mirror of
https://github.com/meta-llama/llama-stack.git
synced 2025-06-27 18:50:41 +00:00
# What does this PR do? - add notebooks - restructure docs ## Test Plan <img width="1201" alt="image" src="https://github.com/user-attachments/assets/3f9a09d9-b5ec-406c-b44b-e896e340d209" /> <img width="1202" alt="image" src="https://github.com/user-attachments/assets/fdc1173f-2417-4ad6-845e-4f265fc40a31" /> <img width="1201" alt="image" src="https://github.com/user-attachments/assets/b1e4e2a8-acf6-4ef2-a2fc-00d26cf32359" /> ## Sources Please link relevant resources if necessary. ## Before submitting - [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case). - [ ] Ran pre-commit to handle lint / formatting issues. - [ ] Read the [contributor guideline](https://github.com/meta-llama/llama-stack/blob/main/CONTRIBUTING.md), Pull Request section? - [ ] Updated relevant documentation. - [ ] Wrote necessary unit or integration tests.
2.3 KiB
2.3 KiB
Evaluation Concepts
The Llama Stack Evaluation flow allows you to run evaluations on your GenAI application datasets or pre-registered benchmarks.
We introduce a set of APIs in Llama Stack for supporting running evaluations of LLM applications.
/datasetio+/datasetsAPI/scoring+/scoring_functionsAPI/eval+/eval_tasksAPI
This guide goes over the sets of APIs and developer experience flow of using Llama Stack to run evaluations for different use cases. Checkout our Colab notebook on working examples with evaluations here.
Evaluation Concepts
The Evaluation APIs are associated with a set of Resources as shown in the following diagram. Please visit the Resources section in our Core Concepts guide for better high-level understanding.
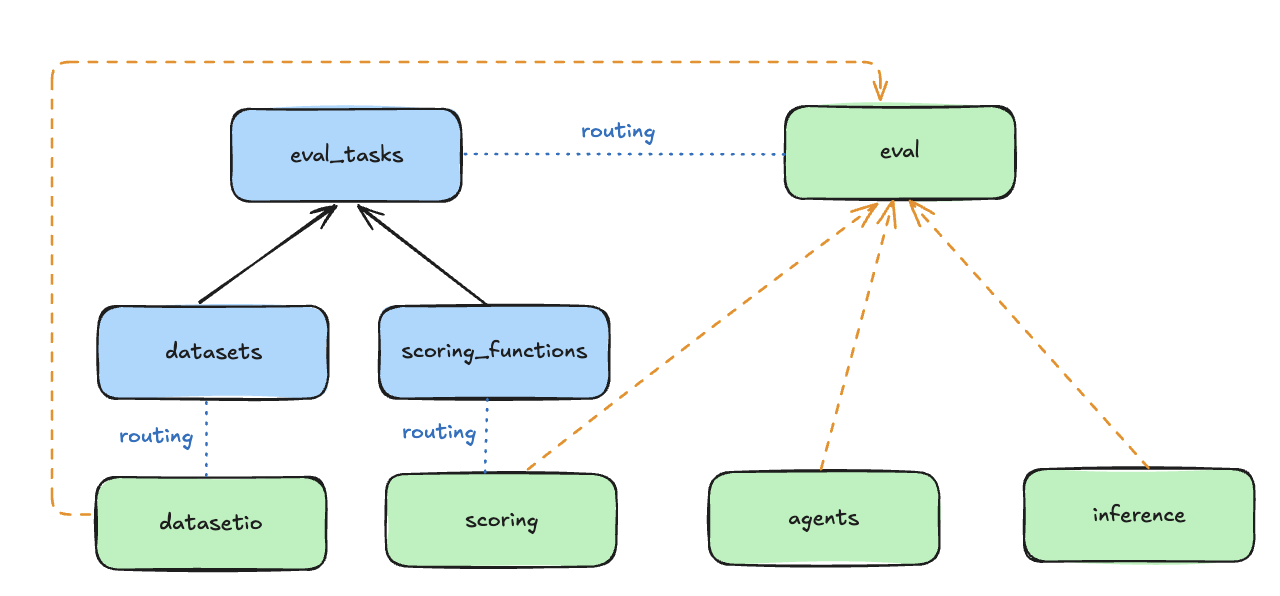
- DatasetIO: defines interface with datasets and data loaders.
- Associated with
Datasetresource.
- Associated with
- Scoring: evaluate outputs of the system.
- Associated with
ScoringFunctionresource. We provide a suite of out-of-the box scoring functions and also the ability for you to add custom evaluators. These scoring functions are the core part of defining an evaluation task to output evaluation metrics.
