# What does this PR do?
Cleans up how we provide sampling params. Earlier, strategy was an enum
and all params (top_p, temperature, top_k) across all strategies were
grouped. We now have a strategy union object with each strategy (greedy,
top_p, top_k) having its corresponding params.
Earlier,
```
class SamplingParams:
strategy: enum ()
top_p, temperature, top_k and other params
```
However, the `strategy` field was not being used in any providers making
it confusing to know the exact sampling behavior purely based on the
params since you could pass temperature, top_p, top_k and how the
provider would interpret those would not be clear.
Hence we introduced -- a union where the strategy and relevant params
are all clubbed together to avoid this confusion.
Have updated all providers, tests, notebooks, readme and otehr places
where sampling params was being used to use the new format.
## Test Plan
`pytest llama_stack/providers/tests/inference/groq/test_groq_utils.py`
// inference on ollama, fireworks and together
`with-proxy pytest -v -s -k "ollama"
--inference-model="meta-llama/Llama-3.1-8B-Instruct"
llama_stack/providers/tests/inference/test_text_inference.py `
// agents on fireworks
`pytest -v -s -k 'fireworks and create_agent'
--inference-model="meta-llama/Llama-3.1-8B-Instruct"
llama_stack/providers/tests/agents/test_agents.py
--safety-shield="meta-llama/Llama-Guard-3-8B"`
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the
other checks if that's the case).
- [X] Ran pre-commit to handle lint / formatting issues.
- [X] Read the [contributor
guideline](https://github.com/meta-llama/llama-stack/blob/main/CONTRIBUTING.md),
Pull Request section?
- [X] Updated relevant documentation.
- [X] Wrote necessary unit or integration tests.
---------
Co-authored-by: Hardik Shah <hjshah@fb.com>
12 KiB
llama (server-side) CLI Reference
The llama CLI tool helps you setup and use the Llama Stack. It should be available on your path after installing the llama-stack package.
Installation
You have two ways to install Llama Stack:
-
Install as a package: You can install the repository directly from PyPI by running the following command:
pip install llama-stack -
Install from source: If you prefer to install from the source code, follow these steps:
mkdir -p ~/local cd ~/local git clone git@github.com:meta-llama/llama-stack.git conda create -n myenv python=3.10 conda activate myenv cd llama-stack $CONDA_PREFIX/bin/pip install -e .
llama subcommands
download:llamacli tools supports downloading the model from Meta or Hugging Face.model: Lists available models and their properties.stack: Allows you to build and run a Llama Stack server. You can read more about this here.
Sample Usage
llama --help
usage: llama [-h] {download,model,stack} ...
Welcome to the Llama CLI
options:
-h, --help show this help message and exit
subcommands:
{download,model,stack}
Downloading models
You first need to have models downloaded locally.
To download any model you need the Model Descriptor. This can be obtained by running the command
llama model list
You should see a table like this:
+----------------------------------+------------------------------------------+----------------+
| Model Descriptor | Hugging Face Repo | Context Length |
+----------------------------------+------------------------------------------+----------------+
| Llama3.1-8B | meta-llama/Llama-3.1-8B | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.1-70B | meta-llama/Llama-3.1-70B | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.1-405B:bf16-mp8 | meta-llama/Llama-3.1-405B | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.1-405B | meta-llama/Llama-3.1-405B-FP8 | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.1-405B:bf16-mp16 | meta-llama/Llama-3.1-405B | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.1-8B-Instruct | meta-llama/Llama-3.1-8B-Instruct | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.1-70B-Instruct | meta-llama/Llama-3.1-70B-Instruct | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.1-405B-Instruct:bf16-mp8 | meta-llama/Llama-3.1-405B-Instruct | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.1-405B-Instruct | meta-llama/Llama-3.1-405B-Instruct-FP8 | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.1-405B-Instruct:bf16-mp16 | meta-llama/Llama-3.1-405B-Instruct | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.2-1B | meta-llama/Llama-3.2-1B | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.2-3B | meta-llama/Llama-3.2-3B | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.2-11B-Vision | meta-llama/Llama-3.2-11B-Vision | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.2-90B-Vision | meta-llama/Llama-3.2-90B-Vision | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.2-1B-Instruct | meta-llama/Llama-3.2-1B-Instruct | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.2-3B-Instruct | meta-llama/Llama-3.2-3B-Instruct | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.2-11B-Vision-Instruct | meta-llama/Llama-3.2-11B-Vision-Instruct | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama3.2-90B-Vision-Instruct | meta-llama/Llama-3.2-90B-Vision-Instruct | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama-Guard-3-11B-Vision | meta-llama/Llama-Guard-3-11B-Vision | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama-Guard-3-1B:int4-mp1 | meta-llama/Llama-Guard-3-1B-INT4 | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama-Guard-3-1B | meta-llama/Llama-Guard-3-1B | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama-Guard-3-8B | meta-llama/Llama-Guard-3-8B | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama-Guard-3-8B:int8-mp1 | meta-llama/Llama-Guard-3-8B-INT8 | 128K |
+----------------------------------+------------------------------------------+----------------+
| Prompt-Guard-86M | meta-llama/Prompt-Guard-86M | 128K |
+----------------------------------+------------------------------------------+----------------+
| Llama-Guard-2-8B | meta-llama/Llama-Guard-2-8B | 4K |
+----------------------------------+------------------------------------------+----------------+
To download models, you can use the llama download command.
