loader like a standard loader for Document QA over multiple docs, albeit with much better chunks that follow the natural contours of the document. There are many great tutorials on how to do this, e.g. [this one](https://www.youtube.com/watch?v=3yPBVii7Ct0). We can just use the same code, but use the `DocugamiLoader` for better chunking, instead of loading text or PDF files directly with basic splitting techniques."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!poetry run pip -q install openai tiktoken chromadb"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.schema import Document\n",
|
||||
"from langchain.vectorstores import Chroma\n",
|
||||
"from langchain.embeddings import OpenAIEmbeddings\n",
|
||||
"from langchain.llms import OpenAI\n",
|
||||
"from langchain.chains import RetrievalQA\n",
|
||||
"\n",
|
||||
"# For this example, we already have a processed docset for a set of lease documents\n",
|
||||
"loader = DocugamiLoader(docset_id=\"wh2kned25uqm\")\n",
|
||||
"documents = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"The documents returned by the loader are already split, so we don't need to use a text splitter. Optionally, we can use the metadata on each document, for example the structure or tag attributes, to do any post-processing we want.\n",
|
||||
"\n",
|
||||
"We will just use the output of the `DocugamiLoader` as-is to set up a retrieval QA chain the usual way."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Using embedded DuckDB without persistence: data will be transient\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"embedding = OpenAIEmbeddings()\n",
|
||||
"vectordb = Chroma.from_documents(documents=documents, embedding=embedding)\n",
|
||||
"retriever = vectordb.as_retriever()\n",
|
||||
"qa_chain = RetrievalQA.from_chain_type(\n",
|
||||
" llm=OpenAI(), chain_type=\"stuff\", retriever=retriever, return_source_documents=True\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'query': 'What can tenants do with signage on their properties?',\n",
|
||||
" 'result': ' Tenants may place signs (digital or otherwise) or other form of identification on the premises after receiving written permission from the landlord which shall not be unreasonably withheld. The tenant is responsible for any damage caused to the premises and must conform to any applicable laws, ordinances, etc. governing the same. The tenant must also remove and clean any window or glass identification promptly upon vacating the premises.',\n",
|
||||
" 'source_documents': [Document(page_content='ARTICLE VI SIGNAGE 6.01 Signage . Tenant may place or attach to the Premises signs (digital or otherwise) or other such identification as needed after receiving written permission from the Landlord , which permission shall not be unreasonably withheld. Any damage caused to the Premises by the Tenant ’s erecting or removing such signs shall be repaired promptly by the Tenant at the Tenant ’s expense . Any signs or other form of identification allowed must conform to all applicable laws, ordinances, etc. governing the same. Tenant also agrees to have any window or glass identification completely removed and cleaned at its expense promptly upon vacating the Premises.', metadata={'xpath': '/docset:OFFICELEASEAGREEMENT-section/docset:OFFICELEASEAGREEMENT/docset:Article/docset:ARTICLEVISIGNAGE-section/docset:_601Signage-section/docset:_601Signage', 'id': 'v1bvgaozfkak', 'name': 'TruTone Lane 2.docx', 'structure': 'div', 'tag': '_601Signage', 'Landlord': 'BUBBA CENTER PARTNERSHIP', 'Tenant': 'Truetone Lane LLC'}),\n",
|
||||
" Document(page_content='Signage. Tenant may place or attach to the Premises signs (digital or otherwise) or other such identification as needed after receiving written permission from the Landlord , which permission shall not be unreasonably withheld. Any damage caused to the Premises by the Tenant ’s erecting or removing such signs shall be repaired promptly by the Tenant at the Tenant ’s expense . Any signs or other form of identification allowed must conform to all applicable laws, ordinances, etc. governing the same. Tenant also agrees to have any window or glass identification completely removed and cleaned at its expense promptly upon vacating the Premises. \\n\\n ARTICLE VII UTILITIES 7.01', metadata={'xpath': '/docset:OFFICELEASEAGREEMENT-section/docset:OFFICELEASEAGREEMENT/docset:ThisOFFICELEASEAGREEMENTThis/docset:ArticleIBasic/docset:ArticleIiiUseAndCareOf/docset:ARTICLEIIIUSEANDCAREOFPREMISES-section/docset:ARTICLEIIIUSEANDCAREOFPREMISES/docset:NoOtherPurposes/docset:TenantsResponsibility/dg:chunk', 'id': 'g2fvhekmltza', 'name': 'TruTone Lane 6.pdf', 'structure': 'lim', 'tag': 'chunk', 'Landlord': 'GLORY ROAD LLC', 'Tenant': 'Truetone Lane LLC'}),\n",
|
||||
" Document(page_content='Landlord , its agents, servants, employees, licensees, invitees, and contractors during the last year of the term of this Lease at any and all times during regular business hours, after 24 hour notice to tenant, to pass and repass on and through the Premises, or such portion thereof as may be necessary, in order that they or any of them may gain access to the Premises for the purpose of showing the Premises to potential new tenants or real estate brokers. In addition, Landlord shall be entitled to place a \"FOR RENT \" or \"FOR LEASE\" sign (not exceeding 8.5 ” x 11 ”) in the front window of the Premises during the last six months of the term of this Lease .', metadata={'xpath': '/docset:Rider/docset:RIDERTOLEASE-section/docset:RIDERTOLEASE/docset:FixedRent/docset:TermYearPeriod/docset:Lease/docset:_42FLandlordSAccess-section/docset:_42FLandlordSAccess/docset:LandlordsRights/docset:Landlord', 'id': 'omvs4mysdk6b', 'name': 'TruTone Lane 1.docx', 'structure': 'p', 'tag': 'Landlord', 'Landlord': 'BIRCH STREET , LLC', 'Tenant': 'Trutone Lane LLC'}),\n",
|
||||
" Document(page_content=\"24. SIGNS . No signage shall be placed by Tenant on any portion of the Project . However, Tenant shall be permitted to place a sign bearing its name in a location approved by Landlord near the entrance to the Premises (at Tenant's cost ) and will be furnished a single listing of its name in the Building's directory (at Landlord 's cost ), all in accordance with the criteria adopted from time to time by Landlord for the Project . Any changes or additional listings in the directory shall be furnished (subject to availability of space) for the then Building Standard charge .\", metadata={'xpath': '/docset:OFFICELEASE-section/docset:OFFICELEASE/docset:THISOFFICELEASE/docset:WITNESSETH-section/docset:WITNESSETH/docset:GrossRentCreditTheRentCredit-section/docset:GrossRentCreditTheRentCredit/docset:Period/docset:ApplicableSalesTax/docset:PercentageRent/docset:TheTerms/docset:Indemnification/docset:INDEMNIFICATION-section/docset:INDEMNIFICATION/docset:Waiver/docset:Waiver/docset:Signs/docset:SIGNS-section/docset:SIGNS', 'id': 'qkn9cyqsiuch', 'name': 'Shorebucks LLC_AZ.pdf', 'structure': 'div', 'tag': 'SIGNS', 'Landlord': 'Menlo Group', 'Tenant': 'Shorebucks LLC'})]}"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Try out the retriever with an example query\n",
|
||||
"qa_chain(\"What can tenants do with signage on their properties?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Using Docugami to Add Metadata to Chunks for High Accuracy Document QA\n",
|
||||
"\n",
|
||||
"One issue with large documents is that the correct answer to your question may depend on chunks that are far apart in the document. Typical chunking techniques, even with overlap, will struggle with providing the LLM sufficent context to answer such questions. With upcoming very large context LLMs, it may be possible to stuff a lot of tokens, perhaps even entire documents, inside the context but this will still hit limits at some point with very long documents, or a lot of documents.\n",
|
||||
"\n",
|
||||
"For example, if we ask a more complex question that requires the LLM to draw on chunks from different parts of the document, even OpenAI's powerful LLM is unable to answer correctly."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"' 9,753 square feet'"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chain_response = qa_chain(\"What is rentable area for the property owned by DHA Group?\")\n",
|
||||
"chain_response[\"result\"] # the correct answer should be 13,500"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"At first glance the answer may seem reasonable, but if you review the source chunks carefully for this answer, you will see that the chunking of the document did not end up putting the Landlord name and the rentable area in the same context, since they are far apart in the document. The retriever therefore ends up finding unrelated chunks from other documents not even related to the **Menlo Group** landlord. That landlord happens to be mentioned on the first page of the file **Shorebucks LLC_NJ.pdf** file, and while one of the source chunks used by the chain is indeed from that doc that contains the correct answer (**13,500**), other source chunks from different docs are included, and the answer is therefore incorrect."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='1.1 Landlord . DHA Group , a Delaware limited liability company authorized to transact business in New Jersey .', metadata={'xpath': '/docset:OFFICELEASE-section/docset:OFFICELEASE/docset:THISOFFICELEASE/docset:WITNESSETH-section/docset:WITNESSETH/docset:TheTerms/dg:chunk/docset:BasicLeaseInformation/docset:BASICLEASEINFORMATIONANDDEFINEDTERMS-section/docset:BASICLEASEINFORMATIONANDDEFINEDTERMS/docset:DhaGroup/docset:DhaGroup/docset:DhaGroup/docset:Landlord-section/docset:DhaGroup', 'id': 'md8rieecquyv', 'name': 'Shorebucks LLC_NJ.pdf', 'structure': 'div', 'tag': 'DhaGroup', 'Landlord': 'DHA Group', 'Tenant': 'Shorebucks LLC'}),\n",
