# What does this PR do? his PR allows users to customize the template used for chunks when inserted into the context. Additionally, this enables metadata injection into the context of an LLM for RAG. This makes a naive and crude assumption that each chunk should include the metadata, this is obviously redundant when multiple chunks are returned from the same document. In order to remove any sort of duplication of chunks, we'd have to make much more significant changes so this is a reasonable first step that unblocks users requesting this enhancement in https://github.com/meta-llama/llama-stack/issues/1767. In the future, this can be extended to support citations. List of Changes: - `llama_stack/apis/tools/rag_tool.py` - Added `chunk_template` field in `RAGQueryConfig`. - Added `field_validator` to validate the `chunk_template` field in `RAGQueryConfig`. - Ensured the `chunk_template` field includes placeholders `{index}` and `{chunk.content}`. - Updated the `query` method to use the `chunk_template` for formatting chunk text content. - `llama_stack/providers/inline/tool_runtime/rag/memory.py` - Modified the `insert` method to pass `doc.metadata` for chunk creation. - Enhanced the `query` method to format results using `chunk_template` and exclude unnecessary metadata fields like `token_count`. - `llama_stack/providers/utils/memory/vector_store.py` - Updated `make_overlapped_chunks` to include metadata serialization and token count for both content and metadata. - Added error handling for metadata serialization issues. - `pyproject.toml` - Added `pydantic.field_validator` as a recognized `classmethod` decorator in the linting configuration. - `tests/integration/tool_runtime/test_rag_tool.py` - Refactored test assertions to separate `assert_valid_chunk_response` and `assert_valid_text_response`. - Added integration tests to validate `chunk_template` functionality with and without metadata inclusion. - Included a test case to ensure `chunk_template` validation errors are raised appropriately. - `tests/unit/rag/test_vector_store.py` - Added unit tests for `make_overlapped_chunks`, verifying chunk creation with overlapping tokens and metadata integrity. - Added tests to handle metadata serialization errors, ensuring proper exception handling. - `docs/_static/llama-stack-spec.html` - Added a new `chunk_template` field of type `string` with a default template for formatting retrieved chunks in RAGQueryConfig. - Updated the `required` fields to include `chunk_template`. - `docs/_static/llama-stack-spec.yaml` - Introduced `chunk_template` field with a default value for RAGQueryConfig. - Updated the required configuration list to include `chunk_template`. - `docs/source/building_applications/rag.md` - Documented the `chunk_template` configuration, explaining how to customize metadata formatting in RAG queries. - Added examples demonstrating the usage of the `chunk_template` field in RAG tool queries. - Highlighted default values for `RAG` agent configurations. # Resolves https://github.com/meta-llama/llama-stack/issues/1767 ## Test Plan Updated both `test_vector_store.py` and `test_rag_tool.py` and tested end-to-end with a script. I also tested the quickstart to enable this and specified this metadata: ```python document = RAGDocument( document_id="document_1", content=source, mime_type="text/html", metadata={"author": "Paul Graham", "title": "How to do great work"}, ) ``` Which produced the output below:  This highlights the usefulness of the additional metadata. Notice how the metadata is redundant for different chunks of the same document. I think we can update that in a subsequent PR. # Documentation I've added a brief comment about this in the documentation to outline this to users and updated the API documentation. --------- Signed-off-by: Francisco Javier Arceo <farceo@redhat.com>
7.4 KiB
Retrieval Augmented Generation (RAG)
RAG enables your applications to reference and recall information from previous interactions or external documents.
Llama Stack organizes the APIs that enable RAG into three layers:
- The lowermost APIs deal with raw storage and retrieval. These include Vector IO, KeyValue IO (coming soon) and Relational IO (also coming soon.).
- The next is the "Rag Tool", a first-class tool as part of the Tools API that allows you to ingest documents (from URLs, files, etc) with various chunking strategies and query them smartly.
- Finally, it all comes together with the top-level "Agents" API that allows you to create agents that can use the tools to answer questions, perform tasks, and more.