Downloading from Meta
Here is an example download command to get the 3B-Instruct/11B-Vision-Instruct model. You will need META_URL which can be obtained from here
Download the required checkpoints using the following commands:
# download the 8B model, this can be run on a single GPU
llama download --source meta --model-id Llama3.2-3B-Instruct --meta-url META_URL
# you can also get the 70B model, this will require 8 GPUs however
llama download --source meta --model-id Llama3.2-11B-Vision-Instruct --meta-url META_URL
# llama-agents have safety enabled by default. For this, you will need
# safety models -- Llama-Guard and Prompt-Guard
llama download --source meta --model-id Prompt-Guard-86M --meta-url META_URL
llama download --source meta --model-id Llama-Guard-3-1B --meta-url META_URL
Downloading from Hugging Face
Essentially, the same commands above work, just replace --source meta with --source huggingface.
llama download --source huggingface --model-id Llama3.1-8B-Instruct --hf-token <HF_TOKEN>
llama download --source huggingface --model-id Llama3.1-70B-Instruct --hf-token <HF_TOKEN>
llama download --source huggingface --model-id Llama-Guard-3-1B --ignore-patterns *original*
llama download --source huggingface --model-id Prompt-Guard-86M --ignore-patterns *original*
Important: Set your environment variable HF_TOKEN or pass in --hf-token to the command to validate your access. You can find your token at https://huggingface.co/settings/tokens.
Tip: Default for
llama downloadis to run with--ignore-patterns *.safetensorssince we use the.pthfiles in theoriginalfolder. For Llama Guard and Prompt Guard, however, we need safetensors. Hence, please run with--ignore-patterns originalso that safetensors are downloaded and.pthfiles are ignored.
Understand the models
The llama model command helps you explore the model’s interface.
download: Download the model from different sources. (meta, huggingface)list: Lists all the models available for download with hardware requirements to deploy the models.prompt-format: Show llama model message formats.describe: Describes all the properties of the model.
Sample Usage
llama model <subcommand> <options>
llama model --help
usage: llama model [-h] {download,list,prompt-format,describe} ...