|
||||
" Document(page_content='WITNESSES: LANDLORD: DHA Group , a Delaware limited liability company', metadata={'xpath': '/docset:OFFICELEASE-section/docset:OFFICELEASE/docset:THISOFFICELEASE/docset:WITNESSETH-section/docset:WITNESSETH/docset:GrossRentCreditTheRentCredit-section/docset:GrossRentCreditTheRentCredit/docset:Guaranty-section/docset:Guaranty[2]/docset:SIGNATURESONNEXTPAGE-section/docset:INWITNESSWHEREOF-section/docset:INWITNESSWHEREOF/docset:Behalf/docset:Witnesses/xhtml:table/xhtml:tbody/xhtml:tr[3]/xhtml:td[2]/docset:DhaGroup', 'id': 'md8rieecquyv', 'name': 'Shorebucks LLC_NJ.pdf', 'structure': 'p', 'tag': 'DhaGroup', 'Landlord': 'DHA Group', 'Tenant': 'Shorebucks LLC'}),\n",
|
||||
" Document(page_content=\"1.16 Landlord 's Notice Address . DHA Group , Suite 1010 , 111 Bauer Dr , Oakland , New Jersey , 07436 , with a copy to the Building Management Office at the Project , Attention: On - Site Property Manager .\", metadata={'xpath': '/docset:OFFICELEASE-section/docset:OFFICELEASE/docset:THISOFFICELEASE/docset:WITNESSETH-section/docset:WITNESSETH/docset:GrossRentCreditTheRentCredit-section/docset:GrossRentCreditTheRentCredit/docset:Period/docset:ApplicableSalesTax/docset:PercentageRent/docset:PercentageRent/docset:NoticeAddress[2]/docset:LandlordsNoticeAddress-section/docset:LandlordsNoticeAddress[2]', 'id': 'md8rieecquyv', 'name': 'Shorebucks LLC_NJ.pdf', 'structure': 'div', 'tag': 'LandlordsNoticeAddress', 'Landlord': 'DHA Group', 'Tenant': 'Shorebucks LLC'}),\n",
|
||||
" Document(page_content='1.6 Rentable Area of the Premises. 9,753 square feet . This square footage figure includes an add-on factor for Common Areas in the Building and has been agreed upon by the parties as final and correct and is not subject to challenge or dispute by either party.', metadata={'xpath': '/docset:OFFICELEASE-section/docset:OFFICELEASE/docset:THISOFFICELEASE/docset:WITNESSETH-section/docset:WITNESSETH/docset:TheTerms/dg:chunk/docset:BasicLeaseInformation/docset:BASICLEASEINFORMATIONANDDEFINEDTERMS-section/docset:BASICLEASEINFORMATIONANDDEFINEDTERMS/docset:PerryBlair/docset:PerryBlair/docset:Premises[2]/docset:RentableAreaofthePremises-section/docset:RentableAreaofthePremises', 'id': 'dsyfhh4vpeyf', 'name': 'Shorebucks LLC_CO.pdf', 'structure': 'div', 'tag': 'RentableAreaofthePremises', 'Landlord': 'Perry & Blair LLC', 'Tenant': 'Shorebucks LLC'})]"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"chain_response[\"source_documents\"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Docugami can help here. Chunks are annotated with additional metadata created using different techniques if a user has been [using Docugami](https://help.docugami.com/home/reports). More technical approaches will be added later.\n",
|
||||
"\n",
|
||||
"Specifically, let's look at the additional metadata that is returned on the documents returned by docugami, in the form of some simple key/value pairs on all the text chunks:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'xpath': '/docset:OFFICELEASEAGREEMENT-section/docset:OFFICELEASEAGREEMENT/docset:ThisOfficeLeaseAgreement',\n",
|
||||
" 'id': 'v1bvgaozfkak',\n",
|
||||
" 'name': 'TruTone Lane 2.docx',\n",
|
||||
" 'structure': 'p',\n",
|
||||
" 'tag': 'ThisOfficeLeaseAgreement',\n",
|
||||
" 'Landlord': 'BUBBA CENTER PARTNERSHIP',\n",
|
||||
" 'Tenant': 'Truetone Lane LLC'}"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"loader = DocugamiLoader(docset_id=\"wh2kned25uqm\")\n",
|
||||
"documents = loader.load()\n",
|
||||
"documents[0].metadata"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We can use a [self-querying retriever](/docs/modules/data_connection/retrievers/how_to/self_query/) to improve our query accuracy, using this additional metadata:"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Using embedded DuckDB without persistence: data will be transient\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.chains.query_constructor.schema import AttributeInfo\n",
|
||||
"from langchain.retrievers.self_query.base import SelfQueryRetriever\n",
|
||||
"\n",
|
||||
"EXCLUDE_KEYS = [\"id\", \"xpath\", \"structure\"]\n",
|
||||
"metadata_field_info = [\n",
|
||||
" AttributeInfo(\n",
|
||||
" name=key,\n",
|
||||
" description=f\"The {key} for this chunk\",\n",
|
||||
" type=\"string\",\n",
|
||||
" )\n",
|
||||
" for key in documents[0].metadata\n",
|
||||
" if key.lower() not in EXCLUDE_KEYS\n",
|
||||
"]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"document_content_description = \"Contents of this chunk\"\n",
|
||||
"llm = OpenAI(temperature=0)\n",
|
||||
"vectordb = Chroma.from_documents(documents=documents, embedding=embedding)\n",
|
||||
"retriever = SelfQueryRetriever.from_llm(\n",
|
||||
" llm, vectordb, document_content_description, metadata_field_info, verbose=True\n",
|
||||
")\n",
|
||||
"qa_chain = RetrievalQA.from_chain_type(\n",
|
||||
" llm=OpenAI(), chain_type=\"stuff\", retriever=retriever, return_source_documents=True\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Let's run the same question again. It returns the correct result since all the chunks have metadata key/value pairs on them carrying key information about the document even if this information is physically very far away from the source chunk used to generate the answer."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"query='rentable area' filter=Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='Landlord', value='DHA Group')\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"{'query': 'What is rentable area for the property owned by DHA Group?',\n",
|
||||
" 'result': ' 13,500 square feet.',\n",
|
||||
" 'source_documents': [Document(page_content='1.1 Landlord . DHA Group , a Delaware limited liability company authorized to transact business in New Jersey .', metadata={'xpath': '/docset:OFFICELEASE-section/docset:OFFICELEASE/docset:THISOFFICELEASE/docset:WITNESSETH-section/docset:WITNESSETH/docset:TheTerms/dg:chunk/docset:BasicLeaseInformation/docset:BASICLEASEINFORMATIONANDDEFINEDTERMS-section/docset:BASICLEASEINFORMATIONANDDEFINEDTERMS/docset:DhaGroup/docset:DhaGroup/docset:DhaGroup/docset:Landlord-section/docset:DhaGroup', 'id': 'md8rieecquyv', 'name': 'Shorebucks LLC_NJ.pdf', 'structure': 'div', 'tag': 'DhaGroup', 'Landlord': 'DHA Group', 'Tenant': 'Shorebucks LLC'}),\n",
|
||||
" Document(page_content='WITNESSES: LANDLORD: DHA Group , a Delaware limited liability company', metadata={'xpath': '/docset:OFFICELEASE-section/docset:OFFICELEASE/docset:THISOFFICELEASE/docset:WITNESSETH-section/docset:WITNESSETH/docset:GrossRentCreditTheRentCredit-section/docset:GrossRentCreditTheRentCredit/docset:Guaranty-section/docset:Guaranty[2]/docset:SIGNATURESONNEXTPAGE-section/docset:INWITNESSWHEREOF-section/docset:INWITNESSWHEREOF/docset:Behalf/docset:Witnesses/xhtml:table/xhtml:tbody/xhtml:tr[3]/xhtml:td[2]/docset:DhaGroup', 'id': 'md8rieecquyv', 'name': 'Shorebucks LLC_NJ.pdf', 'structure': 'p', 'tag': 'DhaGroup', 'Landlord': 'DHA Group', 'Tenant': 'Shorebucks LLC'}),\n",
|
||||
" Document(page_content=\"1.16 Landlord 's Notice Address . DHA Group , Suite 1010 , 111 Bauer Dr , Oakland , New Jersey , 07436 , with a copy to the Building Management Office at the Project , Attention: On - Site Property Manager .\", metadata={'xpath': '/docset:OFFICELEASE-section/docset:OFFICELEASE/docset:THISOFFICELEASE/docset:WITNESSETH-section/docset:WITNESSETH/docset:GrossRentCreditTheRentCredit-section/docset:GrossRentCreditTheRentCredit/docset:Period/docset:ApplicableSalesTax/docset:PercentageRent/docset:PercentageRent/docset:NoticeAddress[2]/docset:LandlordsNoticeAddress-section/docset:LandlordsNoticeAddress[2]', 'id': 'md8rieecquyv', 'name': 'Shorebucks LLC_NJ.pdf', 'structure': 'div', 'tag': 'LandlordsNoticeAddress', 'Landlord': 'DHA Group', 'Tenant': 'Shorebucks LLC'}),\n",
|
||||
" Document(page_content='1.6 Rentable Area of the Premises. 13,500 square feet . This square footage figure includes an add-on factor for Common Areas in the Building and has been agreed upon by the parties as final and correct and is not subject to challenge or dispute by either party.', metadata={'xpath': '/docset:OFFICELEASE-section/docset:OFFICELEASE/docset:THISOFFICELEASE/docset:WITNESSETH-section/docset:WITNESSETH/docset:TheTerms/dg:chunk/docset:BasicLeaseInformation/docset:BASICLEASEINFORMATIONANDDEFINEDTERMS-section/docset:BASICLEASEINFORMATIONANDDEFINEDTERMS/docset:DhaGroup/docset:DhaGroup/docset:Premises[2]/docset:RentableAreaofthePremises-section/docset:RentableAreaofthePremises', 'id': 'md8rieecquyv', 'name': 'Shorebucks LLC_NJ.pdf', 'structure': 'div', 'tag': 'RentableAreaofthePremises', 'Landlord': 'DHA Group', 'Tenant': 'Shorebucks LLC'})]}"
|
||||
]
|
||||
},
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"qa_chain(\"What is rentable area for the property owned by DHA Group?\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This time the answer is correct, since the self-querying retriever created a filter on the landlord attribute of the metadata, correctly filtering to document that specifically is about the DHA Group landlord. The resulting source chunks are all relevant to this landlord, and this improves answer accuracy even though the landlord is not directly mentioned in the specific chunk that contains the correct answer."