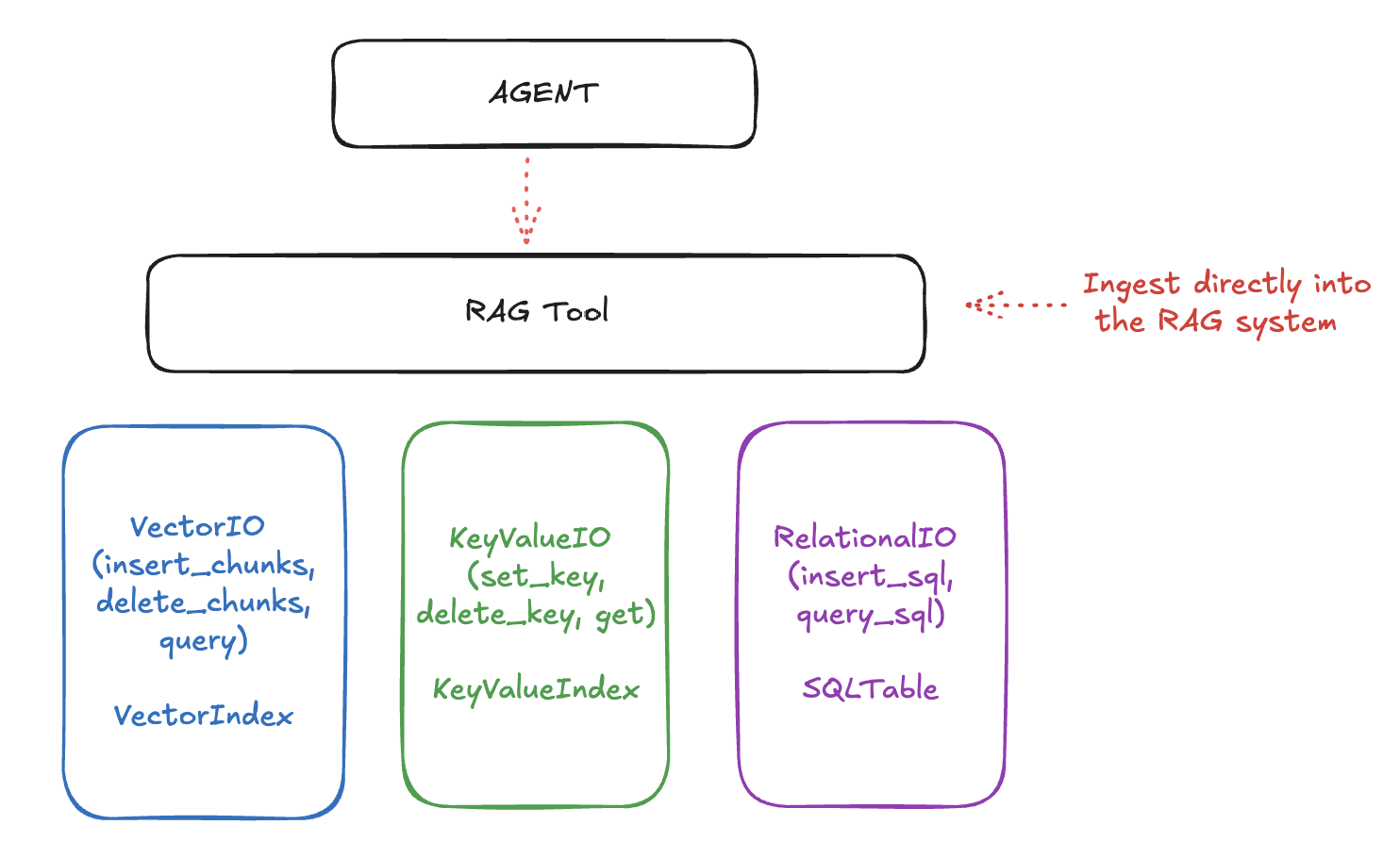
The RAG system uses lower-level storage for different types of data:
- Vector IO: For semantic search and retrieval
- Key-Value and Relational IO: For structured data storage
We may add more storage types like Graph IO in the future.
Setting up Vector DBs
For this guide, we will use Ollama as the inference provider. Ollama is an LLM runtime that allows you to run Llama models locally.
Here's how to set up a vector database for RAG:
# Create http client
import os
from llama_stack_client import LlamaStackClient
client = LlamaStackClient(base_url=f"http://localhost:{os.environ['LLAMA_STACK_PORT']}")
# Register a vector db
vector_db_id = "my_documents"
response = client.vector_dbs.register(
vector_db_id=vector_db_id,
embedding_model="all-MiniLM-L6-v2",
embedding_dimension=384,
provider_id="faiss",
)
Ingesting Documents
You can ingest documents into the vector database using two methods: directly inserting pre-chunked documents or using the RAG Tool.
# You can insert a pre-chunked document directly into the vector db
chunks = [
{
"content": "Your document text here",
"mime_type": "text/plain",
"metadata": {
"document_id": "doc1",
"author": "Jane Doe",
},
},
]
client.vector_io.insert(vector_db_id=vector_db_id, chunks=chunks)
Retrieval
You can query the vector database to retrieve documents based on their embeddings.