- Associated with
- Eval: generate outputs (via Inference or Agents) and perform scoring.
- Associated with
EvalTaskresource.
- Associated with
Use the following decision tree to decide how to use LlamaStack Evaluation flow.
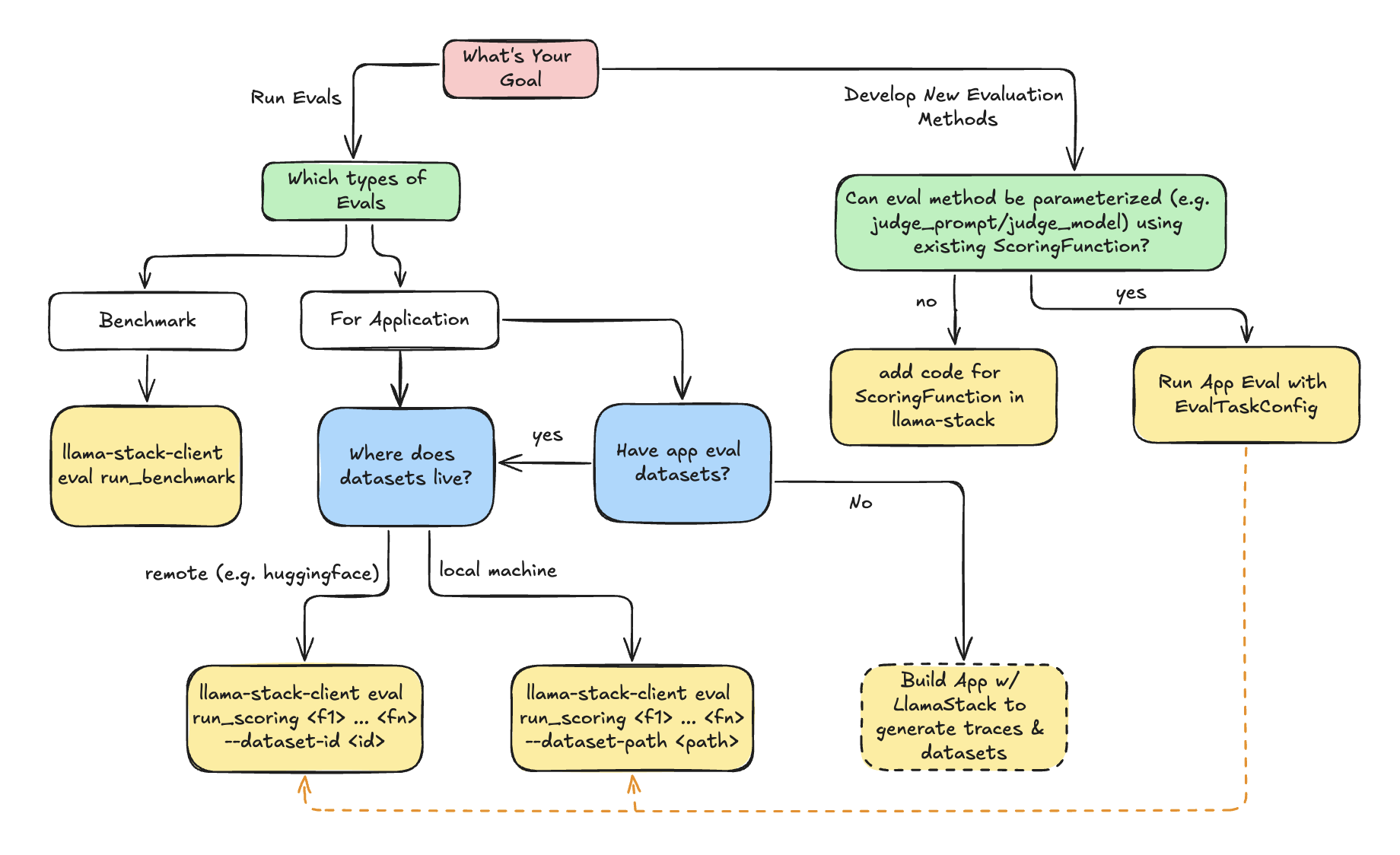
:class: tip
- **Benchmark Evaluation** is a well-defined eval-task consisting of `dataset` and `scoring_function`. The generation (inference or agent) will be done as part of evaluation.
- **Application Evaluation** assumes users already have app inputs & generated outputs. Evaluation will purely focus on scoring the generated outputs via scoring functions (e.g. LLM-as-judge).
What's Next?
- Check out our Colab notebook on working examples with evaluations here.
- Check out our Evaluation Reference for more details on the APIs.