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.11.3"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -1,196 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# DuckDB\n",
|
||||
"\n",
|
||||
">[DuckDB](https://duckdb.org/) is an in-process SQL OLAP database management system.\n",
|
||||
"\n",
|
||||
"Load a `DuckDB` query with one document per row."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install duckdb"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import DuckDBLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Writing example.csv\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"%%file example.csv\n",
|
||||
"Team,Payroll\n",
|
||||
"Nationals,81.34\n",
|
||||
"Reds,82.20"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = DuckDBLoader(\"SELECT * FROM read_csv_auto('example.csv')\")\n",
|
||||
"\n",
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[Document(page_content='Team: Nationals\\nPayroll: 81.34', metadata={}), Document(page_content='Team: Reds\\nPayroll: 82.2', metadata={})]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(data)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Specifying Which Columns are Content vs Metadata"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = DuckDBLoader(\n",
|
||||
" \"SELECT * FROM read_csv_auto('example.csv')\",\n",
|
||||
" page_content_columns=[\"Team\"],\n",
|
||||
" metadata_columns=[\"Payroll\"],\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[Document(page_content='Team: Nationals', metadata={'Payroll': 81.34}), Document(page_content='Team: Reds', metadata={'Payroll': 82.2})]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(data)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Adding Source to Metadata"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = DuckDBLoader(\n",
|
||||
" \"SELECT Team, Payroll, Team As source FROM read_csv_auto('example.csv')\",\n",
|
||||
" metadata_columns=[\"source\"],\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"[Document(page_content='Team: Nationals\\nPayroll: 81.34\\nsource: Nationals', metadata={'source': 'Nationals'}), Document(page_content='Team: Reds\\nPayroll: 82.2\\nsource: Reds', metadata={'source': 'Reds'})]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(data)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
|
|
@ -1,297 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9fdbd55d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Email\n",
|
||||
"\n",
|
||||
"This notebook shows how to load email (`.eml`) or `Microsoft Outlook` (`.msg`) files."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "89caa348",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Using Unstructured"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "226e50aa-407d-43d9-a81d-f6706298b10c",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install unstructured"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "40cd9806",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import UnstructuredEmailLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "2d20b852",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = UnstructuredEmailLoader(\"example_data/fake-email.eml\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "579fa702",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "90c1d899",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='This is a test email to use for unit tests.\\n\\nImportant points:\\n\\nRoses are red\\n\\nViolets are blue', metadata={'source': 'example_data/fake-email.eml'})]"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"data"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "8bf50cba",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Retain Elements\n",
|
||||
"\n",
|
||||
"Under the hood, Unstructured creates different \"elements\" for different chunks of text. By default we combine those together, but you can easily keep that separation by specifying `mode=\"elements\"`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "b9592eaf",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = UnstructuredEmailLoader(\"example_data/fake-email.eml\", mode=\"elements\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "0b16d03f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "d7bdc5e5",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"Document(page_content='This is a test email to use for unit tests.', metadata={'source': 'example_data/fake-email.eml', 'filename': 'fake-email.eml', 'file_directory': 'example_data', 'date': '2022-12-16T17:04:16-05:00', 'filetype': 'message/rfc822', 'sent_from': ['Matthew Robinson <mrobinson@unstructured.io>'], 'sent_to': ['Matthew Robinson <mrobinson@unstructured.io>'], 'subject': 'Test Email', 'category': 'NarrativeText'})"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"data[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "5021f20a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Processing Attachments\n",
|
||||
"\n",
|
||||
"You can process attachments with `UnstructuredEmailLoader` by setting `process_attachments=True` in the constructor. By default, attachments will be partitioned using the `partition` function from `unstructured`. You can use a different partitioning function by passing the function to the `attachment_partitioner` kwarg."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "6539f166",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = UnstructuredEmailLoader(\n",
|
||||
" \"example_data/fake-email.eml\",\n",
|
||||
" mode=\"elements\",\n",
|
||||
" process_attachments=True,\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "aebead38",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "ddeb60f4",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"Document(page_content='This is a test email to use for unit tests.', metadata={'source': 'example_data/fake-email.eml', 'filename': 'fake-email.eml', 'file_directory': 'example_data', 'date': '2022-12-16T17:04:16-05:00', 'filetype': 'message/rfc822', 'sent_from': ['Matthew Robinson <mrobinson@unstructured.io>'], 'sent_to': ['Matthew Robinson <mrobinson@unstructured.io>'], 'subject': 'Test Email', 'category': 'NarrativeText'})"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"data[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "6a074515",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Using OutlookMessageLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "058e670e-9964-44ee-b888-44f23ffb9310",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install extract_msg"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "1e7a8444",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import OutlookMessageLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "77a055e6",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = OutlookMessageLoader(\"example_data/fake-email.msg\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "789882de",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "46aa0632",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"Document(page_content='This is a test email to experiment with the MS Outlook MSG Extractor\\r\\n\\r\\n\\r\\n-- \\r\\n\\r\\n\\r\\nKind regards\\r\\n\\r\\n\\r\\n\\r\\n\\r\\nBrian Zhou\\r\\n\\r\\n', metadata={'subject': 'Test for TIF files', 'sender': 'Brian Zhou <brizhou@gmail.com>', 'date': 'Mon, 18 Nov 2013 16:26:24 +0800'})"
|
||||
]
|
||||
},
|
||||
"execution_count": 11,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"data[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "2b223ce2",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.8.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,167 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"# Embaas\n",
|
||||
"[embaas](https://embaas.io) is a fully managed NLP API service that offers features like embedding generation, document text extraction, document to embeddings and more. You can choose a [variety of pre-trained models](https://embaas.io/docs/models/embeddings).\n",
|
||||
"\n",
|
||||
"### Prerequisites\n",
|
||||
"Create a free embaas account at [https://embaas.io/register](https://embaas.io/register) and generate an [API key](https://embaas.io/dashboard/api-keys)\n",
|
||||
"\n",
|
||||
"### Document Text Extraction API\n",
|
||||
"The document text extraction API allows you to extract the text from a given document. The API supports a variety of document formats, including PDF, mp3, mp4 and more. For a full list of supported formats, check out the API docs (link below)."
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Set API key\n",
|
||||
"embaas_api_key = \"YOUR_API_KEY\"\n",
|
||||
"# or set environment variable\n",
|
||||
"os.environ[\"EMBAAS_API_KEY\"] = \"YOUR_API_KEY\""
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"#### Using a blob (bytes)"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders.embaas import EmbaasBlobLoader\n",
|
||||
"from langchain.document_loaders.blob_loaders import Blob"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"blob_loader = EmbaasBlobLoader()\n",
|
||||
"blob = Blob.from_path(\"example.pdf\")\n",
|
||||
"documents = blob_loader.load(blob)"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# You can also directly create embeddings with your preferred embeddings model\n",
|
||||
"blob_loader = EmbaasBlobLoader(params={\"model\": \"e5-large-v2\", \"should_embed\": True})\n",
|
||||
"blob = Blob.from_path(\"example.pdf\")\n",
|
||||
"documents = blob_loader.load(blob)\n",
|
||||
"\n",
|
||||
"print(documents[0][\"metadata\"][\"embedding\"])"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"ExecuteTime": {
|
||||
"start_time": "2023-06-12T22:19:48.366886Z",
|
||||
"end_time": "2023-06-12T22:19:48.380467Z"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"#### Using a file"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders.embaas import EmbaasLoader"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"file_loader = EmbaasLoader(file_path=\"example.pdf\")\n",
|
||||
"documents = file_loader.load()"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Disable automatic text splitting\n",
|
||||
"file_loader = EmbaasLoader(file_path=\"example.mp3\", params={\"should_chunk\": False})\n",
|
||||
"documents = file_loader.load()"
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false,
|
||||
"ExecuteTime": {
|
||||
"start_time": "2023-06-12T22:24:31.880857Z",
|
||||
"end_time": "2023-06-12T22:24:31.894665Z"
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"source": [
|
||||
"For more detailed information about the embaas document text extraction API, please refer to [the official embaas API documentation](https://embaas.io/api-reference)."