# You can then query for these chunks
chunks_response = client.vector_io.query(
vector_db_id=vector_db_id, query="What do you know about..."
)
Using the RAG Tool
A better way to ingest documents is to use the RAG Tool. This tool allows you to ingest documents from URLs, files, etc. and automatically chunks them into smaller pieces. More examples for how to format a RAGDocument can be found in the appendix.
from llama_stack_client import RAGDocument
urls = ["memory_optimizations.rst", "chat.rst", "llama3.rst"]
documents = [
RAGDocument(
document_id=f"num-{i}",
content=f"https://raw.githubusercontent.com/pytorch/torchtune/main/docs/source/tutorials/{url}",
mime_type="text/plain",
metadata={},
)
for i, url in enumerate(urls)
]
client.tool_runtime.rag_tool.insert(
documents=documents,
vector_db_id=vector_db_id,
chunk_size_in_tokens=512,
)
# Query documents
results = client.tool_runtime.rag_tool.query(
vector_db_ids=[vector_db_id],
content="What do you know about...",
)
You can configure how the RAG tool adds metadata to the context if you find it useful for your application. Simply add:
# Query documents
results = client.tool_runtime.rag_tool.query(
vector_db_ids=[vector_db_id],
content="What do you know about...",
query_config={
"chunk_template": "Result {index}\nContent: {chunk.content}\nMetadata: {metadata}\n",
},
)
Building RAG-Enhanced Agents
One of the most powerful patterns is combining agents with RAG capabilities. Here's a complete example:
from llama_stack_client import Agent
# Create agent with memory
agent = Agent(
client,
model="meta-llama/Llama-3.3-70B-Instruct",
instructions="You are a helpful assistant",
tools=[
{
"name": "builtin::rag/knowledge_search",
"args": {
"vector_db_ids": [vector_db_id],
# Defaults
"query_config": {
"chunk_size_in_tokens": 512,
"chunk_overlap_in_tokens": 0,
"chunk_template": "Result {index}\nContent: {chunk.content}\nMetadata: {metadata}\n",
},
},
}
],
)
session_id = agent.create_session("rag_session")
# Ask questions about documents in the vector db, and the agent will query the db to answer the question.
response = agent.create_turn(
messages=[{"role": "user", "content": "How to optimize memory in PyTorch?"}],
session_id=session_id,
)
NOTE: the
instructionsfield in theAgentConfigcan be used to guide the agent's behavior. It is important to experiment with different instructions to see what works best for your use case.
You can also pass documents along with the user's message and ask questions about them.
# Initial document ingestion
response = agent.create_turn(
messages=[
{"role": "user", "content": "I am providing some documents for reference."}
],
documents=[
{
"content": "https://raw.githubusercontent.com/pytorch/torchtune/main/docs/source/tutorials/memory_optimizations.rst",
"mime_type": "text/plain",
}
],
session_id=session_id,
)
# Query with RAG
response = agent.create_turn(
messages=[{"role": "user", "content": "What are the key topics in the documents?"}],
session_id=session_id,
)
You can print the response with below.
from llama_stack_client import AgentEventLogger
for log in AgentEventLogger().log(response):
log.print()
Unregistering Vector DBs
If you need to clean up and unregister vector databases, you can do so as follows:
# Unregister a specified vector database
vector_db_id = "my_vector_db_id"
print(f"Unregistering vector database: {vector_db_id}")
client.vector_dbs.unregister(vector_db_id=vector_db_id)
# Unregister all vector databases
for vector_db_id in client.vector_dbs.list():
print(f"Unregistering vector database: {vector_db_id.identifier}")
client.vector_dbs.unregister(vector_db_id=vector_db_id.identifier)
Appendix
More RAGDocument Examples
from llama_stack_client import RAGDocument
import base64
RAGDocument(document_id="num-0", content={"uri": "file://path/to/file"})
RAGDocument(document_id="num-1", content="plain text")
RAGDocument(
document_id="num-2",
content={
"type": "text",
"text": "plain text input",
}, # for inputs that should be treated as text explicitly
)
RAGDocument(
document_id="num-3",
content={
"type": "image",
"image": {"url": {"uri": "https://mywebsite.com/image.jpg"}},
},
)
B64_ENCODED_IMAGE = base64.b64encode(
requests.get(
"https://raw.githubusercontent.com/meta-llama/llama-stack/refs/heads/main/docs/_static/llama-stack.png"
).content
)
RAGDocuemnt(
document_id="num-4",
content={"type": "image", "image": {"data": B64_ENCODED_IMAGE}},
)
for more strongly typed interaction use the typed dicts found here.