Work with llama models
options:
-h, --help show this help message and exit
model_subcommands:
{download,list,prompt-format,describe}
You can use the describe command to know more about a model:
llama model describe -m Llama3.2-3B-Instruct
Describe
+-----------------------------+----------------------------------+
| Model | Llama3.2-3B-Instruct |
+-----------------------------+----------------------------------+
| Hugging Face ID | meta-llama/Llama-3.2-3B-Instruct |
+-----------------------------+----------------------------------+
| Description | Llama 3.2 3b instruct model |
+-----------------------------+----------------------------------+
| Context Length | 128K tokens |
+-----------------------------+----------------------------------+
| Weights format | bf16 |
+-----------------------------+----------------------------------+
| Model params.json | { |
| | "dim": 3072, |
| | "n_layers": 28, |
| | "n_heads": 24, |
| | "n_kv_heads": 8, |
| | "vocab_size": 128256, |
| | "ffn_dim_multiplier": 1.0, |
| | "multiple_of": 256, |
| | "norm_eps": 1e-05, |
| | "rope_theta": 500000.0, |
| | "use_scaled_rope": true |
| | } |
+-----------------------------+----------------------------------+
| Recommended sampling params | { |
| | "temperature": 1.0, |
| | "top_p": 0.9, |
| | "top_k": 0 |
| | } |
+-----------------------------+----------------------------------+
Prompt Format
You can even run llama model prompt-format see all of the templates and their tokens:
llama model prompt-format -m Llama3.2-3B-Instruct
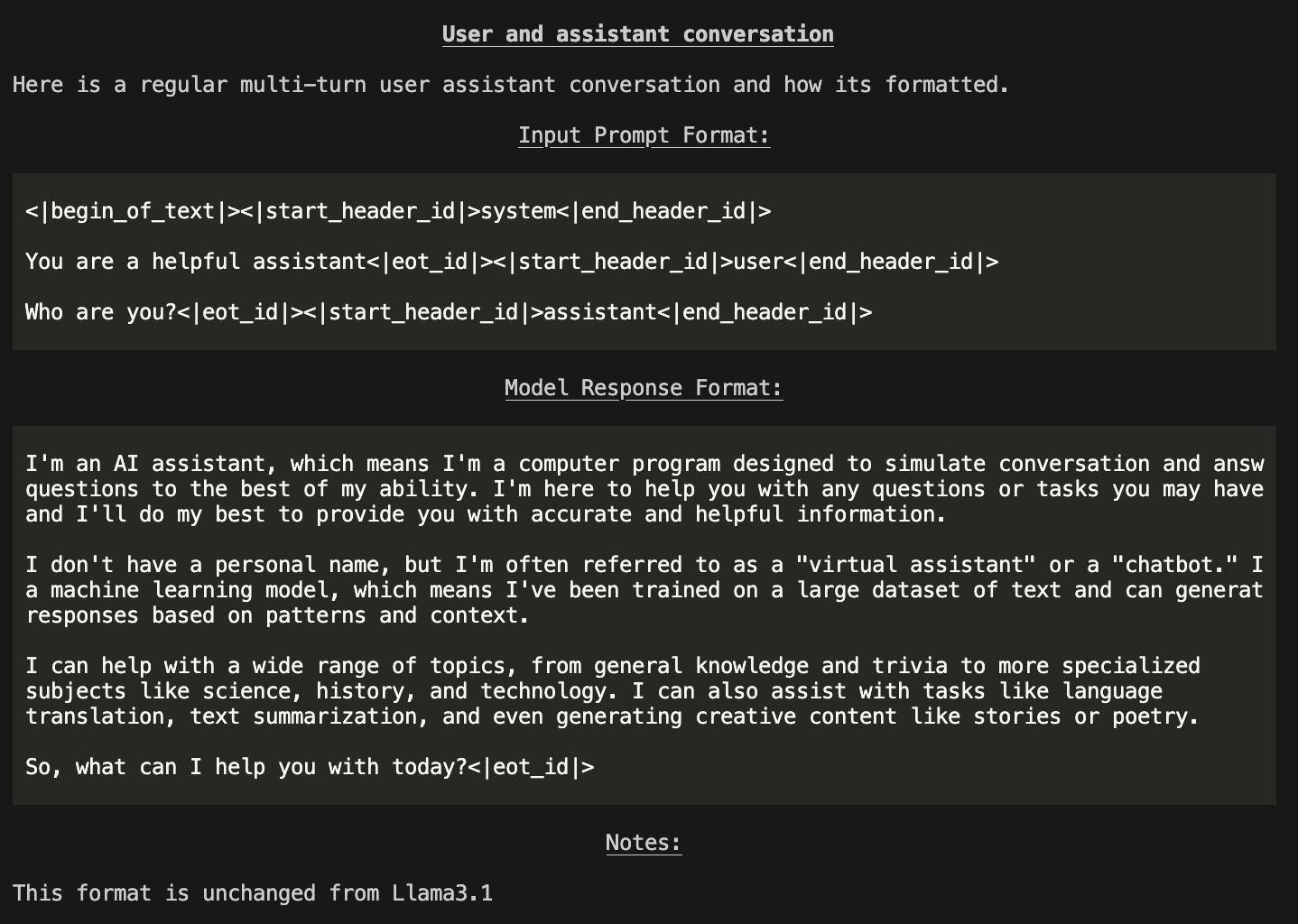
You will be shown a Markdown formatted description of the model interface and how prompts / messages are formatted for various scenarios.
NOTE: Outputs in terminal are color printed to show special tokens.