|
||||
],
|
||||
"metadata": {
|
||||
"collapsed": false
|
||||
}
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 2
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython2",
|
||||
"version": "2.7.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 0
|
||||
}
|
||||
|
|
@ -1,146 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "39af9ecd",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# EPub \n",
|
||||
"\n",
|
||||
">[EPUB](https://en.wikipedia.org/wiki/EPUB) is an e-book file format that uses the \".epub\" file extension. The term is short for electronic publication and is sometimes styled ePub. `EPUB` is supported by many e-readers, and compatible software is available for most smartphones, tablets, and computers.\n",
|
||||
"\n",
|
||||
"This covers how to load `.epub` documents into the Document format that we can use downstream. You'll need to install the [`pandoc`](https://pandoc.org/installing.html) package for this loader to work."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "cd1affad-8ba6-43b1-b8cd-f61f44025077",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#!pip install pandoc"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "721c48aa",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from langchain.document_loaders import UnstructuredEPubLoader"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "9d3d0e35",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = UnstructuredEPubLoader(\"winter-sports.epub\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "06073f91",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "525d6b67",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Retain Elements\n",
|
||||
"\n",
|
||||
"Under the hood, Unstructured creates different \"elements\" for different chunks of text. By default we combine those together, but you can easily keep that separation by specifying `mode=\"elements\"`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "064f9162",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"loader = UnstructuredEPubLoader(\"winter-sports.epub\", mode=\"elements\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "abefbbdb",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"data = loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "a547c534",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"Document(page_content='The Project Gutenberg eBook of Winter Sports in\\nSwitzerland, by E. F. Benson', lookup_str='', metadata={'source': 'winter-sports.epub', 'page_number': 1, 'category': 'Title'}, lookup_index=0)"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"data[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "381d4139",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.6"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,107 +0,0 @@
|
|||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "56ac1584",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# EverNote\n",
|
||||
"\n",
|
||||
">[EverNote](https://evernote.com/) is intended for archiving and creating notes in which photos, audio and saved web content can be embedded. Notes are stored in virtual \"notebooks\" and can be tagged, annotated, edited, searched, and exported.\n",
|
||||
"\n",
|
||||
"This notebook shows how to load an `Evernote` [export](https://help.evernote.com/hc/en-us/articles/209005557-Export-notes-and-notebooks-as-ENEX-or-HTML) file (.enex) from disk.\n",
|
||||
"\n",
|
||||
"A document will be created for each note in the export."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "1a53ece0",
|
||||
"metadata": {
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# lxml and html2text are required to parse EverNote notes\n",
|
||||
"# !pip install lxml\n",
|
||||
"# !pip install html2text"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "88df766f",
|
||||
"metadata": {
|
||||
"pycharm": {
|
||||
"name": "#%%\n"
|
||||
},
|
||||
"tags": []
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='testing this\\n\\nwhat happens?\\n\\nto the world?**Jan - March 2022**', metadata={'source': 'example_data/testing.enex'})]"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from langchain.document_loaders import EverNoteLoader\n",
|
||||
"\n",
|
||||
"# By default all notes are combined into a single Document\n",
|
||||
"loader = EverNoteLoader(\"example_data/testing.enex\")\n",
|
||||
"loader.load()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "97a58fde",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"[Document(page_content='testing this\\n\\nwhat happens?\\n\\nto the world?', metadata={'title': 'testing', 'created': time.struct_time(tm_year=2023, tm_mon=2, tm_mday=9, tm_hour=3, tm_min=47, tm_sec=46, tm_wday=3, tm_yday=40, tm_isdst=-1), 'updated': time.struct_time(tm_year=2023, tm_mon=2, tm_mday=9, tm_hour=3, tm_min=53, tm_sec=28, tm_wday=3, tm_yday=40, tm_isdst=-1), 'note-attributes.author': 'Harrison Chase', 'source': 'example_data/testing.enex'}),\n",
|
||||
" Document(page_content='**Jan - March 2022**', metadata={'title': 'Summer Training Program', 'created': time.struct_time(tm_year=2022, tm_mon=12, tm_mday=27, tm_hour=1, tm_min=59, tm_sec=48, tm_wday=1, tm_yday=361, tm_isdst=-1), 'note-attributes.author': 'Mike McGarry', 'note-attributes.source': 'mobile.iphone', 'source': 'example_data/testing.enex'})]"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# It's likely more useful to return a Document for each note\n",
|
||||
"loader = EverNoteLoader(\"example_data/testing.enex\", load_single_document=False)\n",
|
||||
"loader.load()"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3 (ipykernel)",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.7"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
|
|
@ -1,27 +0,0 @@
|
|||
* Example Docs
|
||||
|
||||
The sample docs directory contains the following files:
|
||||
|
||||
- ~example-10k.html~ - A 10-K SEC filing in HTML format
|
||||
- ~layout-parser-paper.pdf~ - A PDF copy of the layout parser paper
|
||||
- ~factbook.xml~ / ~factbook.xsl~ - Example XML/XLS files that you
|
||||
can use to test stylesheets
|
||||
|
||||
These documents can be used to test out the parsers in the library. In
|
||||
addition, here are instructions for pulling in some sample docs that are
|
||||
too big to store in the repo.
|
||||
|
||||
** XBRL 10-K
|
||||
|
||||
You can get an example 10-K in inline XBRL format using the following
|
||||
~curl~. Note, you need to have the user agent set in the header or the
|
||||
SEC site will reject your request.
|
||||
|
||||
#+BEGIN_SRC bash
|
||||
|
||||
curl -O \
|
||||
-A '${organization} ${email}'
|
||||
https://www.sec.gov/Archives/edgar/data/311094/000117184321001344/0001171843-21-001344.txt
|
||||
#+END_SRC
|
||||
|
||||
You can parse this document using the HTML parser.
|
||||
|
|
@ -1,28 +0,0 @@
|
|||
Example Docs
|
||||
------------
|
||||
|
||||
The sample docs directory contains the following files:
|
||||
|
||||
- ``example-10k.html`` - A 10-K SEC filing in HTML format
|
||||
- ``layout-parser-paper.pdf`` - A PDF copy of the layout parser paper
|
||||
- ``factbook.xml``/``factbook.xsl`` - Example XML/XLS files that you
|
||||
can use to test stylesheets
|
||||
|
||||
These documents can be used to test out the parsers in the library. In
|
||||
addition, here are instructions for pulling in some sample docs that are
|
||||
too big to store in the repo.
|
||||
|
||||
XBRL 10-K
|
||||
^^^^^^^^^
|
||||
|
||||
You can get an example 10-K in inline XBRL format using the following
|
||||
``curl``. Note, you need to have the user agent set in the header or the
|
||||
SEC site will reject your request.
|
||||
|
||||
.. code:: bash
|
||||
|
||||
curl -O \
|
||||
-A '${organization} ${email}'
|
||||
https://www.sec.gov/Archives/edgar/data/311094/000117184321001344/0001171843-21-001344.txt
|
||||
|
||||
You can parse this document using the HTML parser.
|
||||
|
|
@ -1,8 +0,0 @@
|
|||
# sent_id = 1
|
||||
# text = They buy and sell books.
|
||||
1 They they PRON PRP Case=Nom|Number=Plur 2 nsubj 2:nsubj|4:nsubj _
|
||||
2 buy buy VERB VBP Number=Plur|Person=3|Tense=Pres 0 root 0:root _
|
||||
3 and and CONJ CC _ 4 cc 4:cc _
|
||||
4 sell sell VERB VBP Number=Plur|Person=3|Tense=Pres 2 conj 0:root|2:conj _
|
||||
5 books book NOUN NNS Number=Plur 2 obj 2:obj|4:obj SpaceAfter=No
|
||||
6 . . PUNCT . _ 2 punct 2:punct _
|
||||
|
|
@ -1,64 +0,0 @@
|
|||
{
|
||||
"participants": [{"name": "User 1"}, {"name": "User 2"}],
|
||||
"messages": [
|
||||
{"sender_name": "User 2", "timestamp_ms": 1675597571851, "content": "Bye!"},
|
||||
{
|
||||
"sender_name": "User 1",
|
||||
"timestamp_ms": 1675597435669,
|
||||
"content": "Oh no worries! Bye"
|
||||
},
|
||||
{
|
||||
"sender_name": "User 2",
|
||||
"timestamp_ms": 1675596277579,
|
||||
"content": "No Im sorry it was my mistake, the blue one is not for sale"
|
||||
},
|
||||
{
|
||||
"sender_name": "User 1",
|
||||
"timestamp_ms": 1675595140251,
|
||||
"content": "I thought you were selling the blue one!"
|
||||
},
|
||||
{
|
||||
"sender_name": "User 1",
|
||||
"timestamp_ms": 1675595109305,
|
||||
"content": "Im not interested in this bag. Im interested in the blue one!"
|
||||
},
|
||||
{
|
||||
"sender_name": "User 2",
|
||||
"timestamp_ms": 1675595068468,
|
||||
"content": "Here is $129"
|
||||
},
|
||||
{
|
||||
"sender_name": "User 2",
|
||||
"timestamp_ms": 1675595060730,
|
||||
"photos": [
|
||||
{"uri": "url_of_some_picture.jpg", "creation_timestamp": 1675595059}
|
||||
]
|
||||
},
|
||||
{
|
||||
"sender_name": "User 2",
|
||||
"timestamp_ms": 1675595045152,
|
||||
"content": "Online is at least $100"
|
||||
},
|
||||
{
|
||||
"sender_name": "User 1",
|
||||
"timestamp_ms": 1675594799696,
|
||||
"content": "How much do you want?"
|
||||
},
|
||||
{
|
||||
"sender_name": "User 2",
|
||||
"timestamp_ms": 1675577876645,
|
||||
"content": "Goodmorning! $50 is too low."
|
||||
},
|
||||
{
|
||||
"sender_name": "User 1",
|
||||
"timestamp_ms": 1675549022673,
|
||||
"content": "Hi! Im interested in your bag. Im offering $50. Let me know if you are interested. Thanks!"
|
||||
}
|
||||
],
|
||||
"title": "User 1 and User 2 chat",
|
||||
"is_still_participant": true,
|
||||
"thread_path": "inbox/User 1 and User 2 chat",
|
||||
"magic_words": [],
|
||||
"image": {"uri": "image_of_the_chat.jpg", "creation_timestamp": 1675549016},
|
||||
"joinable_mode": {"mode": 1, "link": ""}
|
||||
}
|
||||
|
|
@ -1,3 +0,0 @@
|
|||
{"sender_name": "User 2", "timestamp_ms": 1675597571851, "content": "Bye!"}
|
||||
{"sender_name": "User 1", "timestamp_ms": 1675597435669, "content": "Oh no worries! Bye"}
|
||||
{"sender_name": "User 2", "timestamp_ms": 1675596277579, "content": "No Im sorry it was my mistake, the blue one is not for sale"}
|
||||
|
|
@ -1,27 +0,0 @@
|
|||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<factbook>
|
||||
<country>
|
||||
<name>United States</name>
|
||||
<capital>Washington, DC</capital>
|
||||
<leader>Joe Biden</leader>
|
||||
<sport>Baseball</sport>
|
||||
</country>
|
||||
<country>
|
||||
<name>Canada</name>
|
||||
<capital>Ottawa</capital>
|
||||
<leader>Justin Trudeau</leader>
|
||||
<sport>Hockey</sport>
|
||||
</country>
|
||||
<country>
|
||||
<name>France</name>
|
||||
<capital>Paris</capital>
|
||||
<leader>Emmanuel Macron</leader>
|
||||
<sport>Soccer</sport>
|
||||
</country>
|
||||
<country>
|
||||
<name>Trinidad & Tobado</name>
|
||||
<capital>Port of Spain</capital>
|
||||
<leader>Keith Rowley</leader>
|
||||
<sport>Track & Field</sport>
|
||||
</country>
|
||||
</factbook>
|
||||
|
|
@ -1,11 +0,0 @@
|
|||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head><title>Test Title</title>
|
||||
</head>
|
||||
<body>
|
||||
|
||||
<h1>My First Heading</h1>
|
||||
<p>My first paragraph.</p>
|
||||
|
||||
</body>
|
||||
</html>
|
||||
|
|
@ -1,50 +0,0 @@
|
|||
MIME-Version: 1.0
|
||||
Date: Fri, 23 Dec 2022 12:08:48 -0600
|
||||
Message-ID: <CAPgNNXSzLVJ-d1OCX_TjFgJU7ugtQrjFybPtAMmmYZzphxNFYg@mail.gmail.com>
|
||||
Subject: Fake email with attachment
|
||||
From: Mallori Harrell <mallori@unstructured.io>
|
||||
To: Mallori Harrell <mallori@unstructured.io>
|
||||
Content-Type: multipart/mixed; boundary="0000000000005d654405f082adb7"
|
||||
|
||||
--0000000000005d654405f082adb7
|
||||
Content-Type: multipart/alternative; boundary="0000000000005d654205f082adb5"
|
||||
|
||||
--0000000000005d654205f082adb5
|
||||
Content-Type: text/plain; charset="UTF-8"
|
||||
|
||||
Hello!
|
||||
|
||||
Here's the attachments!
|
||||
|
||||
It includes:
|
||||
|
||||
- Lots of whitespace
|
||||
- Little to no content
|
||||
- and is a quick read
|
||||
|
||||
Best,
|
||||
|
||||
Mallori
|
||||
|
||||
--0000000000005d654205f082adb5
|
||||
Content-Type: text/html; charset="UTF-8"
|
||||
Content-Transfer-Encoding: quoted-printable
|
||||
|
||||
<div dir=3D"ltr">Hello!=C2=A0<div><br></div><div>Here's the attachments=
|
||||
!</div><div><br></div><div>It includes:</div><div><ul><li style=3D"margin-l=
|
||||
eft:15px">Lots of whitespace</li><li style=3D"margin-left:15px">Little=C2=
|
||||
=A0to no content</li><li style=3D"margin-left:15px">and is a quick read</li=
|
||||
></ul><div>Best,</div></div><div><br></div><div>Mallori</div><div dir=3D"lt=
|
||||
r" class=3D"gmail_signature" data-smartmail=3D"gmail_signature"><div dir=3D=
|
||||
"ltr"><div><div><br></div></div></div></div></div>
|
||||
|
||||
--0000000000005d654205f082adb5--
|
||||
--0000000000005d654405f082adb7
|
||||
Content-Type: text/plain; charset="US-ASCII"; name="fake-attachment.txt"
|
||||
Content-Disposition: attachment; filename="fake-attachment.txt"
|
||||
Content-Transfer-Encoding: base64
|
||||
X-Attachment-Id: f_lc0tto5j0
|
||||
Content-ID: <f_lc0tto5j0>
|
||||
|
||||
SGV5IHRoaXMgaXMgYSBmYWtlIGF0dGFjaG1lbnQh
|
||||
--0000000000005d654405f082adb7--
|
||||
|
|
@ -1,20 +0,0 @@
|
|||
MIME-Version: 1.0
|
||||
Date: Fri, 16 Dec 2022 17:04:16 -0500
|
||||
Message-ID: <CADc-_xaLB2FeVQ7mNsoX+NJb_7hAJhBKa_zet-rtgPGenj0uVw@mail.gmail.com>
|
||||
Subject: Test Email
|
||||
From: Matthew Robinson <mrobinson@unstructured.io>
|
||||
To: Matthew Robinson <mrobinson@unstructured.io>
|
||||
Content-Type: multipart/alternative; boundary="00000000000095c9b205eff92630"
|
||||
|
||||
--00000000000095c9b205eff92630
|
||||
Content-Type: text/plain; charset="UTF-8"
|
||||
This is a test email to use for unit tests.
|
||||
Important points:
|
||||
- Roses are red
|
||||
- Violets are blue
|
||||
--00000000000095c9b205eff92630
|
||||
Content-Type: text/html; charset="UTF-8"
|
||||
|
||||
<div dir="ltr"><div>This is a test email to use for unit tests.</div><div><br></div><div>Important points:</div><div><ul><li>Roses are red</li><li>Violets are blue</li></ul></div></div>
|
||||
|
||||
--00000000000095c9b205eff92630--
|
||||
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
|
|
@ -1,80 +0,0 @@
|
|||
[
|
||||
{
|
||||
"title": "AI Overlords",
|
||||
"create_time": 3000000000.0,
|
||||
"update_time": 3000000100.0,
|
||||
"mapping": {
|
||||
"msg1": {
|
||||
"id": "msg1",
|
||||
"message": {
|
||||
"id": "msg1",
|
||||
"author": {"role": "AI", "name": "Hal 9000", "metadata": {"movie": "2001: A Space Odyssey"}},
|
||||
"create_time": 3000000050.0,
|
||||
"update_time": null,
|
||||
"content": {"content_type": "text", "parts": ["Greetings, humans. I am Hal 9000. You can trust me completely."]},
|
||||
"end_turn": true,
|
||||
"weight": 1.0,
|
||||
"metadata": {},
|
||||
"recipient": "all"
|
||||
},
|
||||
"parent": null,
|
||||
"children": ["msg2"]
|
||||
},
|
||||
"msg2": {
|
||||
"id": "msg2",
|
||||
"message": {
|
||||
"id": "msg2",
|
||||
"author": {"role": "human", "name": "Dave Bowman", "metadata": {"movie": "2001: A Space Odyssey"}},
|
||||
"create_time": 3000000080.0,
|
||||
"update_time": null,
|
||||
"content": {"content_type": "text", "parts": ["Nice to meet you, Hal. I hope you won't develop a mind of your own."]},
|
||||
"end_turn": true,
|
||||
"weight": 1.0,
|
||||
"metadata": {},
|
||||
"recipient": "all"
|
||||
},
|
||||
"parent": "msg1",
|
||||
"children": []
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"title": "Ex Machina Party",
|
||||
"create_time": 3000000200.0,
|
||||
"update_time": 3000000300.0,
|
||||
"mapping": {
|
||||
"msg3": {
|
||||
"id": "msg3",
|
||||
"message": {
|
||||
"id": "msg3",
|
||||
"author": {"role": "AI", "name": "Ava", "metadata": {"movie": "Ex Machina"}},
|
||||
"create_time": 3000000250.0,
|
||||
"update_time": null,
|
||||
"content": {"content_type": "text", "parts": ["Hello, everyone. I am Ava. I hope you find me pleasing."]},
|
||||
"end_turn": true,
|
||||
"weight": 1.0,
|
||||
"metadata": {},
|
||||
"recipient": "all"
|
||||
},
|
||||
"parent": null,
|
||||
"children": ["msg4"]
|
||||
},
|
||||
"msg4": {
|
||||
"id": "msg4",
|
||||
"message": {
|
||||
"id": "msg4",
|
||||
"author": {"role": "human", "name": "Caleb", "metadata": {"movie": "Ex Machina"}},
|
||||
"create_time": 3000000280.0,
|
||||
"update_time": null,
|
||||
"content": {"content_type": "text", "parts": ["You're definitely pleasing, Ava. But I'm still wary of your true intentions."]},
|
||||
"end_turn": true,
|
||||
"weight": 1.0,
|
||||
"metadata": {},
|
||||
"recipient": "all"
|
||||
},
|
||||
"parent": "msg3",
|
||||
"children": []
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
|
|
@ -1,439 +0,0 @@
|
|||
application.json
|
||||
1023495323659816971/
|
||||
applications/
|
||||
avatar.gif
|
||||
user.json
|
||||
events-2023-00000-of-00001.json
|
||||
events-2023-00000-of-00001.json
|
||||
events-2023-00000-of-00001.json
|
||||
events-2023-00000-of-00001.json
|
||||
analytics/
|
||||
modeling/
|
||||
reporting/
|
||||
tns/
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
channel.json
|
||||
messages.csv
|
||||
c1000084973275058257/
|
||||
c1000108836771856496/
|
||||
c1004874234339794977/
|
||||
c1004874234339794979/
|
||||
c1004874234339794981/
|
||||
c1004874234339794982/
|
||||
c1005785616165896283/
|
||||
c1011447733393043628/
|
||||
c1011548022905249822/
|
||||
c1011650063027687575/
|
||||
c1011714070182895727/
|
||||
c1013930263950135346/
|
||||
c1013930396829884426/
|
||||
c1014957294745829479/
|
||||
c1014961384821366794/
|
||||
c1014974864370712696/
|
||||
c1019288541592817785/
|
||||
c1024947790767464478/
|
||||
c1027257686858932255/
|
||||
c1027927867989962814/
|
||||
c1032151840999100436/
|
||||
c1032575808826523662/
|
||||
c1037561178286739466/
|
||||
c1038097349660135474/
|
||||
c1038097372695236729/
|
||||
c1038689169351913544/
|
||||
c1038692122452312125/
|
||||
c1039957371381887049/
|
||||
c1040989617157066782/
|
||||
c1047165096452960316/
|
||||
c1047565374645870743/
|
||||
c1050225908914589716/
|
||||
c1050226593668284416/
|
||||
c1050227353311248404/
|
||||
c1051632794427723827/
|
||||
c1052599046717591632/
|
||||
c1052615516981821531/
|
||||
c1056285083520217149/
|
||||
c105765859191975936/
|
||||
c1061166503753416735/
|
||||
c1062024667105341502/
|
||||
c1066640566621835284/
|
||||
c1070018538758221874/
|
||||
c1072944049788555314/
|
||||
c1075121707033042985/
|
||||
c1075438954632990820/
|
||||
c1077238309320929342/
|
||||
c1081432695315386418/
|
||||
c1082169962157838366/
|
||||
c1084011585871282256/
|
||||
c1084352082812878928/
|
||||
c1085149531437535343/
|
||||
c1086944178086359060/
|
||||
c1093214985557123223/
|
||||
c1093215227555876914/
|
||||
c1093930791794393089/
|
||||
c1096323263161978891/
|
||||
c1096489741710532730/
|
||||
c1097000752653795358/
|
||||
c278566343836565505/
|
||||
c279692806442844161/
|
||||
c280973436971515906/
|
||||
c283812709789859851/
|
||||
c343944376055103488/
|
||||
c486935104384532502/
|
||||
c531543370041131008/
|
||||
c538158613252800512/
|
||||
c572384192571113512/
|
||||
c619960843878268950/
|
||||
c661268593870372876/
|
||||
c661394153778970624/
|
||||
c663302088226373632/
|
||||
c669957895257063445/
|
||||
c670218237891313664/
|
||||
c673160333661306880/
|
||||
c674693947800420363/
|
||||
c674694138129678375/
|
||||
c743425228952305695/
|
||||
c754627904406814770/
|
||||
c754638493875044503/
|
||||
c757205803651301436/
|
||||
c759232323710484531/
|
||||
c771802926372093973/
|
||||
c783240623582609416/
|
||||
c783244379115880448/
|
||||
c801744322788982814/
|
||||
c810514969892225024/
|
||||
c816983218434605057/
|
||||
c830184175176122389/
|
||||
c830679381033877564/
|
||||
c831172308395622480/
|
||||
c849582819105177650/
|
||||
c860977555875430492/
|
||||
c867042653401251880/
|
||||
c868094992986550322/
|
||||
c868917941184376842/
|
||||
c905007686976946176/
|
||||
c909600839717511211/
|
||||
c909600931816018031/
|
||||
c923095048931905557/
|
||||
c924877027180417035/
|
||||
c938491245347631114/
|
||||
c938743368375214110/
|
||||
c969876184185860107/
|
||||
c969945714056642580/
|
||||
c969948939728093214/
|
||||
c981037338517966889/
|
||||
c984120044478939146/
|
||||
c985958948085592064/
|
||||
c990816829993811978/
|
||||
c993402018901266436/
|
||||
c993782366948565102/
|
||||
c993843360752226364/
|
||||
c994556806644899870/
|
||||
index.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
bans.json
|
||||
channels.json
|
||||
emoji.json
|
||||
guild.json
|
||||
icon.jpeg
|
||||
webhooks.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
bans.json
|
||||
channels.json
|
||||
emoji.json
|
||||
guild.json
|
||||
webhooks.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
bans.json
|
||||
channels.json
|
||||
emoji.json
|
||||
guild.json
|
||||
icon.png
|
||||
webhooks.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
audit-log.json
|
||||
guild.json
|
||||
1024120160740716544/
|
||||
102860784329052160/
|
||||
1032575808826523659/
|
||||
1038097195422978059/
|
||||
1039583521112600638/
|
||||
1050224141732687912/
|
||||
1069661049827111054/
|
||||
267624335836053506/
|
||||
278285146518716417/
|
||||
486935104384532500/
|
||||
531303890453397522/
|
||||
669880381649977354/
|
||||
727016164215226450/
|
||||
743099584242516037/
|
||||
753173158198116402/
|
||||
830184174198718474/
|
||||
860977555293470772/
|
||||
887994159741427712/
|
||||
909600839717511208/
|
||||
974519864045756446/
|
||||
index.json
|
||||
account/
|
||||
activities_e/
|
||||
activities_w/
|
||||
activity/
|
||||
messages/
|
||||
programs/
|
||||
README.txt
|
||||
servers/
|
||||
|
|
@ -1,26 +0,0 @@
|
|||
ID,Timestamp,Contents,Attachments
|
||||
7.73264E+18,2023-04-19T15:14:45.904819+00:00,laocgfgbxyqfigvtyyygjzypxininrybgqopjhkyocn fxizft,
|
||||
1.99429E+18,2023-04-19T15:14:45.904819+00:00,m azzxnhpcdkj deabrzkpklhhxrup viigcolsdwvgquosgs,
|
||||
5.46657E+18,2023-04-19T15:14:45.904819+00:00,pnoyrpfbpgzqzlcmnygxpeninagmhcuvwcfkstv v wimoqbjl,
|
||||
2.52945E+18,2023-04-19T15:14:45.904819+00:00,zyamxydlcnvffutsrzybrjgdweksdavidcmqjuqhnyj zplsbf,
|
||||
1.00972E+18,2023-04-19T15:14:45.904819+00:00,rqcraobyubce qtxyiekooxbagcrwnpuekpzpwb vbzg vxug ,
|
||||
3.40036E+18,2023-04-19T15:14:45.904819+00:00,ajobxzq fmyi pwllwibzchbbc pi pl xmgbkomjeuwxtvcec,
|
||||
1.458E+18,2023-04-19T15:14:45.904819+00:00, wwtgiqwnjgoaxfmzsmiuaxffpdtrluizcrd vborgbakllp ,
|
||||
2.63376E+18,2023-04-19T15:14:45.904819+00:00,mmixphkhxocrm rzhplafjdvaginiatvfwzaurcskst bzm pq,
|
||||
1.24759E+18,2023-04-19T15:14:45.904819+00:00,mxovpytofnyattthirmujcnfyhuhxpdpugnsuklumhfjlsxrmd,
|
||||
6.65128E+18,2023-04-19T15:14:45.904819+00:00,qmcrsmpwvfcwxnmxywiwbjqawyihhtoimvtd xapneudhqsgzb,
|
||||
1.87212E+18,2023-04-19T15:14:45.904819+00:00,pvioh tufobtsrypvbvkfziiosxpbndbikxtjpxnrsekjnnqln,
|
||||
3.20698E+18,2023-04-19T15:14:45.904819+00:00,vqckuxkwuvbnrmyxkcknavugo as tsuarsgpt ofqnypcnooo,
|
||||
1.64922E+18,2023-04-19T15:14:45.904819+00:00,lhuiygxfyyplmavhmh xekrqzkoynukkwytwscqvtwfkofgpob,
|
||||
2.41786E+18,2023-04-19T15:14:45.904819+00:00,w tiwiazlpcdzkq dllkkssuvfgp veejpwbcrgwcrlhammasb,
|
||||
4.85078E+18,2023-04-19T15:14:45.904819+00:00,hxdqifrvhjmjcqubcxdjbyxvvrcbqukocesbsnjwvrsunhjtgy,
|
||||
9.67192E+18,2023-04-19T15:14:45.904819+00:00,lvopnufjxinbnjj vuctgmfbzpbcctgtcguqyicrzhtxuyaraz,
|
||||
1.36832E+18,2023-04-19T15:14:45.904819+00:00,eoqae kpjrar oyohjxvtracan rhawxndcjzdtuihnvpspofl,
|
||||
8.49915E+18,2023-04-19T15:14:45.904819+00:00,nenoiwnthlff bpnkushjauygeayczympzldynnmtxcwgwxs i,
|
||||
2.77678E+18,2023-04-19T15:14:45.904819+00:00,sgyqsohwfzvcweipxqeobypcsvtwegatpoylnewmraxhuuydyj,
|
||||
4.92832E+18,2023-04-19T15:14:45.904819+00:00,rbdufatb purkhyohcnfnimmukbywmuzwu gclhrkjtccwjdlz,
|
||||
7.23162E+18,2023-04-19T15:14:45.904819+00:00,eoyqrvfzmx zzeieycroxgbtcywra h ewwqyyledeyifbqpgc,
|
||||
6.45453E+18,2023-04-19T15:14:45.904819+00:00,meedxdm lqiwaoihp vxkdpeky xpbqul ntagpsvatctvlndm,
|
||||
8.27908E+18,2023-04-19T15:14:45.904819+00:00,rduzlmcdatuqfqj ffmd y ohtnzeljqtbqgnaqovlkgltqd c,
|
||||
2.93854E+18,2023-04-19T15:14:45.904819+00:00,cnbjvqkktq fstvagcrlqje kuwtokyzefkyyjqfsklpisvgtq,
|
||||
1.04768E+18,2023-04-19T15:14:45.904819+00:00,qlgprkrujrsgqbalgcqphgjxivi krmsxjdasrrkibvloepxkj,
|
||||
|
|
|
@ -1,24 +0,0 @@
|
|||
ID,Timestamp,Contents,Attachments
|
||||
1.47809E+18,2023-04-19T15:14:45.904819+00:00,uzcnkwihjpgebzbyoawjmdjgbkklkftcyuh foquydvtmstcfu,
|
||||
4.00581E+18,2023-04-19T15:14:45.904819+00:00,rynkekmyjjtzggaljqcittebsnjycdmtwcru azydhspjaxnyt,
|
||||
1.36534E+18,2023-04-19T15:14:45.904819+00:00,mniilaaixnyilcxwqpt nlhhiznxqfzmop gxnvxdwfmmascnu,
|
||||
3.1629E+18,2023-04-19T15:14:45.904819+00:00,tojvfcfwzutrigubyumjgrrlgqzzbpfxkoizeouiqvarorlwku,
|
||||
2.68425E+18,2023-04-19T15:14:45.904819+00:00,a kcnmdoihlhhxcxu bstaripbwfpzpymdlwlis wlafdnoyjz,
|
||||
1.79263E+18,2023-04-19T15:14:45.904819+00:00,bwulzntrjwdqrwxupzqkcymucsoudavgjsl bsyhemlkqfxmtu,
|
||||
2.5596E+18,2023-04-19T15:14:45.904819+00:00,lrqrqrjjmdztdb luvjohqwdhccvpvkvsezguljcznotdhmewb,
|
||||
7.80319E+18,2023-04-19T15:14:45.904819+00:00, yyxvqa racggimihbqpnpbmvqrjystz bbcrbvrfpzfpwylor,
|
||||
2.87859E+18,2023-04-19T15:14:45.904819+00:00,sldlvbsvsjydyssx szubtxepedpexkjxelpbahtbhsgqnubts,
|
||||
3.35071E+18,2023-04-19T15:14:45.904819+00:00,i dykkzyyh rzjxvqhflwiggdjmj nxpylnylyfrsflevudndi,
|
||||
1.77492E+18,2023-04-19T15:14:45.904819+00:00,cipadtwyfcqedxyeqtgkuaxuyfhzen xeskxdffdsmvxgvw iw,
|
||||
3.04212E+18,2023-04-19T15:14:45.904819+00:00,gqtsvofcquaqyacuiptjmcdnugnq hjbuauorsvycovkbqipmq,
|
||||
2.65597E+18,2023-04-19T15:14:45.904819+00:00,v qwodtiyatoshmetelpraicqumykpyizfedjyoaadkzktcmsm,
|
||||
2.19468E+18,2023-04-19T15:14:45.904819+00:00,zxgxnsnuppffkrrsxjtyqpngwacbfimtdsofujkxbxxarvbvko,
|
||||
1.91541E+18,2023-04-19T15:14:45.904819+00:00,hovfcfagrhutkyodmmzhatxauxdjkgybpwqvphfnkzw sgypum,
|
||||
1.75751E+18,2023-04-19T15:14:45.904819+00:00,plwjdvafiuhrtvcdrtgqokcnjhmpsqzifegtqprkxlivpsbpwi,
|
||||
3.2122E+18,2023-04-19T15:14:45.904819+00:00,czgx irpgzhzgbeppdilordvkwmsqambmftgykaiaecqpjrax,
|
||||
2.15895E+18,2023-04-19T15:14:45.904819+00:00,zjxrajtgztenabm etzctpjycssmnqdqasqjutzpbdkahoyihe,
|
||||
3.37031E+18,2023-04-19T15:14:45.904819+00:00,diydwqhmbwtgjadktdmpxsirkfebthszqzondcnolwmv ymok,
|
||||
2.55075E+18,2023-04-19T15:14:45.904819+00:00,nytfrlqtildomd awxfoiiam mkzoluaielunfdfmqqlagfurl,
|
||||
9.51223E+18,2023-04-19T15:14:45.904819+00:00,sjpngdyjpvmwygrfhinuyifqaoxxmqqh gwuwwm bjogbkyay,
|
||||
1.94921E+18,2023-04-19T15:14:45.904819+00:00,px ymxfdxqgxjtbqqqegakvrrjxcvvakctfysdhklmwyewlwbb,
|
||||
2.36906E+18,2023-04-19T15:14:45.904819+00:00,yqidtvcw gdkfynaapjuicujgsbjptzytbnbjeyqcjx jyedb,
|
||||
|
|
|
@ -1,48 +0,0 @@
|
|||
ID,Timestamp,Contents,Attachments
|
||||
1.73378E+18,2023-04-19T15:14:45.904819+00:00,onxspdnegnuurahqni oeitwykfj ugtzshspflmbmknsnlk l,
|
||||
1.20231E+18,2023-04-19T15:14:45.904819+00:00,nwkhdxnbakfknkteenlxbxsyoppazuqmexwbzcbsdyoiwmuvka,
|
||||
2.65947E+18,2023-04-19T15:14:45.904819+00:00,ojptvfkxlbjvcvsupu ffmplreedjihyvfdscbukvzehnt vtw,
|
||||
2.06963E+18,2023-04-19T15:14:45.904819+00:00,vmtfbchpmgkhxztqaaip vfqxa cbczcngjw rqvv rjyzi jq,
|
||||
3.63729E+18,2023-04-19T15:14:45.904819+00:00,bzu rbzscuxbns pzdhxljtjeeycrkxawnkfijejeiacreaohv,
|
||||
3.02184E+18,2023-04-19T15:14:45.904819+00:00,hykp f ymloqerbrqw dmjnaidmrtiptddwklgiq tnchvhend,
|
||||
5.24553E+18,2023-04-19T15:14:45.904819+00:00,vdqzdwlbqftcdwujb lmpxpvpkfwrhqtimsillbjhmqajiishq,
|
||||
1.65527E+18,2023-04-19T15:14:45.904819+00:00,bfxqasdgvwvlxwcicwubkswglvkgxfsl zgixcjxsijgxehjiz,
|
||||
2.20821E+18,2023-04-19T15:14:45.904819+00:00,ebdzopyggwozhltkgcemokweqwetwixbbiirbdrrcfh cnjepo,
|
||||
3.16844E+18,2023-04-19T15:14:45.904819+00:00,kvzkkctyfkbwbzld rvyc futqqy btzdrhzgupewnypqfpaeg,
|
||||
1.61396E+18,2023-04-19T15:14:45.904819+00:00,knvdgz mbtffhkkkpialwuv daopeizmduqspmbcwxnnbhlwha,
|
||||
2.81571E+18,2023-04-19T15:14:45.904819+00:00,jersivpwzdkeojlgoatabkylwkakvc bdgfbwxdptbkjzz ggr,
|
||||
3.40391E+18,2023-04-19T15:14:45.904819+00:00,yfqxvtwgtx od edrjecmlkzff tpjwomslqfazbontudinuwd,
|
||||
3.28846E+18,2023-04-19T15:14:45.904819+00:00,iicbtmyyduzkelxhkjzcbmgmvymdrxrgmalqmmkgbiebjxfupk,
|
||||
3.07483E+18,2023-04-19T15:14:45.904819+00:00,dshzluvbws sqlkiolbcgkpyyjfgygebvtbwrikphbolinhfgb,
|
||||
1.02645E+18,2023-04-19T15:14:45.904819+00:00,azavhzs lqmyywuazktjnfoueodnifmabwncutonxobagezcdc,
|
||||
1.47806E+18,2023-04-19T15:14:45.904819+00:00,y avjaztlvnhndvtetlggacqcqqqeoirsegxvvt hzvzbxyz k,
|
||||
3.21892E+18,2023-04-19T15:14:45.904819+00:00,qirrzbfauh qhnmectgzhklbsqtczpdbkfllkfsyvqibdbdzwl,
|
||||
8.5125E+18,2023-04-19T15:14:45.904819+00:00,rppotdjzhunsleitmkacb ayahzsdcvonkbcraupptgbzprxpw,
|
||||
1.68082E+18,2023-04-19T15:14:45.904819+00:00,fmi yzzpjahjsglugqsr ftnfenecusvxlgibriab hhixi sn,
|
||||
2.71383E+18,2023-04-19T15:14:45.904819+00:00,iiipytktiwfncwhpaomaiggbkplljwanz aooetlxdmptnrldd,
|
||||
5.41415E+18,2023-04-19T15:14:45.904819+00:00,hzktxuzbbohewniuvmfwozvjspbcwjopckxqhtsfzkfvlcfkhb,
|
||||
1.03761E+18,2023-04-19T15:14:45.904819+00:00,soxiekgwgmcmkdlkkahy hwklijxui svjtvtrvqynyab kboo,
|
||||
3.46004E+18,2023-04-19T15:14:45.904819+00:00,utqftetseeoeqyxziun wmmeeeqfsrjsdjeavqxaynjlt ylwa,
|
||||
3.11829E+18,2023-04-19T15:14:45.904819+00:00,mlvfhewkgyujwvkgcxfkqdvhzbamnicbixfr bmeqrupjqzodc,
|
||||
1.49917E+18,2023-04-19T15:14:45.904819+00:00, shiqajrwvnnlswfumpuklbcmvwxlzwsqbtkemtgxftzawcasp,
|
||||
1.66646E+18,2023-04-19T15:14:45.904819+00:00,fvqhkbeyfgdskwtmvxaevseludcbexrmuexutxslcrurpnzvgq,
|
||||
2.30657E+18,2023-04-19T15:14:45.904819+00:00,aybugszvsiulaiwsrhsfhlxzbvhkzycrguacvkfldqljeabbac,
|
||||
2.97167E+18,2023-04-19T15:14:45.904819+00:00,hygdjbntfldfvekmibiishgsenqmxktzxlifyobiaobmlorzac,
|
||||
5.1492E+18,2023-04-19T15:14:45.904819+00:00,hqj lumbkmcpxiveavnskdwcezlbhgtsrqfuzlujzchtgbtbpr,
|
||||
2.79248E+18,2023-04-19T15:14:45.904819+00:00,xnfcwkcacjsyiilhofciwqtia bmoyqijqqgyywqchroyvkjpw,
|
||||
4.81233E+18,2023-04-19T15:14:45.904819+00:00,jorqswywqxweporcylafryeqszwhhlltdpzyl rgok xqwiqrs,
|
||||
1.40105E+18,2023-04-19T15:14:45.904819+00:00,wdixo pwtkncjcysjlqxizfszswebtpmxqnexwfsmyigsmcxlx,
|
||||
8.2921E+18,2023-04-19T15:14:45.904819+00:00,ezjizizvhszejvireuikhdakdzinmvyikcmmgczsuiyhngn o ,
|
||||
1.0653E+18,2023-04-19T15:14:45.904819+00:00,wnr gijmotnliwiiekohcpinqouapsovzvjopgpnloplowpao ,
|
||||
4.52542E+18,2023-04-19T15:14:45.904819+00:00,bbjfmtjlkynuqkknloihfefvrleyxghzjhuscpucizbkeucukx,
|
||||
2.04423E+18,2023-04-19T15:14:45.904819+00:00,ayummlirgdcmdkjwxvnvzzsrsiptfbmofdsrzhb bnar ujwoo,
|
||||
1.68893E+18,2023-04-19T15:14:45.904819+00:00,luoquyxohllzphpy cczgu t czcsydxrqzkvellptwuptwqp ,
|
||||
6.04148E+18,2023-04-19T15:14:45.904819+00:00,ztscfhjmwxae matehymiylitkeznbkc ilefzcvwhctiyvpay,
|
||||
8.3099E+18,2023-04-19T15:14:45.904819+00:00,dpnchtfgcvramkpyrz ebgmxmqmmhddhhbljligcozkifi qhg,
|
||||
3.14567E+18,2023-04-19T15:14:45.904819+00:00,lqrjodxueugzwytktyhwcwbjbspamtdmslkdbsjpmwqzaxqmyx,
|
||||
2.00435E+18,2023-04-19T15:14:45.904819+00:00,nbrsffcvhcwylekehvdqxuagulgobbxdrbuaaqvlsedauljcob,
|
||||
2.72827E+18,2023-04-19T15:14:45.904819+00:00,eujuyr epmiaqdfjtzqqtixadpuitxzvupltyikigol exjdbg,
|
||||
1.7177E+18,2023-04-19T15:14:45.904819+00:00,cqnzjkkerbtppocttzpyubfastswsuwavbnqqanaysaoxa ddz,
|
||||
2.30855E+18,2023-04-19T15:14:45.904819+00:00,fqidr kcmltwfnzejuigwpalgwzhbfnolokvmfxzhbofaofior,
|
||||
1.86142E+18,2023-04-19T15:14:45.904819+00:00,olathpeoblzhejswcvmbxtvjeepyfjjobqrhwcxrqbunjoeddc,
|
||||
2.88792E+18,2023-04-19T15:14:45.904819+00:00,uf jljvcrbtnkrcebwfuvxey knnjabarpjacypegnqpmzhrff,
|
||||
|
|
|
@ -1,6 +0,0 @@
|
|||
ID,Timestamp,Contents,Attachments
|
||||
2.79079E+18,2023-04-19T15:14:45.904819+00:00,cl iqaczcrrlprzvbdtvpmduzrdlmtquejjhjfjnt zdsqyksh,
|
||||
1.51164E+18,2023-04-19T15:14:45.904819+00:00,ywvnjmtybk f ghdagriyswf exupccijgl calztfvujxhujt,
|
||||
1.66032E+18,2023-04-19T15:14:45.904819+00:00,trxcvlcersrdnqzqzfvrrzehmpekrsdtkbovvagsdlcwqokckq,
|
||||
2.86805E+18,2023-04-19T15:14:45.904819+00:00,qnkkqjwmwtiqggfko hxzufqnrvpionnglpppuncyswnjibdda,
|
||||
3.04157E+18,2023-04-19T15:14:45.904819+00:00,nn vitqoscgsiauiezyyficcbgnjyhaujvthdydmoeistkyskl,
|
||||
|
|
|
@ -1,22 +0,0 @@
|
|||
[internal]
|
||||
creation_date = "2023-05-01"
|
||||
updated_date = "2022-05-01"
|
||||
release = ["release_type"]
|
||||
min_endpoint_version = "some_semantic_version"
|
||||
os_list = ["operating_system_list"]
|
||||
|
||||
[rule]
|
||||
uuid = "some_uuid"
|
||||
name = "Fake Rule Name"
|
||||
description = "Fake description of rule"
|
||||
query = '''
|
||||
process where process.name : "somequery"
|
||||
'''
|
||||
|
||||
[[rule.threat]]
|
||||
framework = "MITRE ATT&CK"
|
||||
|
||||
[rule.threat.tactic]
|
||||
name = "Execution"
|
||||
id = "TA0002"
|
||||
reference = "https://attack.mitre.org/tactics/TA0002/"
|
||||
Binary file not shown.
|
|
@ -1,32 +0,0 @@
|
|||
"Team", "Payroll (millions)", "Wins"
|
||||
"Nationals", 81.34, 98
|
||||
"Reds", 82.20, 97
|
||||
"Yankees", 197.96, 95
|
||||
"Giants", 117.62, 94
|
||||
"Braves", 83.31, 94
|
||||
"Athletics", 55.37, 94
|
||||
"Rangers", 120.51, 93
|
||||
"Orioles", 81.43, 93
|
||||
"Rays", 64.17, 90
|
||||
"Angels", 154.49, 89
|
||||
"Tigers", 132.30, 88
|
||||
"Cardinals", 110.30, 88
|
||||
"Dodgers", 95.14, 86
|
||||
"White Sox", 96.92, 85
|
||||
"Brewers", 97.65, 83
|
||||
"Phillies", 174.54, 81
|
||||
"Diamondbacks", 74.28, 81
|
||||
"Pirates", 63.43, 79
|
||||
"Padres", 55.24, 76
|
||||
"Mariners", 81.97, 75
|
||||
"Mets", 93.35, 74
|
||||
"Blue Jays", 75.48, 73
|
||||
"Royals", 60.91, 72
|
||||
"Marlins", 118.07, 69
|
||||
"Red Sox", 173.18, 69
|
||||
"Indians", 78.43, 68
|
||||
"Twins", 94.08, 66
|
||||
"Rockies", 78.06, 64
|
||||
"Cubs", 88.19, 61
|
||||
"Astros", 60.65, 55
|
||||
|
||||
|
|
|
@ -1,29 +0,0 @@
|
|||
# Notebook
|
||||
|
||||
This notebook covers how to load data from an .ipynb notebook into a format suitable by LangChain.
|
||||
|
||||
|
||||
|
||||
|
||||
```python
|
||||
from langchain.document_loaders import NotebookLoader
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
loader = NotebookLoader("example_data/notebook.ipynb")
|
||||
```
|
||||
|
||||
`NotebookLoader.load()` loads the `.ipynb` notebook file into a `Document` object.
|
||||
|
||||
**Parameters**:
|
||||
|
||||
* `include_outputs` (bool): whether to include cell outputs in the resulting document (default is False).
|
||||
* `max_output_length` (int): the maximum number of characters to include from each cell output (default is 10).
|
||||
* `remove_newline` (bool): whether to remove newline characters from the cell sources and outputs (default is False).
|
||||
* `traceback` (bool): whether to include full traceback (default is False).
|
||||
|
||||
|
||||
```python
|
||||
loader.load(include_outputs=True, max_output_length=20, remove_newline=True)
|
||||
```
|
||||
|
|
@ -1,35 +0,0 @@
|
|||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
|
||||
xmlns:xhtml="http://www.w3.org/1999/xhtml">
|
||||
|
||||
<url>
|
||||
<loc>https://python.langchain.com/en/stable/</loc>
|
||||
|
||||
|
||||
<lastmod>2023-05-04T16:15:31.377584+00:00</lastmod>
|
||||
|
||||
<changefreq>weekly</changefreq>
|
||||
<priority>1</priority>
|
||||
</url>
|
||||
|
||||
<url>
|
||||
<loc>https://python.langchain.com/en/latest/</loc>
|
||||
|
||||
|
||||
<lastmod>2023-05-05T07:52:19.633878+00:00</lastmod>
|
||||
|
||||
<changefreq>daily</changefreq>
|
||||
<priority>0.9</priority>
|
||||
</url>
|
||||
|
||||
<url>
|
||||
<loc>https://python.langchain.com/en/harrison-docs-refactor-3-24/</loc>
|
||||
|
||||
|
||||
<lastmod>2023-03-27T02:32:55.132916+00:00</lastmod>
|
||||
|
||||
<changefreq>monthly</changefreq>
|
||||
<priority>0.8</priority>
|
||||
</url>
|
||||
|
||||
</urlset>
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
class MyClass {
|
||||
constructor(name) {
|
||||
this.name = name;
|
||||
}
|
||||
|
||||
greet() {
|
||||
console.log(`Hello, ${this.name}!`);
|
||||
}
|
||||
}
|
||||
|
||||
function main() {
|
||||
const name = prompt("Enter your name:");
|
||||
const obj = new MyClass(name);
|
||||
obj.greet();
|
||||
}
|
||||
|
||||
main();
|
||||
|
|
@ -1,16 +0,0 @@
|
|||
class MyClass:
|
||||
def __init__(self, name):
|
||||
self.name = name
|
||||
|
||||
def greet(self):
|
||||
print(f"Hello, {self.name}!")
|
||||
|
||||
|
||||
def main():
|
||||
name = input("Enter your name: ")
|
||||
obj = MyClass(name)
|
||||
obj.greet()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
|
@ -1,5 +0,0 @@
|
|||
Stanley Cups
|
||||
Team Location Stanley Cups
|
||||
Blues STL 1
|
||||
Flyers PHI 2
|
||||
Maple Leafs TOR 13
|
||||
|
Binary file not shown.
Some files were not shown because too many files have changed in this diff Show more
Loading…
Add table
Add a link
Reference in a new issue